kubernetes: kube-proxy ipvs mode does not update service endpoint ip when node fail
What happened:
when one master power off, kube-proxy on another master does not update the svc endpoint ip.for example. before the master power off , the ipvs rule for servcie (nodeport is 32001)
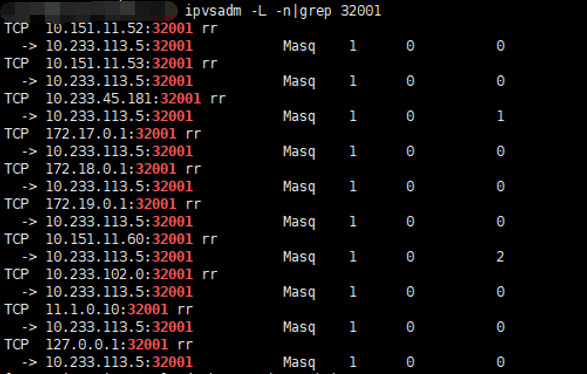
after the master poweroff,the pod on this master migrate to another master,but the ipvs rule does not change. still use the pod ip 10.233.113.5, then i restart the kube-proxy on this node ,then the ipvs rules were updated
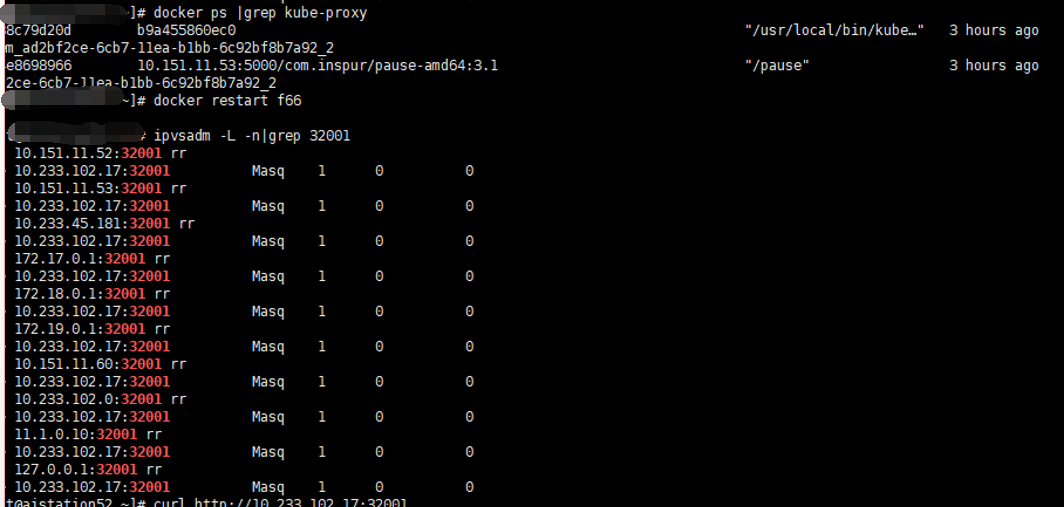
What you expected to happen: the ipvs rule should be updated when the pod migrate succeed How to reproduce it (as minimally and precisely as possible): the k8s cluster has 3 master and 1 node , one pod running on master1 ,and we poweroff master1 Anything else we need to know?: 3 master use haproxy as loadbancer , all kubelet compent, scheduler、apiserver、controller-manager use this haproxy to connect with apiserver Environment:
- Kubernetes version (use
kubectl version): 1.14.8 - Cloud provider or hardware configuration:
- OS (e.g:
cat /etc/os-release): centos 7.5 - Kernel (e.g.
uname -a): 3.10.0-862.el7.x86_64 - Install tools:
- Network plugin and version (if this is a network-related bug): calico
- Others:
About this issue
- Original URL
- State: closed
- Created 4 years ago
- Reactions: 1
- Comments: 38 (24 by maintainers)
We finally reproduced our problem, this issue seems from some mis-configuration of haproxy. And I summarize below:
In this case, we have incorrect ipvs rule of calico-typha service.
Firstly, we check the endpoint (It’s correct, 192.168.18.122 is new node after pod migrate done):
but in ipvs, the rules are still with old endpoint address (192.168.18.123 already powered off):
then we check the verbose log of kube-proxy, we could see kube-proxy was updating endpoint after endpoint changing, but update with the old ip address.
We have noticed the connection between kube-proxy <-> apiserver(proxy by haproxy) are established for a long time. As we using keepalived + haproxy for apiserver’s LB, then we check the connection between haproxy <-> apiserver:
actually the node: 192.168.18.123 is already powered off for a long time. That is to say there is a established connection: kube-proxy … haproxy … apiserver (powered off). And kube-proxy and haproxy could not aware of that apiserver is already down.
We could simply recover the ipvs rules by restart kube-proxy, or just restart haproxy.
Finally, we try to fix the problem by change haproxy’s configuration, see below diff, it works.
And this also explains that the problem I described earlier also happened in iptables mode 😃
@davidstack I’m not sure if your problem are also related to haproxy. Could you share or check your haproxy’s configuration?
Since this may be a problem when the master goes down and
kube-proxyfails to re-connect I will try to setup a multi-master cluster. But it may take some time.@fearlesschenc yes, the kube-proxy on alive node will update the ipvs rules. but in my issue, when master power off,the kube-proxy on other alive node do not update the ipvs rules