kubernetes: [Flake] pull-kubernetes-e2e-kind timeouts and flake
Which jobs are flaking?
pull-kubernetes-e2e-kind
Which tests are flaking?
[sig-storage] CSI .*
Since when has it been flaking?
It seems that happens since 7/8 https://storage.googleapis.com/k8s-triage/index.html?ci=0&pr=1&job=pull-kubernetes-e2e-kind
Testgrid link
Reason for failure (if possible)
The test timeout
{"component":"entrypoint","file":"k8s.io/test-infra/prow/entrypoint/run.go:165","func":"k8s.io/test-infra/prow/entrypoint.Options.ExecuteProcess","level":"error","msg":"Process did not finish before 1h0m0s timeout","severity":"error","time":"2022-07-12T02:09:15Z"}
wrapper.sh] [EARLY EXIT] Interrupted, entering handler ...
+ wrapper.sh] [CLEANUP] Cleaning up after Docker in Docker ...
signal_handler
the docker daemon is killed, but the e2e.test process keeps running, but it fails to do anything because all the docker features are missing, in this case, the port forwarding from the host to the apiserver container, as we can see in the following log entry
Jul 12 02:09:16.895: FAIL: All nodes should be ready after test, Get "https://127.0.0.1:33619/api/v1/nodes": dial tcp 127.0.0.1:33619: connect: connection refused
As consequence, all kind commands fail, like the ones that gather the logs or clean up the environment
Deleting cluster "kind" ...
ERROR: failed to delete cluster "kind": error listing nodes: failed to list nodes: command "docker ps -a --filter label=io.x-k8s.kind.cluster=kind --format '{{.Names}}'" failed with error: exit status 1
Command Output: Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
Anything else we need to know?
The sig storage test take more than 10 minutes
we shouldn’t have test with that duration on presubmit, those also should be tagged as slow
~The trigger may be related to the ginkgo v2 update, the failures start to happen the same day that merged~
Relevant SIG(s)
/sig testing /sig storage
About this issue
- Original URL
- State: closed
- Created 2 years ago
- Comments: 46 (46 by maintainers)
Commits related to this issue
- e2e: Remove ginkgo option `output-interceptor-mode` Set intercept mode to none will help to reveal more information when the test hangs, - https://github.com/onsi/ginkgo/issues/970 or circumvent cas... — committed to chendave/kubernetes by chendave 2 years ago
- e2e: Remove ginkgo option `output-interceptor-mode` Set intercept mode to none will help to reveal more information when the test hangs, - https://github.com/onsi/ginkgo/issues/970 or circumvent cas... — committed to jaehnri/kubernetes by chendave 2 years ago
no failures since the offending test was reverted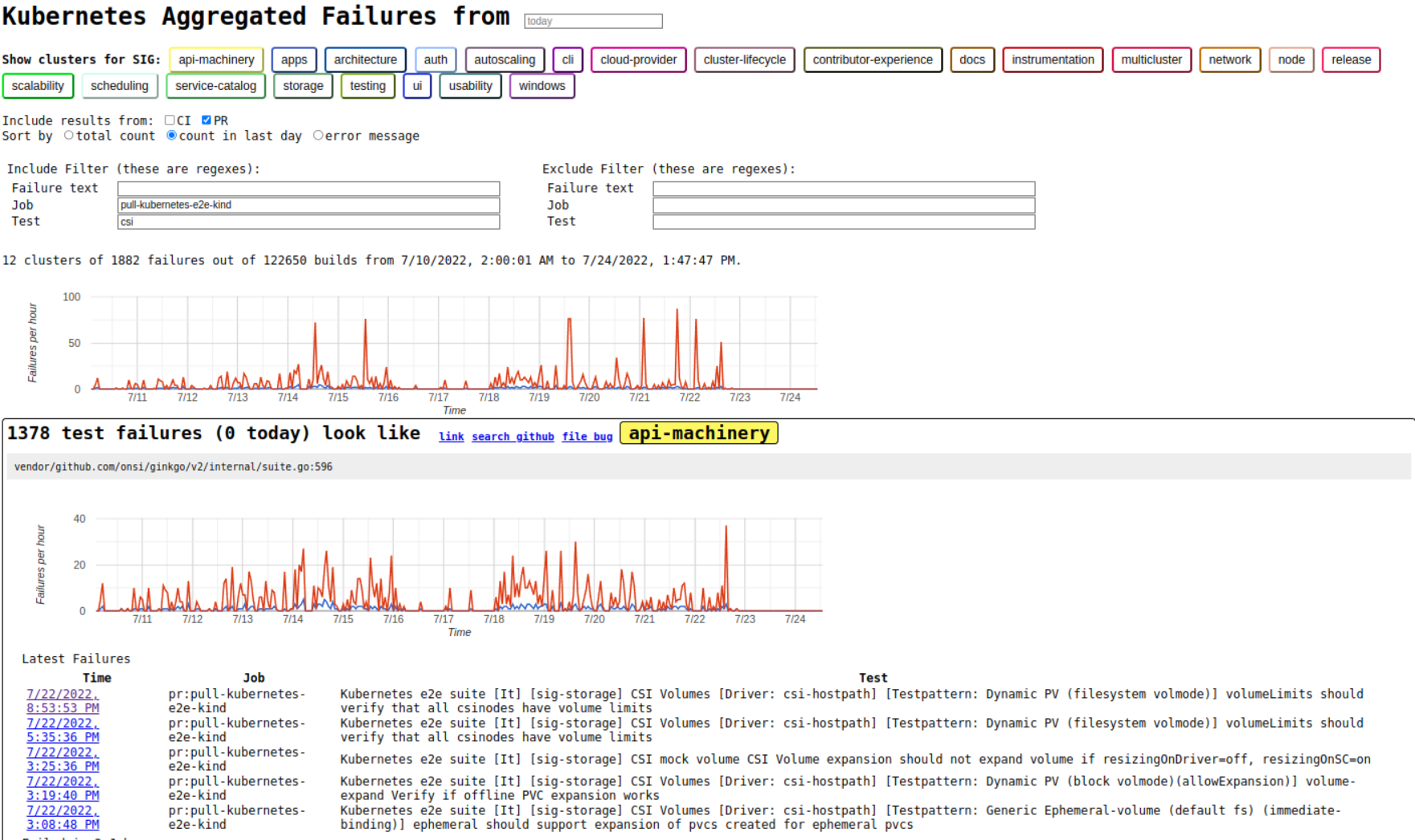
confirming msau theory
For example from my test run above, this is where the control plane logs are: https://gcsweb.k8s.io/gcs/kubernetes-jenkins/pr-logs/pull/111334/pull-kubernetes-e2e-gce-ubuntu-containerd/1550310687912235008/artifacts/e2e-c189956e22-a7d53-master/
It would be nice to collect this from the kind jobs too.
I think I found the root cause. I did some debugging on my own PR, and debugged the GCE run because the kind run does not capture kube-controller-manager logs: https://prow.k8s.io/view/gs/kubernetes-jenkins/pr-logs/pull/111334/pull-kubernetes-e2e-gce-ubuntu-containerd/1550310687912235008/
test log:
kube-controller-manager.log:
The commit that I thought wasn’t suspicious is actually suspicious: https://github.com/kubernetes/kubernetes/pull/110237
cc @Riaankl @smarterclayton please help take a look. I think the new tests are disruptive and causing namespace deletion in other tests to fail.
I think next step is to try to locally rerun the tests against the good commit and the two commits after the good run to see if we can rule them out.
not really:
Looking at CI jobs: Here’s the first job where tests started taking 10 mins: https://prow.k8s.io/view/gs/kubernetes-jenkins/logs/ci-kubernetes-kind-e2e-parallel/1544925610889973760 The run before that was fine: https://prow.k8s.io/view/gs/kubernetes-jenkins/logs/ci-kubernetes-kind-e2e-parallel/1544910511240384512
hey @aojea – looking at just that last run I’m seeing:
13:18 is the first timestamp I see.
Eventually (~around 13:35) the specs start running.
Everything is happy and several hundred specs run in parallel and pass. The last three specs then fail - these three are running in parallel.
The first spec is:
[sig-storage] CSI Volumes [Driver: csi-hostpath] [Testpattern: Dynamic PV (block volmode)(allowExpansion)] volume-expand [AfterEach] should resize volume when PVC is edited while pod is using it test/e2e/storage/testsuites/volume_expand.go:252and has an error trying to delete the test namespace:
The line of code that attempts this delete seems to wrap it in a try and so this timeout/failure doesn’t mark the spec as failed. The storage specific cleanup keeps running…
This stuff:
appears to succeed - but then this step:
seems to hang. Eventually, at 14:18:32 I see:
and the first spec now reports the following error:
Presumably after three minutes of polling the namespace hasn’t been removed. But now that the outer container/infrastructure has timed out the tcp connection attempting to continue polling fails. It looks like that 1 hour timeout is governed by the test setup, nto the Ginkgo test suite.
With the container/infrasturcture gone, the spec reports the error “
failed to list events in namespaces "volume-expand-8232"”.but this too is wrapped in a try. The spec finally fails in the
framework.goAfterEachwith:again, because the container/infrasturcture was killed at 14:18:32. This failure now bubbles up as the failure associated with the spec.
But in reality the underlying issue seems to be a failure to delete the
volume-expand-8232namespace.The second spec is:
[sig-storage] CSI Volumes [Driver: csi-hostpath] [Testpattern: CSI Ephemeral-volume (default fs)] ephemeral [AfterEach] should create read-only inline ephemeral volume test/e2e/storage/testsuites/ephemeral.go:175Here too we see:
^ this appears to be the actual failure. Eventually the
AfterEachreports aconnection refusedfailure at 14:18 after the container/infrastructure times out.Finally, the third spec is:
[sig-storage] CSI mock volume [AfterEach] Delegate FSGroup to CSI driver [LinuxOnly] should not pass FSGroup to CSI driver if it is set in pod and driver supports VOLUME_MOUNT_GROUP test/e2e/storage/csi_mock_volume.go:1735here, once again, we see
^ this appears to be the actual failure. As with the other specs, eventually the
AfterEachreports aconnection refusedfailure at 14:18 after the container/infrastructure times out.So, it looks like something happens around 14:08 that puts the cluster in a bad state and these volume-related namespaces time out trying to delete. This pushes the run time for the entire suite (including the setup bits before Ginkgo runs) past the 1 hour limit imposed by the container/infrastructure layer.
I’m not sure this is a V1 vs V2 issue (perhaps some previously implicit behavior aroudn test ordering has changed - but these parallel specs basically run the same way in V1 as in V2). Have there been any changes to the storage stuff introduced around the same time as the V2 upgrade? Perhaps this is an infrastructure resource/exhaustion issue - 700 specs managed to succeed before these last three failed!