kubernetes: ContainerGCFailed / ImageGCFailed context deadline exceeded
A user reported seeing these in their kubectl describe nodes output
1d 40m 894 {kubelet ip-172-20-120-149.eu-west-1.compute.internal} Warning ContainerGCFailed operation timeout: context deadline exceeded
3h 39m 24 {kubelet ip-172-20-120-149.eu-west-1.compute.internal} Warning ImageGCFailed operation timeout: context deadline exceeded
Along with some of these errors in the kubelet:
Feb 27 13:37:32 ip-172-20-120-149 kubelet[1548]: I0227 13:37:32.158919 1548 fsHandler.go:131] du and find on following dirs took 4.380398297s: [/var/lib/docker/overlay/0ed1ae2108a2bab46fbcd4f07d9aefa90
Feb 27 13:37:32 ip-172-20-120-149 kubelet[1548]: I0227 13:37:32.160414 1548 fsHandler.go:131] du and find on following dirs took 4.398187772s: [/var/lib/docker/overlay/527b08719c6c372acb23bccef801542f6
Feb 27 13:37:32 ip-172-20-120-149 kubelet[1548]: I0227 13:37:32.157624 1548 fsHandler.go:131] du and find on following dirs took 4.395390593s: [/var/lib/docker/overlay/583b7f32ed55ea2a133632c4612acc51b
About this issue
- Original URL
- State: closed
- Created 7 years ago
- Reactions: 17
- Comments: 56 (13 by maintainers)
I’ve encountered this issue when testing pod eviction policies. Whenever my evictions thresholds are too close to the node physical memory limits I get issues.
I see ContainerGCFailed when I describe the node and when I connect to the node docker ps doesn’t respond. I have to restart the docker service to recover.
I’m still experiencing this with Kubernetes 1.17 and container runtime version: docker://19.3.6 Also, when this happens, the description of the affected node shows, under Conditions:
We had the following symptoms : docker ps nonresponsive, this error reported in node status and workloads not serviing responses, and a restart of docker restored service. We also noted the same EBS volume burst IO pinning at 0 and the associated ongoing IO.
Here is the cloudwatch stats for a few days leading up to the failure and the failure itself (the 11 hours to the right side of the graph). Note the sustained queue length of exactly 4 during the failure as well as the sustained bottlenecked read and write load.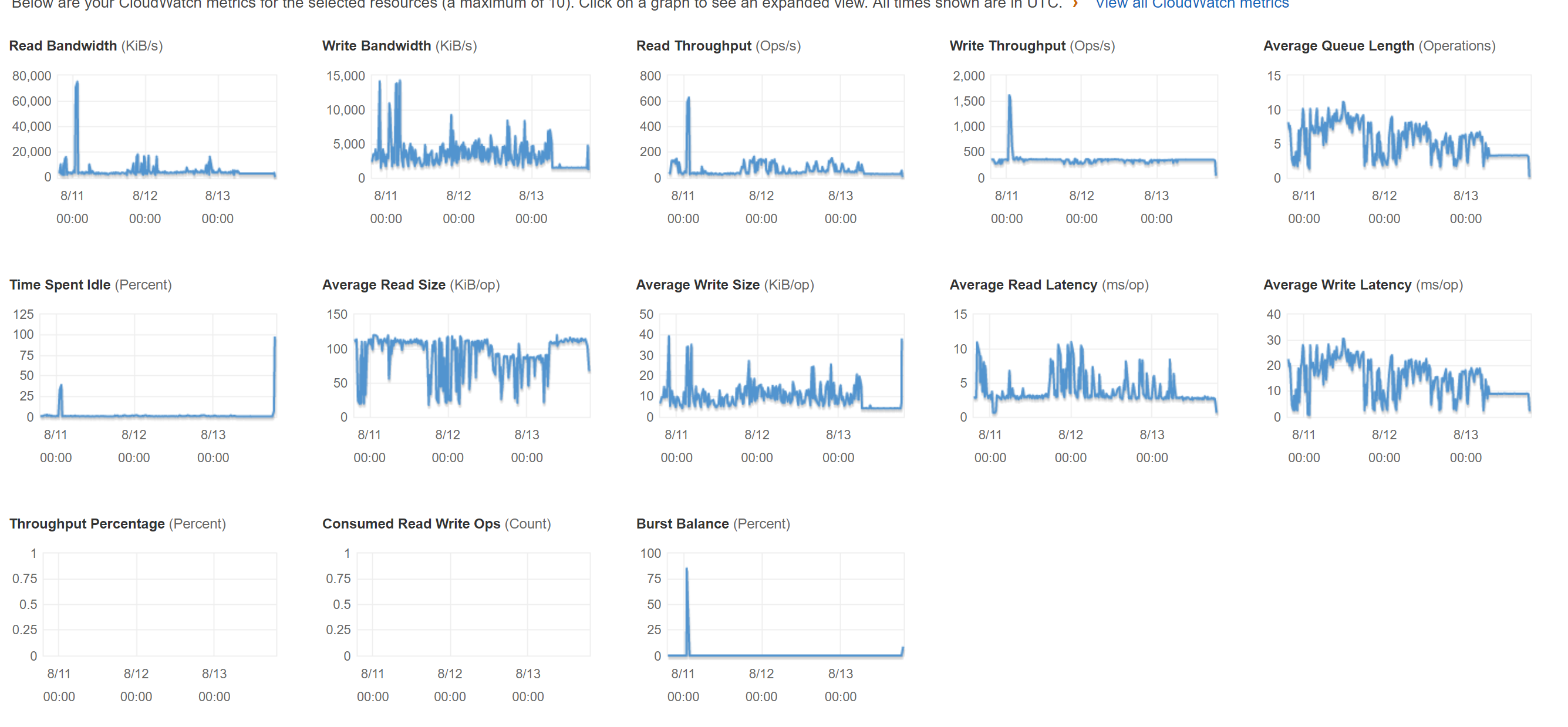
We experienced this issue as well on kubernetes 1.6.2, running Container Linux (CoreOS).
I definitely agree that this is a docker bottleneck as testarting docker brought the node back to life for us:
seeing the same on 1.6.0, cluster created using kops on AWS.
Hi, we solved the problem using resources management: memory & cpu requests.
The orchestrator was missing good informations to select good nodes to run pods. This was resulting in nodes with heavy loads.
Now, the pods are running more effectively on all nodes of the cluster and everything is fine. So take a look at cpu & memory usage of your pods.
I’m seeing this quite a bit on 1.6.3 across almost all my nodes.
To add another data point, we’re also seeing the
ContainerGCFailed operation timeout: context deadline exceededwhen the docker runtime seems to be struggling. In our case, the docker runtime slowdown is correlated to heavy IO on an EBS volume, we think. Details here https://github.com/kubernetes/kubernetes/issues/39028#issuecomment-284765798