ingress-nginx: liveness probe fails intermittently
Is this a BUG REPORT or FEATURE REQUEST? (choose one): bug report
NGINX Ingress controller version: nginx-ingress-0.25.1
Kubernetes version (use kubectl version): 1.1.0
Environment:
- Cloud provider or hardware configuration: aws eks 2
- OS (e.g. from /etc/os-release): amazon linux
- Kernel (e.g.
uname -a): .amzn2.x86_64 #1 SMP Mon May 21 23:43:11 UTC 2018 x86_64 GNU/Linux - Install tools:
- Others:
What happened:
my ingress-controllers randomly go into CrashLoopBackOff because the liveness probe fails/timeouts
What you expected to happen: The liveness probe not to fail
How to reproduce it (as minimally and precisely as possible): deploy nginx-ingress and observe the heartbeat sometimes taking too long to respond.
Anything else we need to know:
Alright, so randomly my ingress-controllers will start rebooting. I started with just 3 controllers to handle about 8k RPM and randomly the controllers will stop responding to liveness probes fast, and kube will restart them with “CrashLoopBackOff”. It seems totally random when the liveness probes will stop responding fast. To test, I just scaled up 20 ingress controllers to observe. Presently 4 of them are in this heartbeat not-responding state, and 16 of them are totally fine.
I have some ingress-controllers up that have been alive for 1hr+ with no restarts due to the heartbeat slowing down, but then some controllers have been alive for 25 minutes and have 34 restarts, some have 1, etc. It seems totally random which is why I am confused.
I also tried upping the timeout from 1 second to 10 in the yaml config for the ingress-controller, and this does cause them to enter “CrashLoopBackOff” but they still do enter it.
I SSH’d into some boxes and checked the heartbeat url myself. Sometimes it responds right away, sometimes it is abit slow, and for the ones in “CrashLoopBackOff” I get no response at all (but this makes sense since kube is rebooting them or in backoff).
About this issue
- Original URL
- State: closed
- Created 6 years ago
- Reactions: 2
- Comments: 27 (11 by maintainers)
Closing. Please update to 0.21.0. Reopen if the issue persists after the upgrade
In the mean time we found out that this tends to happen when the load on the node running the ingress controller suddenly increases: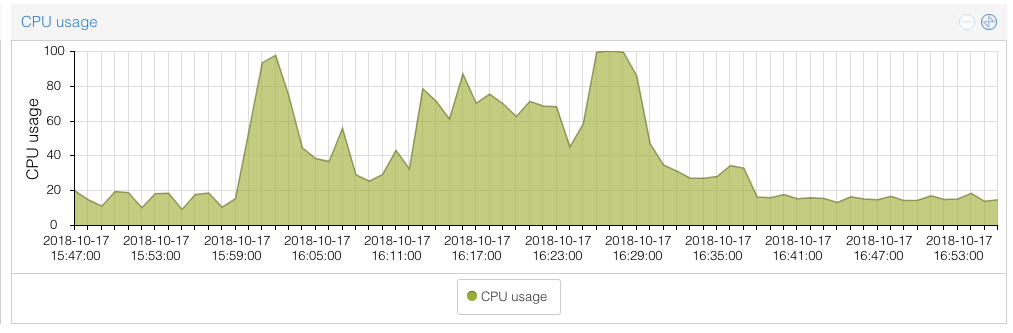
You can see right at 16:00 the CPU usage spiked hard. That is also exactly when the ingress controller became unhealthy and got restarted. So it sort of looks like a resource starvation issue on our side, though I wouldn’t have expected nginx to choke this hard.