serving: Autoscaler pod informer can't sync when the total pod info in the cluster is huge
Background
On the cluster where the knative runs, we launched a series big k8s job which created about 10k pod as the result. For each job pod, a huge environment variables are injected, so that the pod medata size is big ==> etcd size is about 2G.
During the job pods generating, given there is a pod informer works in autoscaler, we noticed the memory of autoscaler increased, but not as much as 2G.
Then, autoscaler hit the problem reported in https://github.com/knative/serving/pull/9794, so it got panic and restarted.
When the restart in progress , the pod informer lister tried to load all the pods, including the 10k job pods, into the memory, so it’s memory increased high enough to 2.5Gb (we set memory.limit of autoscaler pod to 3Gi already) , and it took longer to sync pod informer cache, and got below error
ov 11 14:34:09 autoscaler-568b99d-hgbgm autoscaler fatal {"level":"fatal","ts":"2020-11-11T06:34:08.835Z","logger":"autoscaler","caller":"autoscaler/main.go:159","msg":"Failed to start informers","commit":"7202135","error":"failed to wait for cache at index 0 to sync","stacktrace":"main.main\n\tknative.dev/serving/cmd/autoscaler/main.go:159\nruntime.main\n\truntime/proc.go:203"}
Nov 11 14:34:09 autoscaler-568b99d-hgbgm autoscaler I1111 06:34:08.835874 1 trace.go:201] Trace[911902081]: "Reflector ListAndWatch" name:k8s.io/client-go@v11.0.1-0.20190805182717-6502b5e7b1b5+incompatible/tools/cache/reflector.go:105 (11-Nov-2020 06:33:00.002) (total time: 23833ms):
Also, the liveness probe failed to get a response with the default setting, so autoscaler kept crashloopbackoff.
Warning Unhealthy 14m (x82 over 175m) kubelet, 10.240.128.28 Readiness probe failed: Get http://172.30.50.160:8080/: dial tcp 172.30.50.160:8080: connect: connection refused
Warning Unhealthy 5m33s (x123 over 175m) kubelet, 10.240.128.28 Liveness probe failed: Get http://172.30.50.160:8080/: dial tcp 172.30.50.160:8080: connect: connection refused
See the memory increasing chart below:
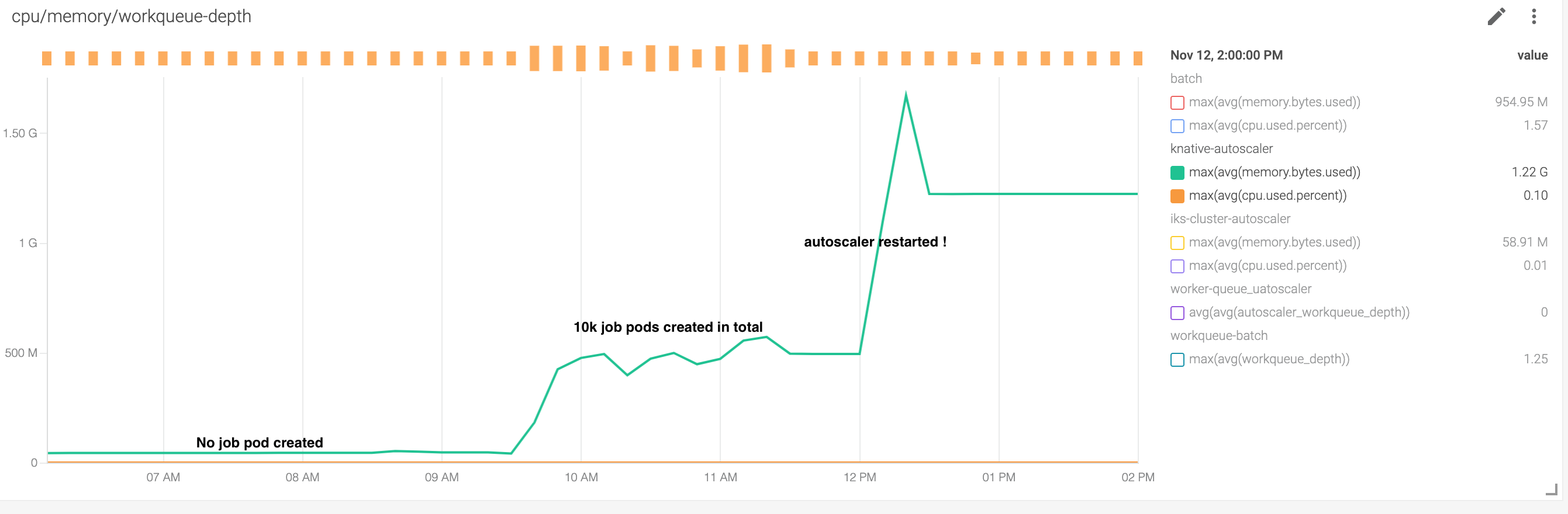
Expected behavior The expected behavior is that to tweak the list result to avoid sync so many pods information which are not related to knative at all.
I noticed there is tweak Options as filter https://github.com/knative/serving/blob/23dc86a5ac841e272742a1e0089da706d32a7e2a/vendor/k8s.io/client-go/informers/factory.go#L81-L86
Could we use the tweak options in podInformer of Knative by using labelSelector?
Anyway, I notice there is no determined label key/value to identify a pod is owned by knative. Maybe we can create a specific knative label. i.e “owner:serving.knative.dev” on pod, then use it as the tweakOption?
About this issue
- Original URL
- State: closed
- Created 4 years ago
- Comments: 26 (22 by maintainers)
We finished our spike to investigate TweakFilterOption, and the result looks positive.
Proposed changes: We tried to modify
knative.dev/pkg/client/injection/kube/informers/factory/factory.goto add a label selector inside, as describe in https://github.com/knative/pkg/pull/1940 .In this PR, the label selector can be defined in context.
If no specific label selector, then the same shardInformerFactory is returned as before. If a label selector is defined, then the informer generated by this factory will be tweak per the designed label.
Given podinformer only works in autoscaler, we add one line in autoscaler main.go as describe in https://github.com/knative/serving/pull/10266
Then, the pod informer is tweaked and only load pods which have the label “serving.knative.dev/service”.
Test Result
After the changes, we did a test to compare the memory footprint of the original autoscaler and the filtered autoscaler .
In original autoscaler, the memory is: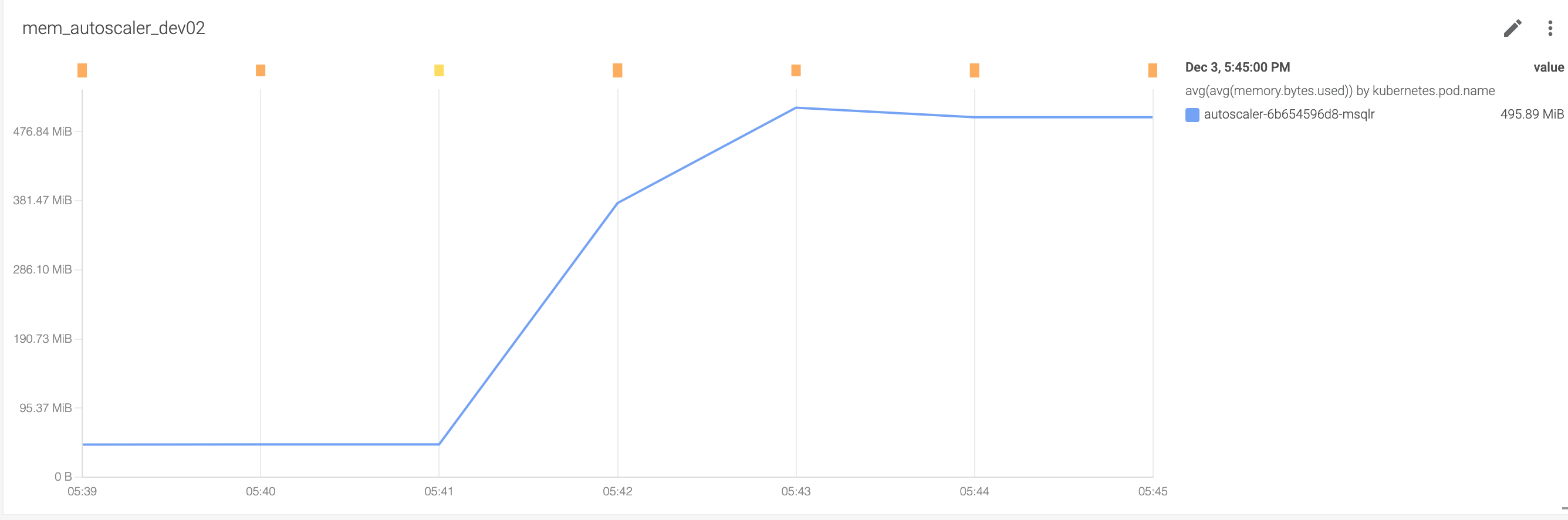
In the filtered autoscaler, the memory is: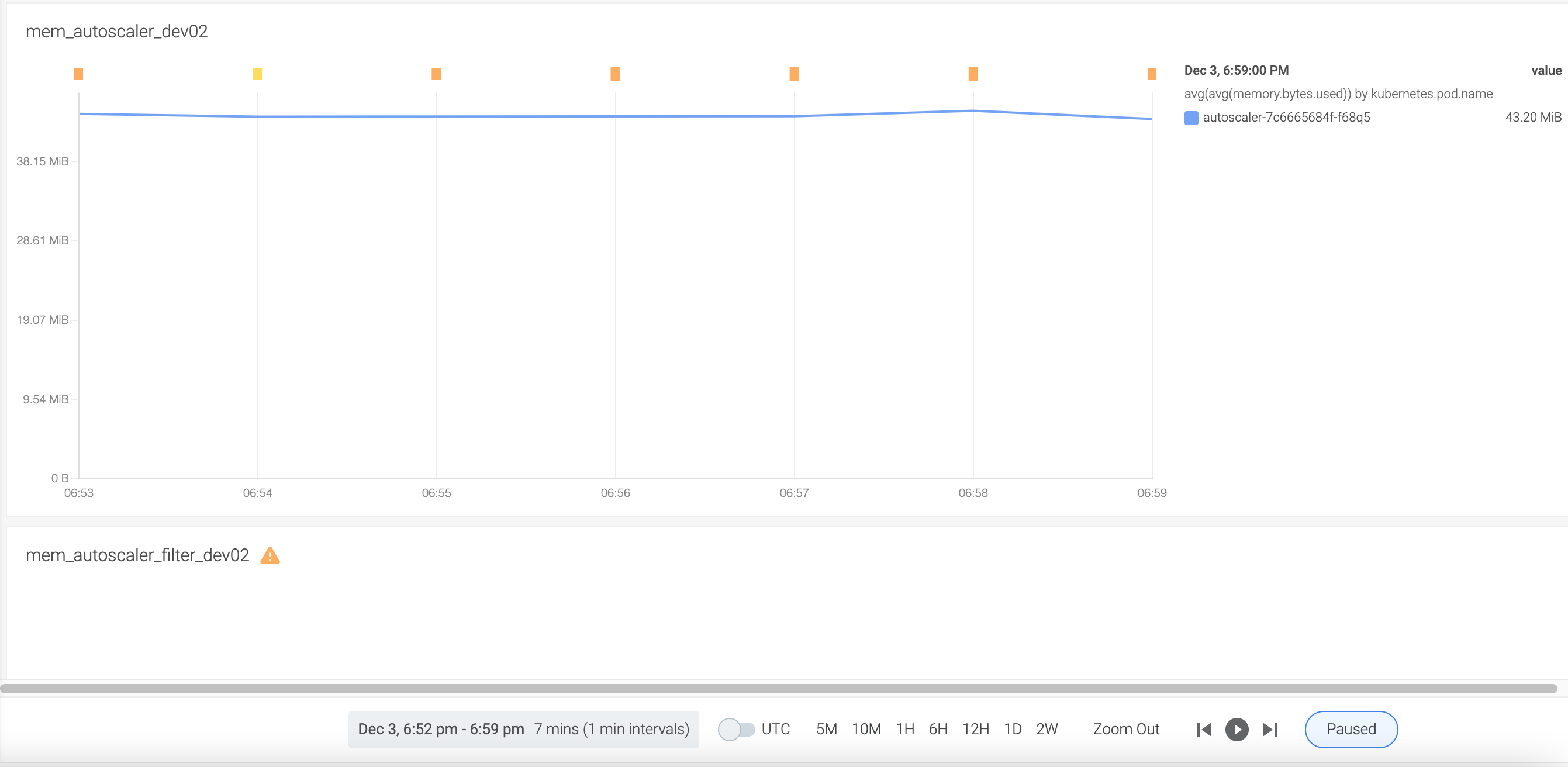
So, in this step, we validated that the tweakOption works to get rid of non-knative pods in list/watch.
In original autoscaler, the memory is: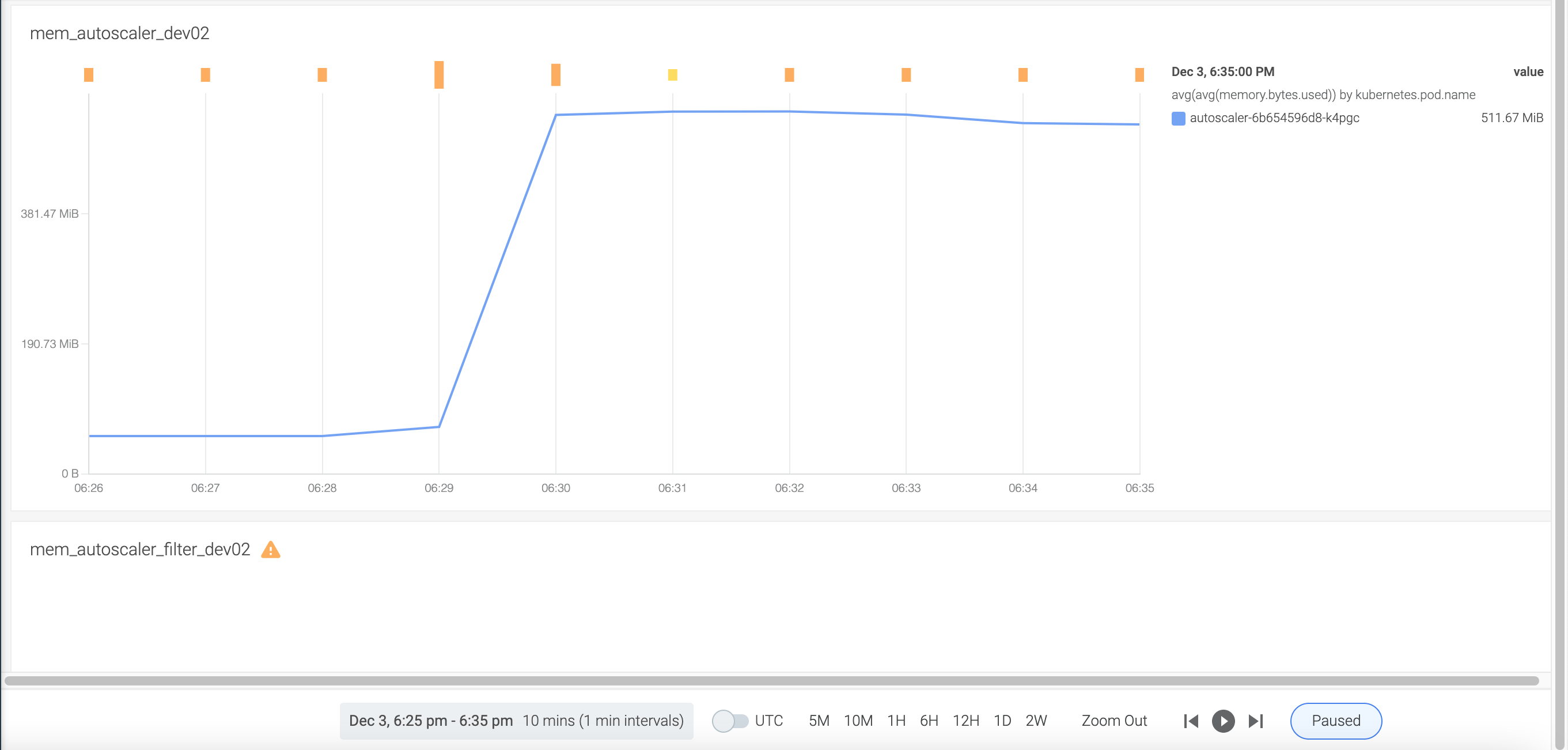
In the filtered autoscaler, the memory is: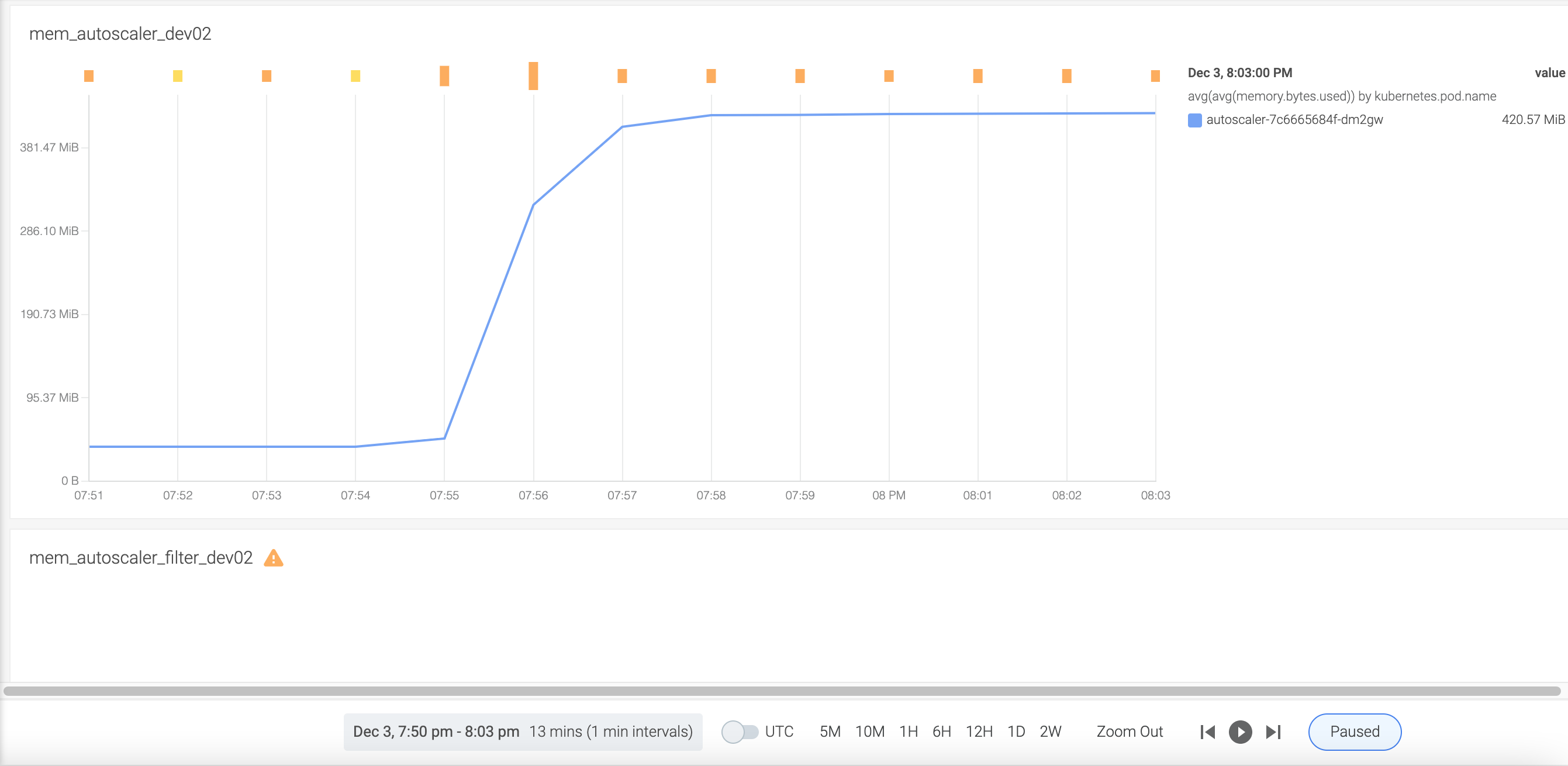
So, in this step, we validated that the knative pod info can still be fetched into autoscaler as previously.
To achieve the above result, we need to 2 PRs below:
Comments are warmly welcomed!