istio: Huge cardinality and complexity jump with telemetry v2
Hey all, I just wanted to share this concern as an issue so it can be discussed further. My believe is that telemtry v2 will increase prometheus metric cardinality quite significantly, especially for those with existing deployments on large clusters like ours.
This is because of the roll-up effect that the current mixer has at the moment. What I mean by rollup is that the pod_name is not a label on some of the biggest istio metrics, eg:
- istio_request_duration_seconds_bucket
- istio_response_bytes_bucket
- istio_request_bytes_bucket
So take this simplistic example:
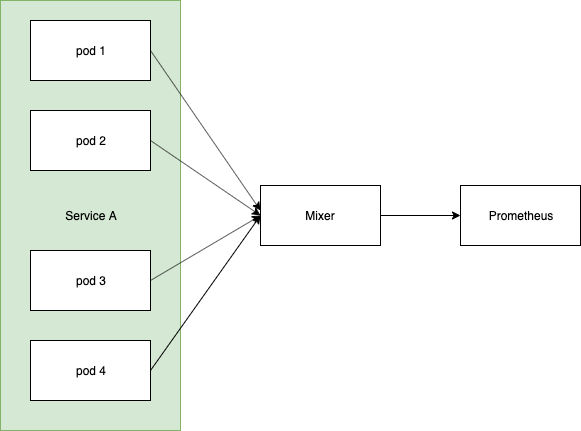
Currently you would end up with something like:
istio_request_duration_seconds_bucket{app="service1", instance="ip-of-mixer", le="whatever"} 40
With telemetry v2 you will end up with:
istio_request_duration_seconds_bucket{app="service1", pod_name="pod1", le="whatever"} 10
istio_request_duration_seconds_bucket{app="service1", pod_name="pod1", le="whatever"} 10
istio_request_duration_seconds_bucket{app="service1", pod_name="pod1", le="whatever"} 10
istio_request_duration_seconds_bucket{app="service1", pod_name="pod1", le="whatever"} 10
Each of these metrics already has high cardinality being a histogram (the le label), so this will result in huge increases in prometheus metrics.
Many of our applications run 10-20 pods, so the metrics explosion of switching to metrics which are labeled with the pod name I believe is going to be pretty huge and potentially unmanageable.
About this issue
- Original URL
- State: closed
- Created 5 years ago
- Reactions: 2
- Comments: 22 (21 by maintainers)
FYI for anyone coming to this thread, I wrote a blog post on how we’ve tackled this with federation and rollup rules: https://karlstoney.com/2020/02/25/federated-prometheus-to-reduce-metric-cardinality/