ColossalAI: Can not train llama-7b due to OOM on 40GA100
GPU 40GA1008
I want to train the 7B model of Llama on 40GA100, but it prompts that there is not enough GPU memory. The training command is:
torchrun --standalone --nproc_per_node=4 examples/train_sft.py --pretrain "**********7B/llama-7b" --model 'llama' --strategy colossalai_zero2 --log_interval 10 --save_path output/Coati-7B --dataset *********/data/merged_file.json --batch_size 1 --accimulation_steps 4 --lr 2e-5 --max_epochs 1 --lora_rank 4

40G should be enough for Llama’s 7B model. When I control the max_datasets_size like this
--max_datasets_size 4096
The training process will be done. But the usage of GPU memory is different at the beginning stage and near the end.
Beginning Stage
 Ending Stage
Ending Stage

Another question, I found that will confirm the W&B choice multi times。 Can this process be simplified?

About this issue
- Original URL
- State: open
- Created a year ago
- Comments: 48 (13 by maintainers)
This might be because that zero2 is not enough to save memory on 40 GB card, we used 80GB A100. To enable lower memory consumption, we should use colossalai_gemini strategy but it happens to have some bugs, we are fixing it and expect it to work next week. We will update the bug fix status here.
23/04/17 https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat#faq we have provide a a low resources example. Thanks.
Add
WANDB_MODE=disabledbefore torchrunHello, in the process of training Bloom-7B’s model, I found that OOM appeared after training for a period of time. May I ask why? @binmakeswell @easonfzw @ver217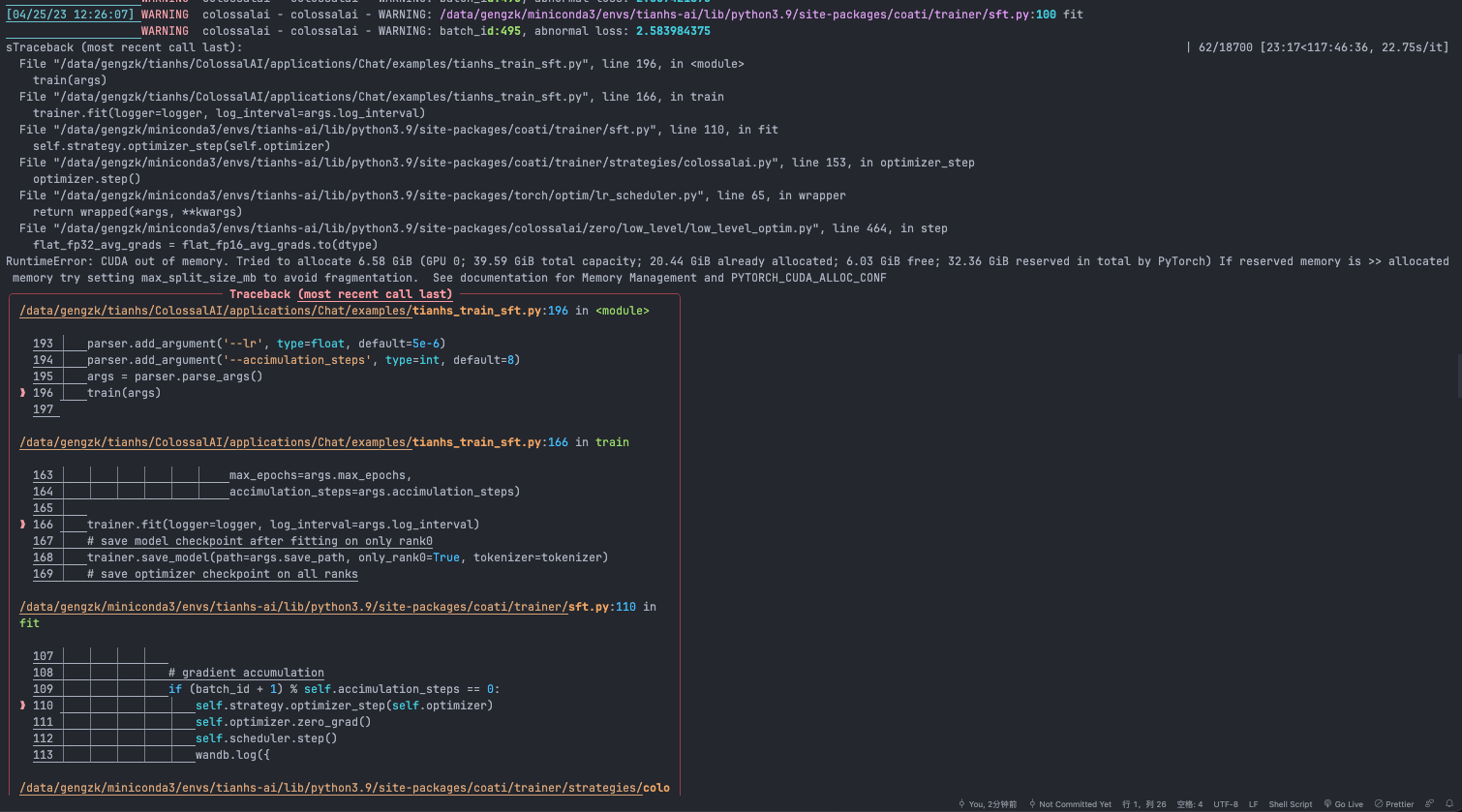
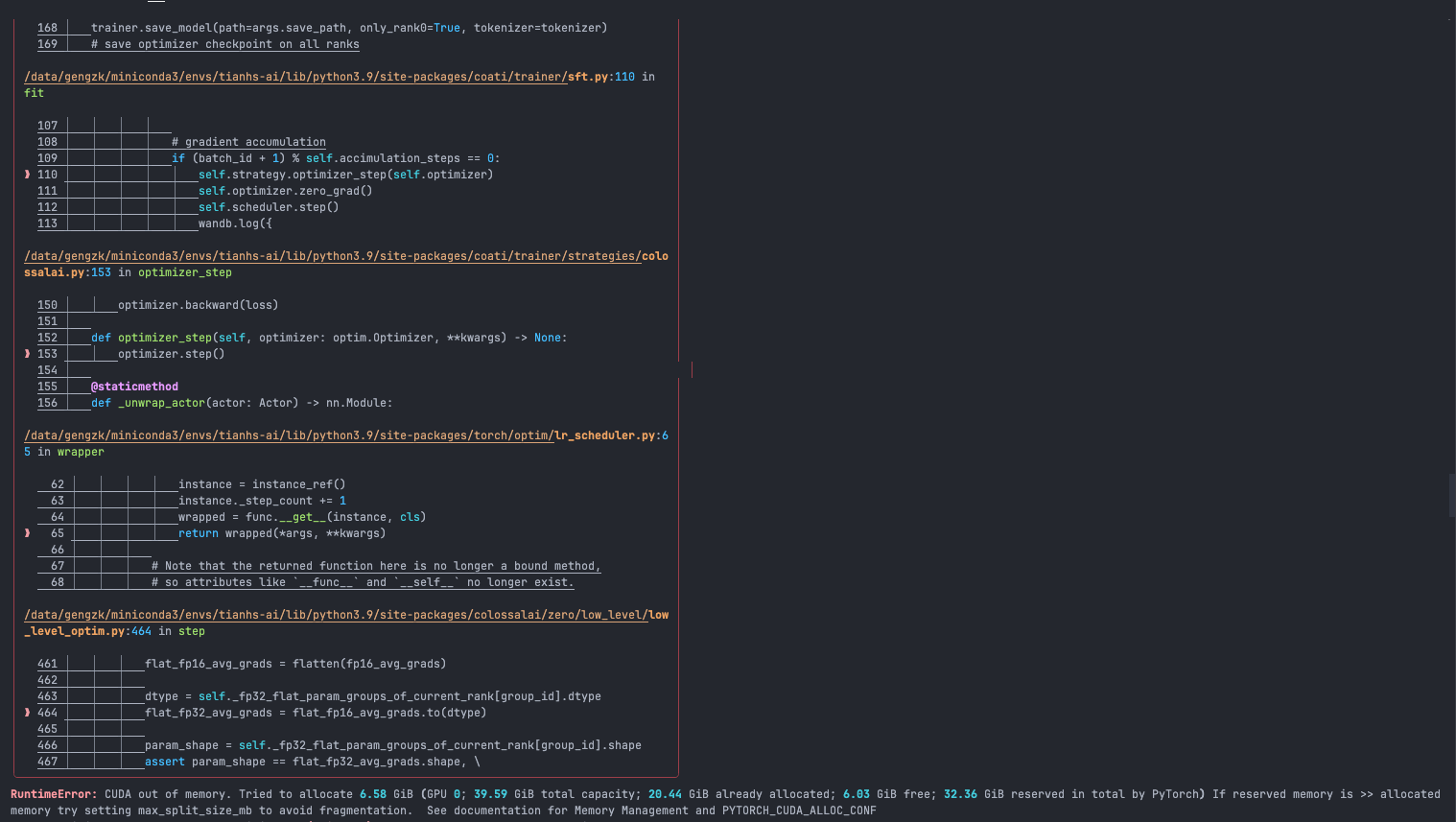
This is my training script: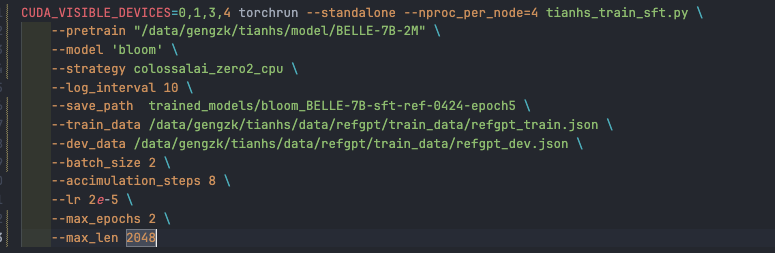
For reference, under the same configuration, colossalai_zero2 takes 5.11s/it in the first few steps (then OOM on 32G V100), while colossalai_zero2_cpu takes 13.08s/it.
Heal our children!
Thanks! If I understand correctly, “2” is the parameter memory consumption per billion parameter in fp16, “14” is the optimizer and gradient memory consumption per billion parameter? “14” is much larger than what I thought.
For LLaMA-7B, model data will take
(2+14/4) * 7 = 38.5GB memory for each GPU if using 4 GPUsIt creates FP32 master weights after initializing trainer. However, FP32 master weights will be sharded if using multiple GPUs.
For larger task like this, you can contact our commercial or me directly, which may help you solve this problem more faster
8*V100 32G got the same OOM
Set placement_policy=‘cpu’ can alleviate this question.