harvester: [Doc] user report: after adding a 3rd node into cluster, the2nd node goes to cordoned/Unavailable state
Describe the bug
User @rajesh1084 report: “I’m trying to build a 3-node Harvester HCI setup. As soon as I add the 3rd node, 2nd node goes to cordoned/Unavailable state (Kubelet stopped posting node status). Any thoughts?”
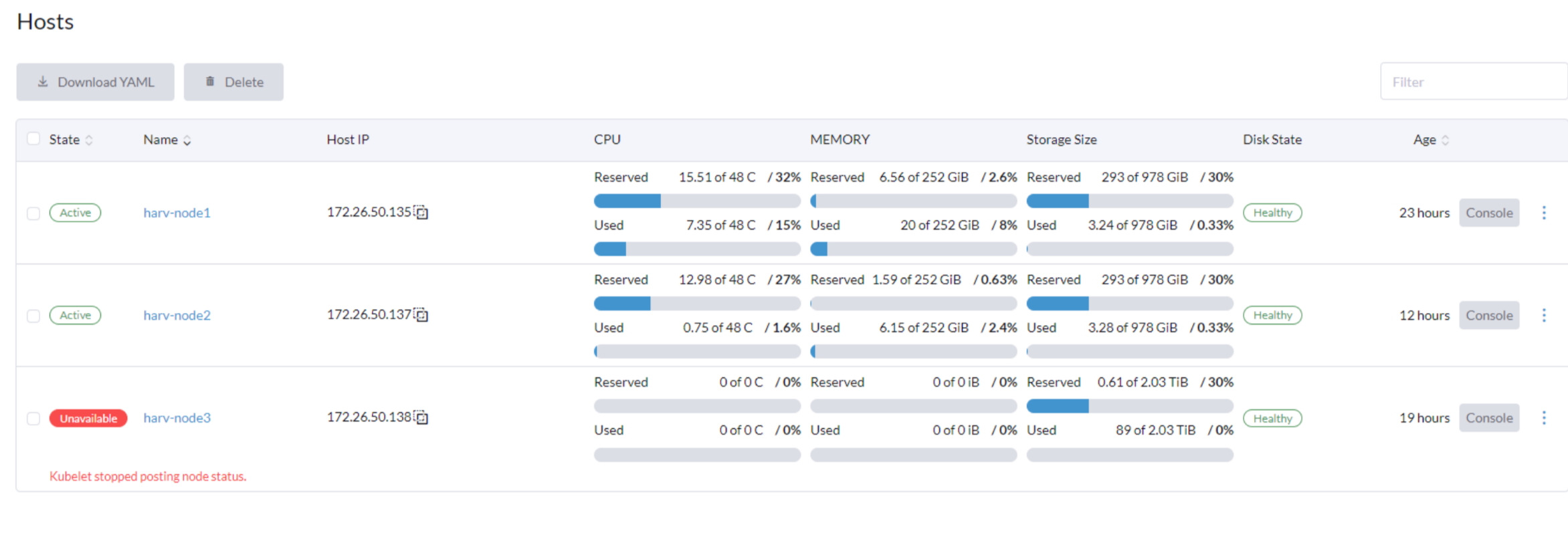
For better understanding the cluster. Please note: harv-node3 is the second NODE joined the cluster.
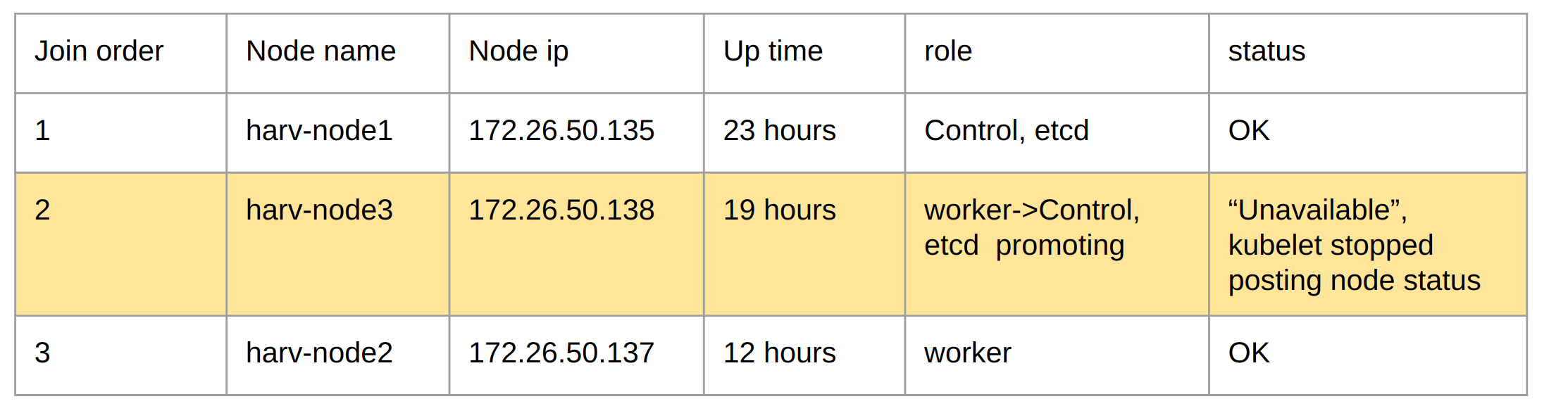
The harv-node3 CAN NOT recover by itself.
Time line:
harv-node1, the first node in cluster
harv-node3, the second node in cluster
Oct 20 11:47:43 harv-node3 systemd[1]: Finished Rancher Bootstrap.
first as an agent node, unti Oct 20 18:37:01
harv-node2, the third node, join the cluster
harv-node3 switch role from agent to server
Oct 20 18:37:01 harv-node3 systemd[1]: rke2-agent.service: Unit process 46440 (containerd-shim) remains running after unit>
Oct 20 18:37:01 harv-node3 systemd[1]: Stopped Rancher Kubernetes Engine v2 (agent).
then become rke-2 server
but the rke2-server.service has continuous error
To Reproduce Steps to reproduce the behavior:
- Go to ‘…’
Expected behavior
Each NODE should be in healthy state
Support bundle
posted in : https://github.com/harvester/harvester/issues/3039#issuecomment-1293019045
The harv-node3 is abnormal, the support-bundle does NOT include related file. Below file is generated via journalctl --unit=rke2-server in harv-node3.
harv-node1:~ # for ip in {172.26.50.135,172.26.50.137,172.26.50.138}; do echo $ip; ssh rancher@$ip date; done
172.26.50.135
Wed Oct 26 10:11:59 UTC 2022
172.26.50.137
Wed Oct 26 10:12:00 UTC 2022
172.26.50.138
Wed Oct 26 10:12:00 UTC 2022
harv-node3:~ # ping 172.26.50.135 (harv-node1)
PING 172.26.50.135 (172.26.50.135) 56(84) bytes of data.
64 bytes from 172.26.50.135: icmp_seq=1 ttl=64 time=0.155 ms
64 bytes from 172.26.50.135: icmp_seq=2 ttl=64 time=0.169 ms
Environment
- Harvester ISO version:
- Underlying Infrastructure (e.g. Baremetal with Dell PowerEdge R630):
Additional context Add any other context about the problem here.
About this issue
- Original URL
- State: closed
- Created 2 years ago
- Comments: 25 (11 by maintainers)
I had not configured
no-proxywhen I had faced the issue.I’m confused, the issue mentions that adding a third node causes the second node to become unavailable. I’m only seeing logs here from node 1 and 3 - where are the logs from node 2?
I will also say that the way rajesh1084 has pasted the logs and CLI output into the comment makes it very hard to read and follow this thread. Please surround things with a code block:
kube-system_kube-apiserver-harv-node1_5ca3c4e79a65ef37c1d591197744493f.zip kube-system_etcd-harv-node3_67c7ddaaa7ef609d17948e7397585b18.zip kubelet_harv-node3.zip