kubernetes-ingress: Memory leak & haproxy.cfg stopped syncing
👋🏻 from GitHub
Today, we ran into an issue where the controller started began leaking memory and then stopped updating /etc/haproxy/haproxy.cfg leading to a situation where haproxy had an incorrect set of backends. Memory usage had a spike right around the time haproxy.cfg stopped updating and then kept slowly creeping up.
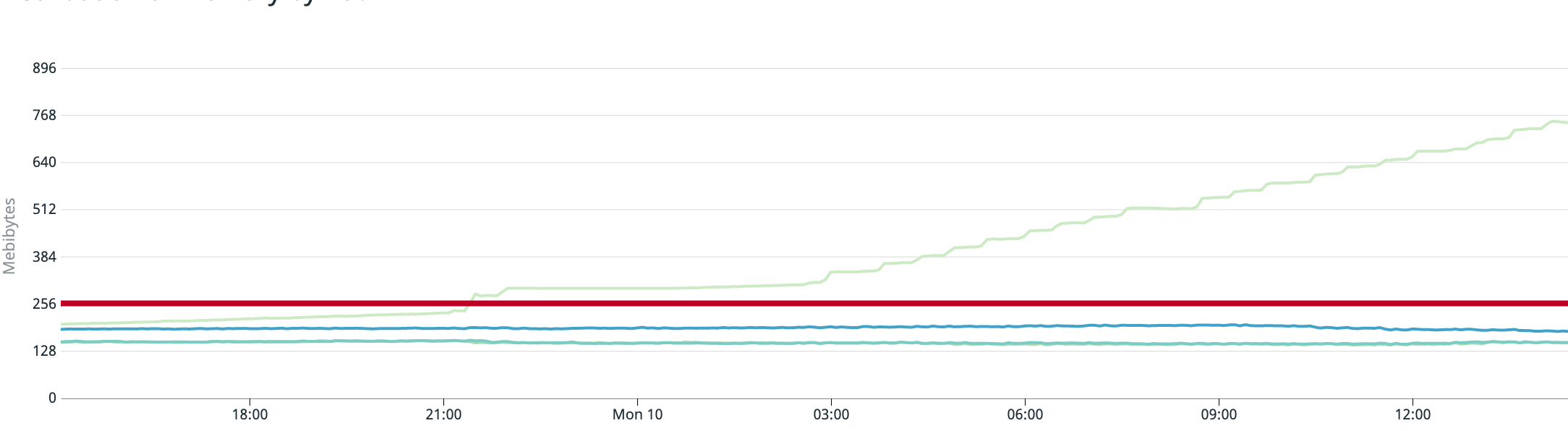 The light green line is the problematic Pod. Red is the CPU request, and the other lines are the other Pods from this Deployment of the ingress controller which were functioning normally.
The light green line is the problematic Pod. Red is the CPU request, and the other lines are the other Pods from this Deployment of the ingress controller which were functioning normally.
Attached is an SVG flame graph of the process captured with perf several hours after the initial spike, while the memory was staircasing its way up as well as a stack trace captured by sending the process SIGQUIT.
{kind=link}
Kubernetes Deployment YAML
---
# Source: kubernetes-ingress/templates/controller-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: ingress-unicorn-api-kubernetes-ingress
namespace: haproxytech-ingress
labels:
addonmanager.kubernetes.io/mode: Reconcile
app.kubernetes.io/name: kubernetes-ingress
helm.sh/chart: kubernetes-ingress-1.14.2
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/instance: ingress-unicorn-api
app.kubernetes.io/version: 1.6.0
data:
syslog-server: address:stdout, facility:daemon, format:raw,
nbthread: "1"
timeout-client: 150s
timeout-client-fin: 5s
timeout-connect: 100ms
timeout-queue: 90s
timeout-server: 150s
timeout-server-fin: 5s
timeout-tunnel: 150s
---
# Source: kubernetes-ingress/templates/controller-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: ingress-unicorn-api-kubernetes-ingress
namespace: haproxytech-ingress
labels:
addonmanager.kubernetes.io/mode: Reconcile
app.kubernetes.io/name: kubernetes-ingress
helm.sh/chart: kubernetes-ingress-1.14.2
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/instance: ingress-unicorn-api
app.kubernetes.io/version: 1.6.0
spec:
replicas: 4
selector:
matchLabels:
app.kubernetes.io/name: kubernetes-ingress
app.kubernetes.io/instance: ingress-unicorn-api
template:
metadata:
labels:
app.kubernetes.io/name: kubernetes-ingress
app.kubernetes.io/instance: ingress-unicorn-api
spec:
serviceAccountName: ingress-unicorn-api-kubernetes-ingress
terminationGracePeriodSeconds: 60
dnsPolicy: ClusterFirst
priorityClassName: system-cluster-critical
# The helm chart doesn't have a configurable for securityContext, so this is manually added
securityContext:
sysctls:
- name: net.core.somaxconn
value: "10240"
- name: net.ipv4.tcp_tw_reuse
value: "1"
containers:
- name: kubernetes-ingress-controller
image: "haproxytech/kubernetes-ingress:1.6.0"
imagePullPolicy: IfNotPresent
args:
- --configmap=haproxytech-ingress/ingress-unicorn-api-kubernetes-ingress
- --ingress.class=haproxytech-unicorn-api
- --publish-service=haproxytech-ingress/ingress-unicorn-api-kubernetes-ingress
- --log=info
- --configmap-tcp-services=haproxytech-ingress/tcpservices-unicorn-api
- --disable-http
- --disable-https
- --disable-ipv6
ports:
- name: stat
containerPort: 1024
protocol: TCP
- name: http-tcp
containerPort: 8080
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /
port: 1024
scheme: HTTP
initialDelaySeconds: 5
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
startupProbe:
failureThreshold: 20
httpGet:
path: /healthz
port: 1042
scheme: HTTP
initialDelaySeconds: 0
periodSeconds: 1
successThreshold: 1
timeoutSeconds: 1
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: GOMAXPROCS
value: "1"
resources:
requests:
cpu: 1
memory: 256Mi
lifecycle:
preStop:
exec:
command:
- /bin/sh
- -c
- sleep 5
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app.kubernetes.io/name
operator: In
values:
- kubernetes-ingress
topologyKey: kubernetes.io/hostname
Versions:
- Ingress controller v1.6.0
- Kubernetes 1.20.2
- Kernel 4.19
❤️ for any help you can provide/suggestions. Happy to provide more information.
About this issue
- Original URL
- State: closed
- Created 3 years ago
- Comments: 17 (10 by maintainers)
Commits related to this issue
- OPTIM/MEDIUM: Update Ingress status in a seperate goroutine Updating status in Ingress resources is subject to delays, network issues, etc. Doing it in the main IC goroutine may halter IC execution a... — committed to haproxytech/kubernetes-ingress by Mo3m3n 3 years ago
- OPTIM/MEDIUM: Update Ingress status in a seperate goroutine Updating status in Ingress resources is subject to delays, network issues, etc. Doing it in the main IC goroutine may halter IC execution a... — committed to haproxytech/kubernetes-ingress by Mo3m3n 3 years ago
Available in
v1.6.6Thanks again @aaronbbrownThis was fixed in master (available in nightly build) and backported to v1.6 so it can be available in next v1.6 minor release