go: runtime: 1.13 performance regression on kubernetes scaling
Together with golang team, we, kubernetes sig-scalability, are testing not-yet-released golang1.13 against kubernetes scale tests.
What version of Go are you using (go version)?
$ go version devel +c290cb6338 Sun Jun 23 22:20:39 2019 +0000
Does this issue reproduce with the latest release?
Yes, it reproduces with golang head.
What did you do?
We’ve run k8s scale tests with kubernetes compiled with go1.13. There is a visible increase in 99th percentile of api call latency when compared to the same version of kubernetes compiled against go1.12.5.
What did you expect to see?
We expected similar api-call latency as in the baseline run compiled with go1.12.5

What did you see instead?
The api-call latency was visibly worse in the run compiled with golang1.13

About this issue
- Original URL
- State: closed
- Created 5 years ago
- Reactions: 3
- Comments: 57 (29 by maintainers)
Commits related to this issue
- runtime: add physHugePageShift This change adds physHugePageShift which is defined such that 1 << physHugePageShift == physHugePageSize. The purpose of this variable is to avoid doing expensive divis... — committed to golang/go by mknyszek 5 years ago
- runtime: call sysHugePage less often Currently when we coalesce memory we make a sysHugePage call (MADV_HUGEPAGE) to ensure freed and coalesced huge pages are treated as such so the scavenger's assum... — committed to golang/go by mknyszek 5 years ago
- runtime: redefine scavenge goal in terms of heap_inuse This change makes it so that the scavenge goal is defined primarily in terms of heap_inuse at the end of the last GC rather than next_gc. The re... — committed to golang/go by mknyszek 5 years ago
- runtime: scavenge on growth instead of inline with allocation Inline scavenging causes significant performance regressions in tail latency for k8s and has relatively little benefit for RSS footprint.... — committed to golang/go by mknyszek 5 years ago
- [release-branch.go1.13] runtime: grow the heap incrementally Currently, we map and grow the heap a whole arena (64MB) at a time. Unfortunately, in order to fix #32828, we need to switch from scavengi... — committed to golang/go by aclements 5 years ago
Hey Folks,
I think I have great news.
I’ve re-run the full tests on golang1.12 (baseline) and golang1.13 (at https://github.com/golang/go/commit/2754118731b81baf0c812116a9b72b6153abf79d) with the two patches that we tried already (which helped, but didn’t fix the performance issue totally), i.e., https://go-review.googlesource.com/c/go/+/189957/3, https://go-review.googlesource.com/c/go/+/183857/8 + the new @mknyszek’s patch, https://go-review.googlesource.com/c/go/+/193040/2, and there is no visible difference in api-call-latency. In some aspects the golang1.13 run is even slightly better than the baseline.
I’ll post a more detailed comparison here later, but the summary is that if we could land all those 3 patches, then we, K8s SIG-Scalability, would be completely satisfied with the golang1.13 performance, meaning that we can basically close this issue.
@aclements, @mknyszek, any thoughts on that? How hard would it be to release these patches? Any estimate on the potential timeline?
This issue is closed now because we fixed this on master, but for Go 1.13 we have two backport issues which track the two problems and their fixes for Go 1.13.
They are #34556 and #34149.
The comparison I promised in the previous post.
Api-call latency (non-LIST)
baseline golang1.13
golang1.13

The results are very similar, golang1.13 has 3 spikes exceeding 1.5s that we don’t see in the baseline, but this is most likely noise. I’m quite sure that if we re-run the tests these spikes could disappear or even appear in the baseline. Single spikes are acceptable, and that’s why our performance SLIs are not based on instant api-call-latency but rather on aggregation over whole test, which we’ll compare below.
Aggregated api-call latency
baseline golang1.13
golang1.13

During the test, the graph for golang1.13 looks worse due to the 3 spikes above, but looking at the end of the test the golang1.13 run actually looks better. There are only 6 metrics exceeding 500ms (in baseline there are 8) and none exceeding 1s (in baseline there is 1).
Aggregated LIST latency
baseline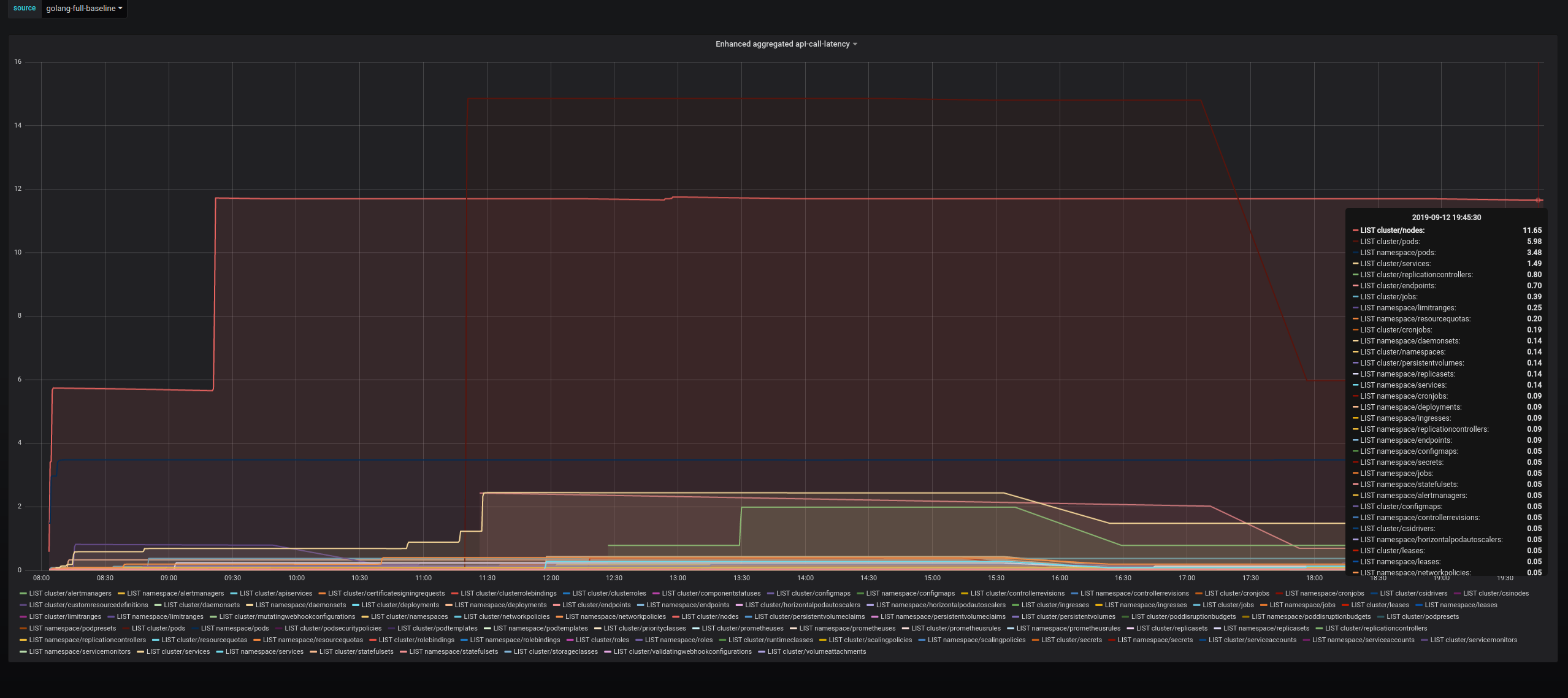 golang1.13
golang1.13

This time it’s clearly in favor of the golang1.13. The aggregated list latency is clearly better for the golang1.13 run.
To sum up, some aspects are worse for golang1.13 and some are better, but most differences are most likely just a noise. Overall the golang1.13 run looks quite good comparing to the baseline. There is nothing that stands out and golang1.13 performance looks reasonable from the k8s scalability point of view. Putting it in other words, with the three patches we don’t observe any obvious performance degradation between golang1.12 and golang1.13.
I believe we can close this issue once all three patches merge.
Let me know if there is anything more we can assist you with and thank you so much for your tireless work on this issue!
I think I’ve narrowed down the range of CLs which contain the source of the regression, and they’re all mine.
Turns out it has nothing to do with the background scavenger, but rather with changes I made to the treap implementation in the runtime, which feels familiar. Reducing the number of treap operations required for allocation/free/scavenging probably isn’t possible without a huge refactoring, so I think the main thing to do here is to try to make the operations themselves faster. I didn’t expect what I added to have such a large effect but given that there’s a lot of heap lock contention I suppose I shouldn’t be surprised.
In the past I attempted to add a cache to speed up allocations, but it didn’t help much. But, perhaps there’s something yet-unexplored here. I’ll think about it some more.