harbor: Harbor Projects Are Very Slow to Load
I wonder if maybe I have a misconfig somewhere or need to allocate more resources or enable a caching mechanism because when I go to the projects view it takes a long time to load. First it takes a long time to load the list of projects at /harbor/projects/ then when I click my projects and go to respositories e.g. /projects/2/repositories/ or helm charts e.g. /projects/2/helm-charts/.
Load times: 23.15s for main projects page: /harbor/projects/ 20.96s for clicking through to my project: /projects/2/repositories/ 21.33s for clicking through to my chart repo: /projects/2/repositories/
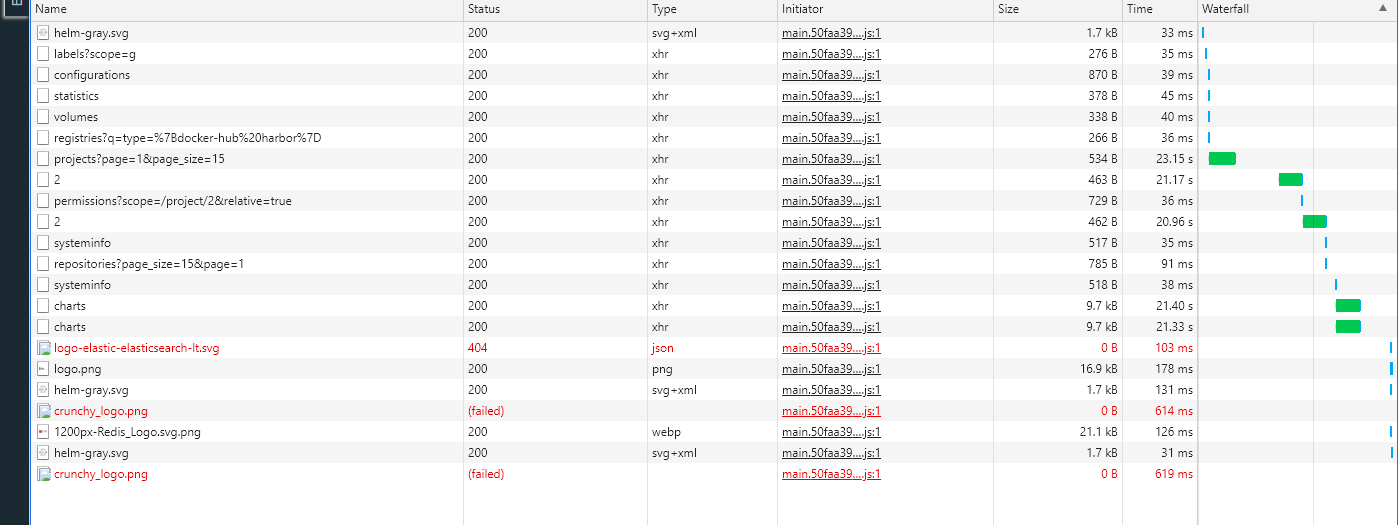
The main project has 335 Repositories and 366 Helm Charts.
Any idea how I can increase performance here?
Here are my chart values:
chartmuseum:
absoluteUrl: false
enabled: true
image:
repository: goharbor/chartmuseum-photon
tag: v2.1.0
nodeSelector:
agentpool: stateful
replicas: 1
clair:
adapter:
image:
repository: goharbor/clair-adapter-photon
tag: v2.1.0
clair:
image:
repository: goharbor/clair-photon
tag: v2.1.0
enabled: true
nodeSelector:
agentpool: stateful
replicas: 1
updatersInterval: 12
core:
image:
repository: goharbor/harbor-core
tag: v2.1.0
nodeSelector:
agentpool: stateful
replicas: 1
resources:
requests:
cpu: 300m
memory: 8192Mi
startupProbe:
initialDelaySeconds: 10
database:
internal:
image:
repository: goharbor/harbor-db
tag: v2.1.0
nodeSelector:
agentpool: stateful
password: censored
resources:
requests:
cpu: 100m
memory: 256Mi
sslmode: disable
maxIdleConns: 50
maxOpenConns: 1000
type: internal
expose:
clusterIP:
name: harbor
ports:
httpPort: 80
ingress:
annotations:
ingress.kubernetes.io/proxy-body-size: 10000m
ingress.kubernetes.io/ssl-redirect: "true"
kubernetes.io/ingress.allow-http: "false"
kubernetes.io/ingress.class: nginx
kubernetes.io/tls-acme: "true"
nginx.ingress.kubernetes.io/proxy-body-size: 10000m
nginx.ingress.kubernetes.io/ssl-redirect: "true"
controller: default
hosts:
core: harbor.x.com
tls:
certSource: secret
enabled: true
secret:
notarySecretName: harbor.x.com
secretName: harbor.x.com
type: ingress
externalURL: https://harbor.x.com
harborAdminPassword: censored
imagePullPolicy: IfNotPresent
internalTLS:
certSource: auto
chartmuseum:
crt: ""
key: ""
secretName: ""
clair:
crt: ""
key: ""
secretName: ""
core:
crt: ""
key: ""
secretName: ""
enabled: false
jobservice:
crt: ""
key: ""
secretName: ""
portal:
crt: ""
key: ""
secretName: ""
registry:
crt: ""
key: ""
secretName: ""
trivy:
crt: ""
key: ""
secretName: ""
trustCa: ""
jobservice:
image:
repository: goharbor/harbor-jobservice
tag: v2.1.0
jobLogger: stdout
maxJobWorkers: 10
replicas: 1
logLevel: debug
notary:
affinity: {}
enabled: false
nodeSelector: {}
podAnnotations: {}
secretName: ""
server:
image:
repository: goharbor/notary-server-photon
tag: v2.1.0
replicas: 1
serviceAccountName: ""
signer:
image:
repository: goharbor/notary-signer-photon
tag: v2.1.0
replicas: 1
serviceAccountName: ""
tolerations: []
persistence:
enabled: true
imageChartStorage:
disableredirect: false
gcs:
bucket: harbor
chunksize: "5242880"
encodedkey: x
rootdirectory: /
type: gcs
persistentVolumeClaim:
chartmuseum:
accessMode: ReadWriteOnce
existingClaim: '-'
size: 5Gi
storageClass: ""
subPath: ""
database:
accessMode: ReadWriteOnce
existingClaim: ""
size: 32Gi
storageClass: fast
subPath: ""
jobservice:
accessMode: ReadWriteOnce
existingClaim: ""
size: 8Gi
storageClass: fast
subPath: ""
redis:
accessMode: ReadWriteOnce
existingClaim: ""
size: 32Gi
storageClass: fast
subPath: ""
registry:
accessMode: ReadWriteOnce
existingClaim: ""
size: 5Gi
storageClass: '-'
subPath: ""
trivy:
accessMode: ReadWriteOnce
existingClaim: ""
size: 5Gi
storageClass: fast
subPath: ""
resourcePolicy: keep
portal:
image:
repository: goharbor/harbor-portal
tag: v2.1.0
nodeSelector:
agentpool: stateful
replicas: 1
resources:
requests:
cpu: 300m
memory: 1Gi
proxy:
components:
- core
- jobservice
- clair
- trivy
httpProxy: null
httpsProxy: null
noProxy: 127.0.0.1,localhost,.local,.internal
redis:
internal:
image:
repository: goharbor/redis-photon
tag: v2.1.0
nodeSelector:
agentpool: stateful
serviceAccountName: ""
type: internal
registry:
controller:
image:
repository: goharbor/harbor-registryctl
tag: v2.1.0
credentials:
htpasswd: user_harbor:censored
password: censored
username: user_harbor
middleware:
enabled: false
registry:
image:
repository: goharbor/registry-photon
tag: v2.1.0
relativeurls: false
replicas: 1
secretKey: pass
trivy:
affinity: {}
debugMode: false
enabled: true
ignoreUnfixed: false
image:
repository: goharbor/trivy-adapter-photon
tag: v2.1.0
insecure: false
nodeSelector: {}
podAnnotations: {}
replicas: 1
resources:
limits:
cpu: 1
memory: 1Gi
requests:
cpu: 200m
memory: 512Mi
severity: UNKNOWN,LOW,MEDIUM,HIGH,CRITICAL
skipUpdate: false
tolerations: []
vulnType: os,library
updateStrategy:
type: RollingUpdate
About this issue
- Original URL
- State: closed
- Created 4 years ago
- Reactions: 2
- Comments: 19 (3 by maintainers)
I did some debug log hunting, and it seems part of the problem is it runs a helm repo update to download the index yaml for chartmuseum for every call to ths project. This seems pretty inefficient. Maybe the index yaml can be cached to redis on each chart push and then read from there?
Could it be an option to move from 0.12.0 to the newer version 0.13.1 of chartmuseum? A performance problem in chartmuseum has been fixed already in version 0.13.0: Improve performance when dealing with thousands of charts
Another thing I noticed is that the index-cache.yaml stored in s3 bucket ( because my backend storage is s3 ), harbor never cleans up index.yaml after deleting a chart from harbor. This overtime makes the index.yaml huge and running a helm repo update on each call to the project on a large enough index.yaml slows operation down by a lot !
Running into the same issues with just 10 helm charts but several versions of each and 50 repos… this makes the UI unusable …
I think this should no longer be tagged as pending more info needed since the problem is clear as are the potential solutions. @ninjadq
So the problem is every single call to the project related endpoints forces a helm repo update call to chartmuseum to get a fresh index yaml instead of caching it. This means no matter how many charts you have it will cause problems. The solution would be to store the index yaml inside of redis and serve the index yaml that way then have a backend cron job or scheduled job with a configurable refresh timer to not have this call on every page load. This will solve everything while also making chartmuseum usable. Because using container registry storage for charts isn’t an option while it is still experimental.
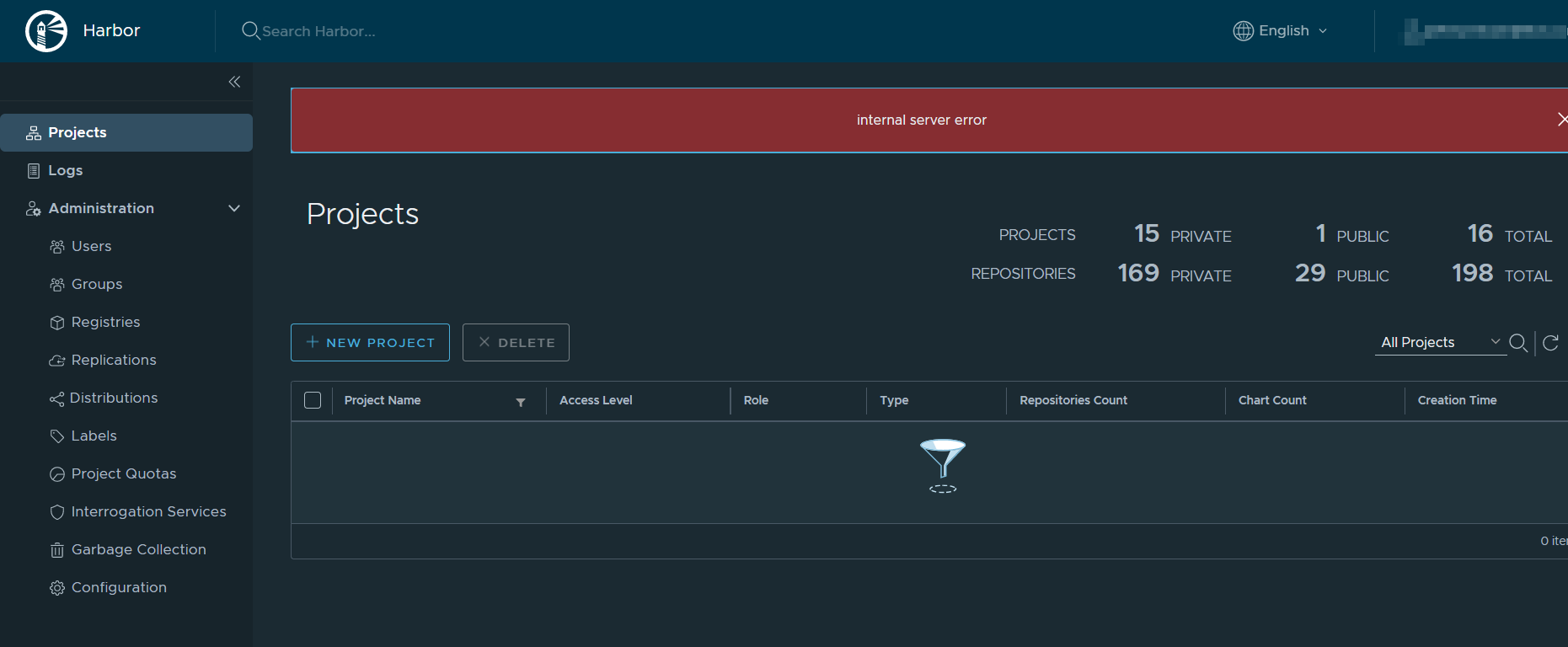
Since upgrading to 2.1 we are seeing what appears to be the same issue. We only have a handful of helm charts (we are not using OCI with Helm 3 because it is still considered Experimental and we need to deliver Helm Charts to our end users). In some cases the main Project Page takes >30 seconds to load and once in a while ends with this: