geopandas: [clip vs. intersect] polygons lost due to dropping duplicates generated by .overlay()
I was testing the .overlay() function and got some interesting issues.
I imported two geojson files as the following:
The first one has a shape of (2167, 17), with a OBJECTID column:
 The second one has a shape of (5, 5):
The second one has a shape of (5, 5):
 I ran
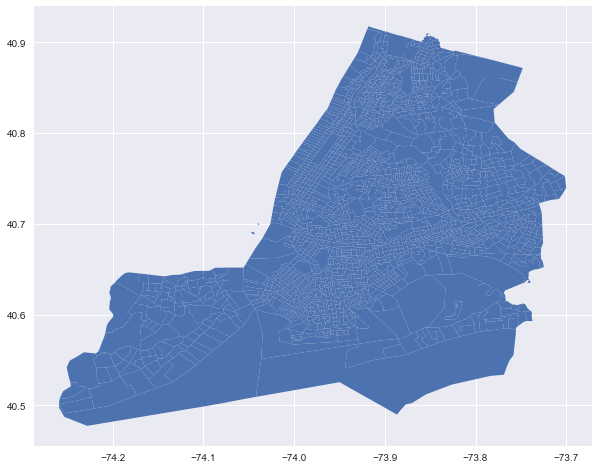
I ran .overlay(how='intersection'), and got the following map with a shape of (3195, 21)
 The above map looks right, but there are many duplicated rows in the geodataframe. I used the method posted by folks here, and transferred the geometry column to wkb. I then ran
The above map looks right, but there are many duplicated rows in the geodataframe. I used the method posted by folks here, and transferred the geometry column to wkb. I then ran .nunique() and saw there are 2165 unique values in OBJECTID, but there are 3195 unique values in the geometry column. I’m confused that why the number is not 2165 and exceeds both geodataframes I imported. Then I dropped those duplicated values based on the OBJECTID column with .drop_duplicates(subset='OBJECTID', inplace=True). I plotted the geodataframe again and got the following map. I realized that some of the polygons have lost. (Btw, I used both geojson files in QGIS before and got an identical map like the one above by .overlay(how='intersection'), and the clipped layer got 2165 rows in the attribute table, so it seems that 2165 is the right number to expect)
 I checked GeoPanads’s API and didn’t see any way to prevent those duplicated rows from generating. I don’t know why there are 3195 rows in the geodataframe, and why those polygons are lost by dropping duplicates.
I checked GeoPanads’s API and didn’t see any way to prevent those duplicated rows from generating. I don’t know why there are 3195 rows in the geodataframe, and why those polygons are lost by dropping duplicates.
About this issue
- Original URL
- State: closed
- Created 6 years ago
- Comments: 23 (6 by maintainers)
@austinorr I believe you brought this issue to me before. What do you think of https://github.com/geopandas/geopandas/issues/1027 ?
@austinorr thank you for mentioning that man. I was assuming that both are the same.
@stevencollinscn thanks for the feedback and the reproducible example!
I think the different result comes from a difference in expectations. The
overlaywith ‘intersection’ is not the same as a “clip” operation (I think), so you should not expect it to give necessarily the same result.As far as I understand “clip”, it basically cuts the left dataframe based on the “area of interest” of the right dataframe, no matter how the right dataframe is divided into multiple geometries. On the other hand, “overlay” (or at least how it is implemented in geopandas) combines the actual geometries of both left and right dataframe by taking the intersections (in this case).
To be more practical, for the geometries in
state(left) dataframe that overlap with a border of the boroughs (right) dataframe:overlaywill actually cut them in two by taking the intersection with each of the overlapping boroughs, while “clip” simply limits each of those geometries to the area that overlaps with all boroughs combined.That explains why the “duplicate” values in the result are near the borders. But also note that those are not really duplicate. It’s only the object id that is duplicated, because each of the two “duplicated” values comes from a single geometry in
state.Currently, geopandas does not provide such a “clip” behaviour out of the box. One way would be to combine the geometries with the same object id after doing the overlay, which you can do with
dissolve:which gives the desired 2194 number of features.
Or alternatively (potentially conceptually simpler / closer to “clip”), is to simply take the intersection with the union of the right dataframe and drop the empty geometries:
however this is (in this case) slower as the overlay + dissolve.