falco: Not able to detect k8s metadata with containerd
Describe the bug
We switched our kubernetes clusters from docker to containerd. After we are not able to see kubernetes metadatas at all in falco events.
After (with docker):
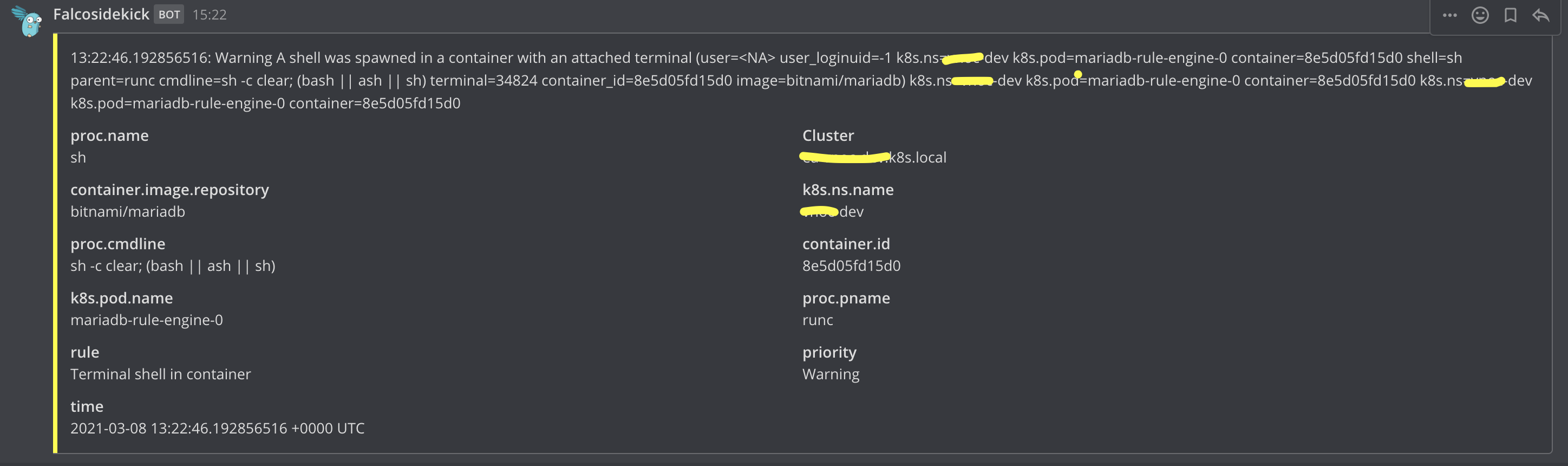
Before (with containerd):
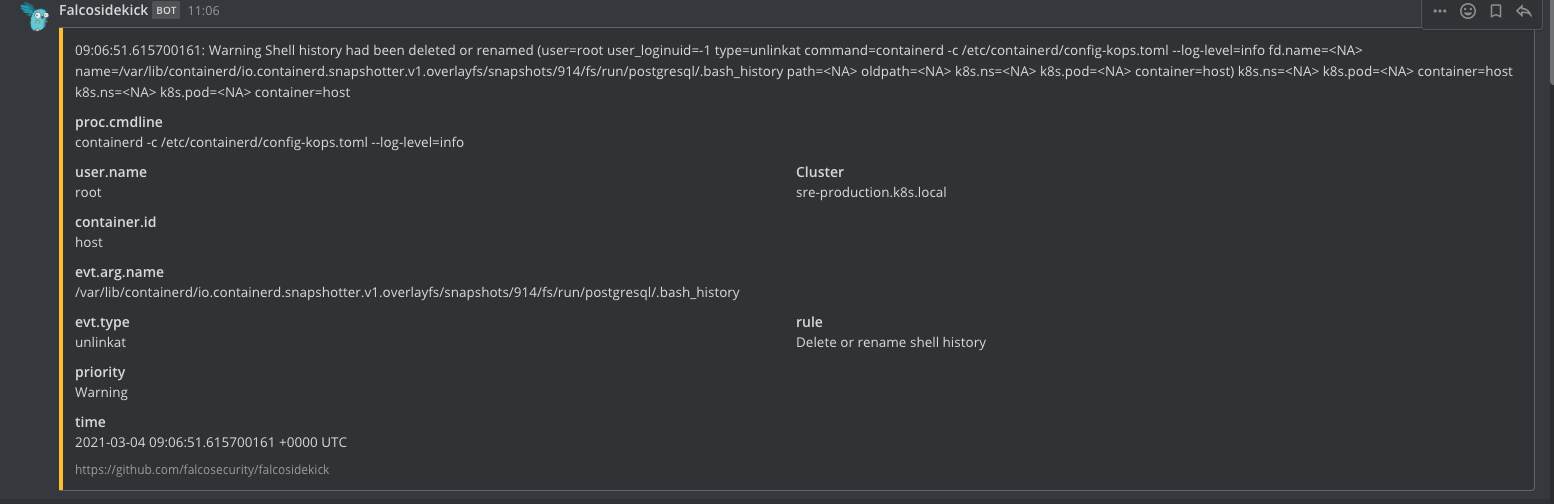
How to reproduce it
Install kubernetes cluster with manifests https://gist.github.com/zetaab/e134a6dbb80de296909a6d7ed34c3232
Expected behaviour
We expect that we could see kubernetes metadatas in events like it did work with docker.
Screenshots
Environment
Kubernetes cluster installed with kOps running in OpenStack / AWS
-
Falco version: 0.27.0
-
System info:
# falco --support | jq .system_info
{
"machine": "x86_64",
"nodename": "nodes-esptnl-rzkxpp",
"release": "4.19.0-13-cloud-amd64",
"sysname": "Linux",
"version": "#1 SMP Debian 4.19.160-2 (2020-11-28)"
}
- Cloud provider or hardware configuration: openstack / aws
- OS: debian buster
- Kernel: 4.19.0-13-cloud-amd64
- Installation method: kubernetes
Additional context
falco kubernetes installation manifests https://gist.github.com/zetaab/e134a6dbb80de296909a6d7ed34c3232
About this issue
- Original URL
- State: closed
- Created 3 years ago
- Comments: 25 (3 by maintainers)
not working containerd config:
working
so our way to fix this is to roll all machines in clusters.
For others that might have the same issue, I ran into this problem today, and it ended up being a misconfigured
containerd.socketwhen using k3s.Following the guidance from @holyspectral in this post (thank you), the
grpcurlwas returningconnection refused. The problem was the path to the socket. After figuring out the correct path I could then start falco with the correct settings and everything worked as it should. Here it the command I am using now:@leogr I have falco built from master branch with sysdig dev branch. The ebpf program is built from source and kernel header. They’re installed via helm.
ListContainers will return array of containers
one example:
btw executed this inside running falco container I also tried it locally in node. The result is same in both (when running in host I removed /host from start of the containerd sock path)
We are missing the metadata all the time.
As you can see from the gist provided in the issue, we have already check & tried the common problems. HOST_ROOT env variable is not an issue and neither is the async fetching, as toggling it on & off does not make a difference.
Are there any other details that you might need? We are running containerd v1.4.3.