SlowFast: Cannot reproduce the result on AVA
Hi, thank you for your great code base.
Now I’m trying to reproduce the result on AVA claimed in paper and tech report. However, I cannot reproduce the result. I chose configs/AVA/c2/SLOWFAST_32x2_R101_50_50.yaml configuration file for training. The modifications I did to this config file are: (Here, the commented are original settings.)
TRAIN:
ENABLE: True #False
DATASET: ava
BATCH_SIZE: 80 #16
EVAL_PERIOD: 2 # 1
CHECKPOINT_PERIOD: 1
AUTO_RESUME: True
CHECKPOINT_FILE_PATH: path to pretrain model downloaded from the third entry in this table(https://github.com/facebookresearch/SlowFast/blob/master/MODEL_ZOO.md#ava)
CHECKPOINT_TYPE: caffe2 # pytorch
DETECTION:
ENABLE: True
ALIGNED: True #False
#SOLVER:
# MOMENTUM: 0.9
# WEIGHT_DECAY: 1e-7
# OPTIMIZING_METHOD: sgd
SOLVER:
BASE_LR: 0.1
LR_POLICY: steps_with_relative_lrs
STEPS: [0, 20, 30]
LRS: [1, 0.1, 0.01, 0.001]
MAX_EPOCH: 40
MOMENTUM: 0.9
WEIGHT_DECAY: 1e-7
WARMUP_EPOCHS: 5
WARMUP_START_LR: 0.000125
OPTIMIZING_METHOD: sgd
As you can see, I modified the learning policy from cosine to steps_with_relative_lrs, which is stated in paper, with reference to the settings in https://github.com/facebookresearch/SlowFast/blob/a8a47ced376a681e76d8b904e7be76d67fe999b3/configs/AVA/SLOWFAST_32x2_R50_SHORT.yaml#L52-L62
However, the result is not good.
Below is the picture of training loss and mAP on val set,
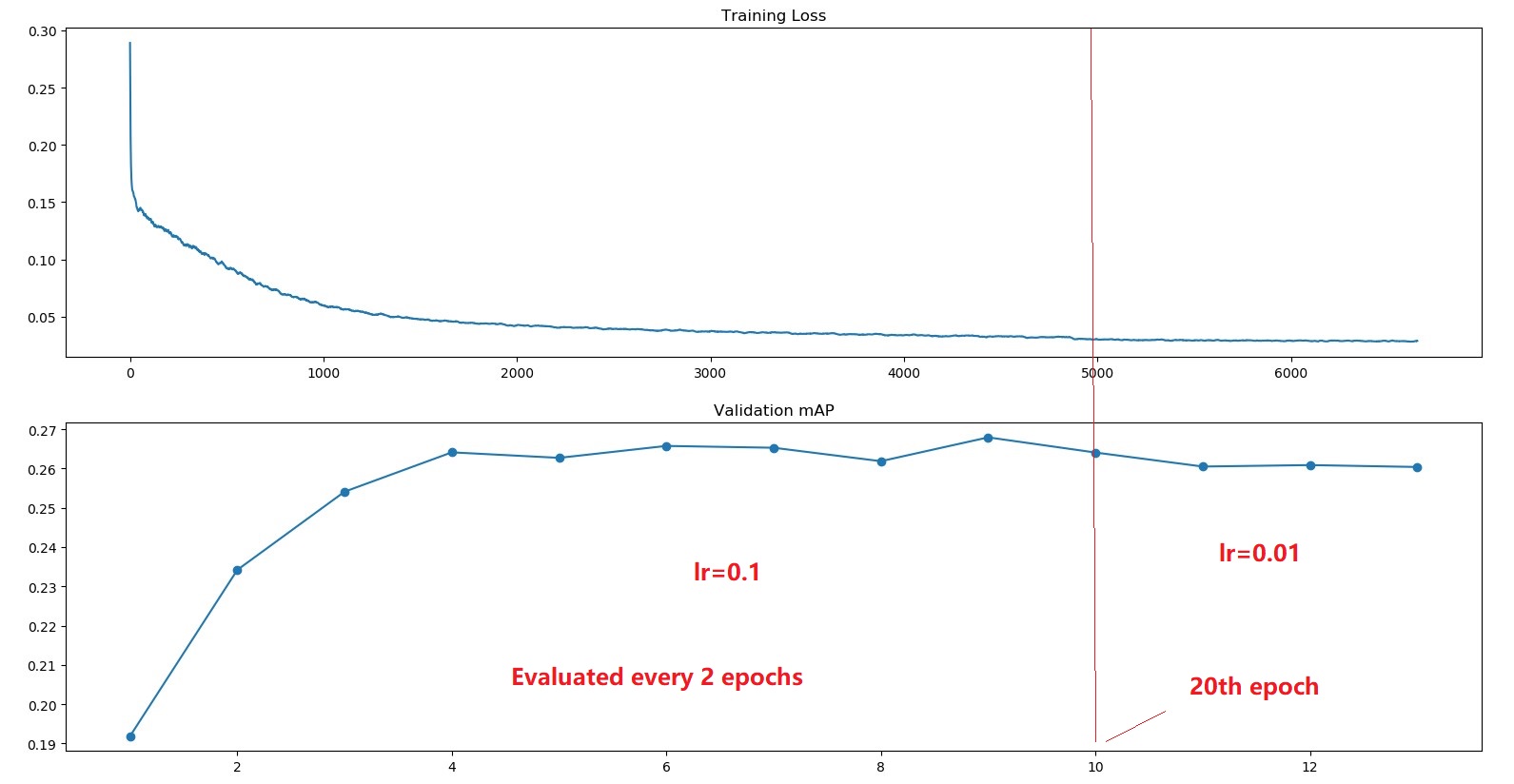
From the picture, we can find that the mAP on Val set saturates around 26 .0 quickly and cannot reach the value (29.0) stated in paper.
How do you think about this, is this because of the STEPS parameter I set that cause overfitting?
Thank you!
About this issue
- Original URL
- State: open
- Created 4 years ago
- Comments: 22 (9 by maintainers)
Hi, @takatosp1 @feichtenhofer.
I notice that in the paper of SlowFast, SlowFast-R101, 8x8, K600 achieves 29.0 on AVA-v2.2, and in the paper of X3D, the performance is reported as 27.4 for SlowFast-R101, 8x8, K600. What is the difference between their training and inference settings?
@chaoyuaw Training R101 model is time-consuming, I will report the performance of
SLOWFAST_32x2_R101_50_50once I finish the training. I have verified the configurationconfigs/AVA/SLOWFAST_32x2_R50_SHORT.yamland reported the performance in https://github.com/facebookresearch/SlowFast/issues/112.If some guys meet the similar problem, the training log and test log are listed here for reference.(I will update the performance for R101 later)
Hi @takatosp1 , thank you for your reply.
I’m training my model on a machine with 8 Quadro RTX 6000 GPUs (24G memory).
I noticed that in https://github.com/facebookresearch/SlowFast/blob/a8a47ced376a681e76d8b904e7be76d67fe999b3/configs/AVA/SLOWFAST_32x2_R50_SHORT.yaml#L1-L9
that batchsize is set to
64, since my batchsize is80, now I’m doing another training withwith the
calculated according to https://github.com/facebookresearch/SlowFast/blob/a8a47ced376a681e76d8b904e7be76d67fe999b3/configs/AVA/SLOWFAST_32x2_R50_SHORT.yaml#L52-L62 are these settings correct?
Besides, how is
ALIGNgoing to affect the performance? Are the models claimed in paper trained withALIGNset toTrueorFalse?Thank you for reminding. However, if so, there are no scripts for training with R101 model, right? It it OK if I modify the inference script for training?
Best regards!
Hi Thanks for playing with PySlowFast! I noticed you’ve change the batch size, as well as the ALIGN, they all affect the performance significantly. Also I am curious that how could you run a SlowFast R101 model with batch size of 80? Could you share me what are the number of GPUs you use?
btw, note that, for the scripts under
/c2/, they are script designed to use for inference.Hi
We haven’t release R101 training schedule and will do it later. Please not use Recipe under c2 for training since it is for inference only
@chaoyuaw Thanks for your reply, I have resolved the performance issue on my side. (#112)
I’m a bit confused. Why do we depend on the “coming soon” models? To reproduce the AVA mAP (e.g., the “29.1” and “29.4” in this table), shouldn’t we just use the pre-trained models provided by the “Pretrain Model” column (red box on the attached image) in the table?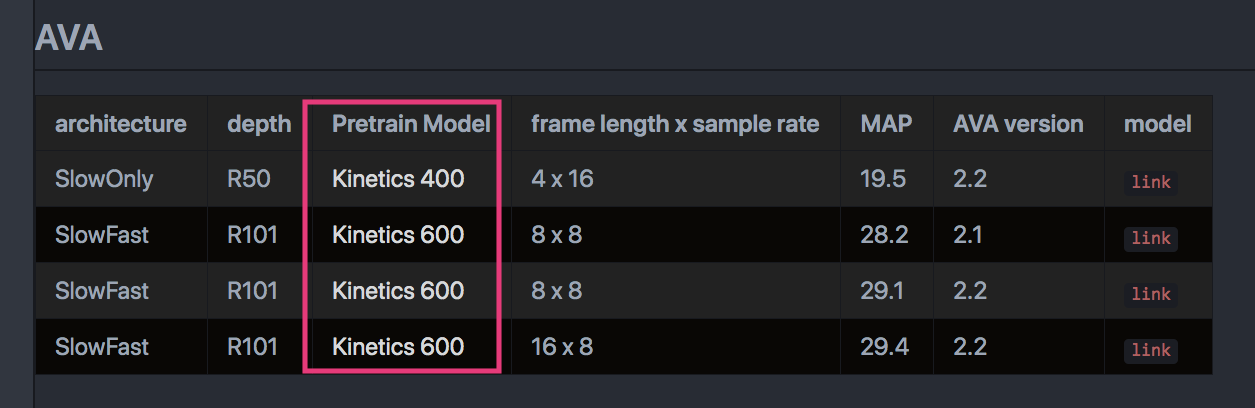
@takatosp1 Thanks. Also, can you explain the meaning of * in here? What’s the difference of used training region proposals?