spaCy: Segmentation fault on Ubuntu while training NER or TextCat
How to reproduce the behaviour
Hello! I’m coming across a segmentation fault while training a model for NER and text classifier. While I was training it exclusively on my local machine, this problem did not (and still do not) occur, it seems to appear only on my VMs. Here is the context: I want to train a lot of models, while making some slight variant on different parameters, as the dropout, the batch size, the number of iterations, etc. Also, for each different set of parameters, I train 10 models, in order to be sure that the good score of the model wasn’t some kind of luck. I first of all create a new blank model from a language:
nlp = spacy.blank("fr")
nlp.add_pipe(nlp.create_pipe(SENTENCIZER))
nlp.add_pipe(nlp.create_pipe(TAGGER))
nlp.add_pipe(nlp.create_pipe(PARSER))
nlp.begin_training()
I add the the newly created model some word vectors:
from gensim.models import FastText
gensim_model = FastText.load(vectors_dir)
gensim_model.init_sims(replace=True)
nr_dim = gensim_model.wv.vector_size
nlp.vocab.reset_vectors(width=nr_dim)
for word in gensim_model.wv.index2word:
vector = gensim_model.wv.get_vector(word)
nlp.vocab[word]
nlp.vocab.set_vector(word, vector)
I then call another python script to properly train the component I want, be it the NER or TextCat pipe. In this project, I have a custom “multi-ner” and “multi-textcat” to train each label as a separate submodel, as can be shown in the image:
 The training is done with 5000 sentences for the NER and 2000 for the TextCat, and while it demands a bit of RAM, it’s really nothing for the machines that have 16 Gigabytes.
After that, I modify the meta.json file in order to incorporate some project-related infos, and it’s done.
The training is done with 5000 sentences for the NER and 2000 for the TextCat, and while it demands a bit of RAM, it’s really nothing for the machines that have 16 Gigabytes.
After that, I modify the meta.json file in order to incorporate some project-related infos, and it’s done.
As I said, I want to train a lot of models, so I train series of 10 models (each series with the same parameters). The 10 models aren’t trained simultaneously but one after the other.
And here is the thing: while on my local machine I can train dozens of model without a single error, there is another behaviour on the VMs. After some training (usually I can train 2 models, so 2*20 iterations), I have a Segmentation Fault error. It’s always when I try to load the model, and it can be just before a training, or before the meta file changes.
I don’t really know how to investigate this error, and what I can do to solve it, any help or tip is welcome! 😃
I was trying to be as exhaustive as possible, but as I am quite a newbie at writing issues I may have missed some important info, do not hesitate in asking more detail or code preview!
Your Environment
I’m using 3 different VM to train simultaneously the models, and the configuration is slightly different from one to another, but the bug is the same. Here is also my local configuration, the errorless one. Each machine (VM or Local) has 16 Gigabytes RAM, and it appears to be more than enough.
| Info about spaCy | Local | VM 1 | VM 2 & 3 |
|---|---|---|---|
| spaCy version: | 2.2.4 | 2.2.4 | 2.2.4 |
| Platform: | Windows-10-10.0.17134-SP0 | Linux-4.4.0-62-generic-x86_64-with-Ubuntu-16.04-xenial | Linux-4.15.0-106-generic-x86_64-with-Ubuntu-18.04-bionic |
| Python version: | 3.6.5 | 3.6.5 | 3.6.9 |
About this issue
- Original URL
- State: closed
- Created 4 years ago
- Comments: 17 (10 by maintainers)
Thank you, it worked! Thanks for taking your time to help me find the problem
About the serialization of custom components, the documentation provides more information here:
That’s also pretty much what the error message says there. Have you tried implementing this so you can just save out the entire model in one go?
Hello, I’ve run some tests, and I hope the results will help us find the cause of the error. First of all, these are the tests I ran:
The word vectors, if not pruned, have 962148 vectors. There is 947364 keys. The models and their components were created locally on each machine. And now for the results:
Local
It really surprised me, because for the first time I had a memory error on my local Windows. Here is the stacktrace:
VM 1
I didn’t get any errors. It seems that creating the model and the components on the VM was a good call.
VM 2
I got another memory error.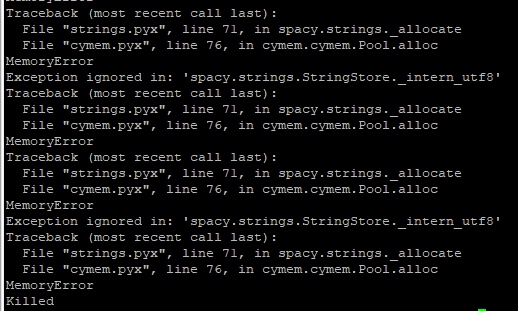 The stacktrace is full of this fragment, reiterated more than a hundred time - so much that I can’t scroll up to see what started it.
The stacktrace is full of this fragment, reiterated more than a hundred time - so much that I can’t scroll up to see what started it.
VM 3
Here I didn’t get
Segmentation fault (core dumped)nor aMemory Error, but justFor me the conclusion is that my word vectors are causing the error, because if they aren’t present, all seems to work perfectly (although I’ll run some other tests to be sure).