spaCy: 5-6x slower performance between v2 and v3
Regression
With Spacy 2 we’ve experienced 5-6 times faster processing of documents, with same model “size” (not transformer).
With nlp(text)
- In Spacy 2:
For text of length 789417 (~780KB) it takes ~56 seconds for full parseWith pipeline = [‘tagger’, ‘parser’, ‘ner’] - In Spacy 3:
For text of length 789417 (~780KB) it takes ~303 seconds for full parseWith pipeline = [‘tok2vec’, ‘tagger’, ‘parser’, ‘attribute_ruler’, ‘lemmatizer’, ‘ner’]
With nlp.pipe([chunks)] and 16 chunks
- In Spacy 2:
For text of length 789417 (~780KB) it takes ~38 seconds for full parse - In Spacy 3:
For text of length 789417 (~780KB) it takes ~203 seconds for full parse
How to reproduce the behaviour
Created a Colab with dropdown to choose Spacy ❤️ or >3 (Please choose “restart runtime and run” after switching between spacy versions) https://colab.research.google.com/drive/10XUpSQ6ir5-DttWJsUN5SjjVQfCDmglN?usp=sharing
I’ve plot the analyze time as relative to text length…
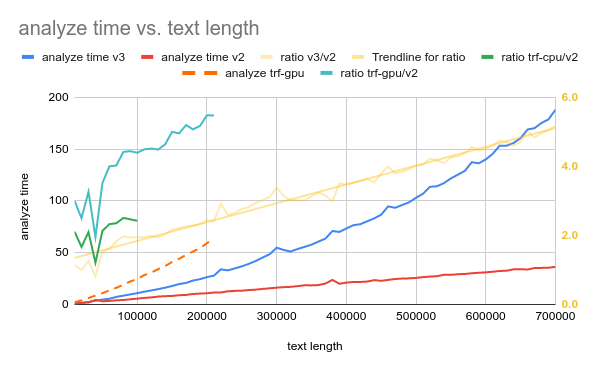 (ratio is attached to right axis, so it goes 2->3->4->5+)
(ratio is attached to right axis, so it goes 2->3->4->5+)
#@title Spacy 3 vs 2: benchmark large text
#@markdown **1. Download a rather large document**
import urllib
import urllib.request
large_text_file_url = "https://www.gutenberg.org/files/1342/1342-0.txt"
urllib.request.urlretrieve(large_text_file_url, "large.txt") # download
large_txt = urllib.request.urlopen(large_text_file_url).read().decode('utf-8')
print(f"Length of large_txt={len(large_txt)}")
text_to_parse_dropdown = "large" #@param ["large", "small"]
text_to_parse = large_txt if text_to_parse_dropdown == "large" else "Hello"
print(f"Length of text_to_parse={len(text_to_parse)}")
#@markdown **2. Install spacy, download model, import & load model**
spacy_version = "spacy\u003C3" #@param ["spacy\u003C3", "spacy>3"]
import os; os.environ["spacy_version"] = spacy_version
!pip install "$spacy_version"
!python -m spacy download en_core_web_md
import en_core_web_md
nlp = en_core_web_md.load()
#@markdown **3. Run full parse, benchmark**
import timeit
results = timeit.timeit(lambda: nlp(text_to_parse), number=3)
print(results)
print(f'For text of length {len(text_to_parse)} it took {results}')
results
Note: Disabling modules from Spacy 3 model doesn’t seem to help
(using disable = ['tok2vec', 'attribute_ruler', 'lemmatizer'] in colab)
Your Environment
- Operating System: Ubuntu / WSL@Windows / Colab - all reproduce
- Python Version Used: 2 / 3
- spaCy Version Used: 2.3 / 3.2
- Environment Information: Cloudy
About this issue
- Original URL
- State: closed
- Created 3 years ago
- Reactions: 2
- Comments: 18 (5 by maintainers)
Commits related to this issue
- Speed up the StateC::L feature function This function gets the n-th most-recent left-arc with a particular head. Before this change, StateC::L would construct a vector of all left-arcs with the given... — committed to danieldk/spaCy by danieldk 2 years ago
- Speed up the StateC::L feature function This function gets the n-th most-recent left-arc with a particular head. Before this change, StateC::L would construct a vector of all left-arcs with the given... — committed to danieldk/spaCy by danieldk 2 years ago
- Speed up the StateC::L feature function (#10019) * Speed up the StateC::L feature function This function gets the n-th most-recent left-arc with a particular head. Before this change, StateC::L w... — committed to explosion/spaCy by danieldk 2 years ago
- Speed up the StateC::L feature function (#10019) * Speed up the StateC::L feature function This function gets the n-th most-recent left-arc with a particular head. Before this change, StateC::L w... — committed to danieldk/spaCy by danieldk 2 years ago
- Use constant-time head lookups in StateC::{L,R} This change changes the type of left/right-arc collections from vector[ArcC] to unordered_map[int, vector[Arc]], so that the arcs are keyed by the head... — committed to danieldk/spaCy by danieldk 2 years ago
- Use constant-time head lookups in StateC::{L,R} This change changes the type of left/right-arc collections from vector[ArcC] to unordered_map[int, vector[Arc]], so that the arcs are keyed by the head... — committed to danieldk/spaCy by danieldk 2 years ago
- Speed up the StateC::L feature function (#10019) * Speed up the StateC::L feature function This function gets the n-th most-recent left-arc with a particular head. Before this change, StateC::L w... — committed to polm/spaCy by danieldk 2 years ago
Fixed by #10048.
Sorry for the delay. We are looking into this, but the holidays have delayed this a bit, but it’s definitely on our radar.