etcd: ETCD fails to come up when using CIFS file share (as etcd storage) and with cache=none in mount option
What happened?
I had etcd:3.4.15-debian-10-r43 running and mounted a cifs file sharing with below mount option. Please note cache=none
rw,relatime,vers=3.1.1,cache=none,username=myname,uid=0,noforceuid,gid=1001,forcegid,addr=1.10.90.14,file_mode=0777,dir_mode=0777,soft,persistenthandles,nounix,serverino,mapposix,mfsymlinks,rsize=1048576,wsize=1048576,bsize=1048576,echo_interval=60,actimeo=30
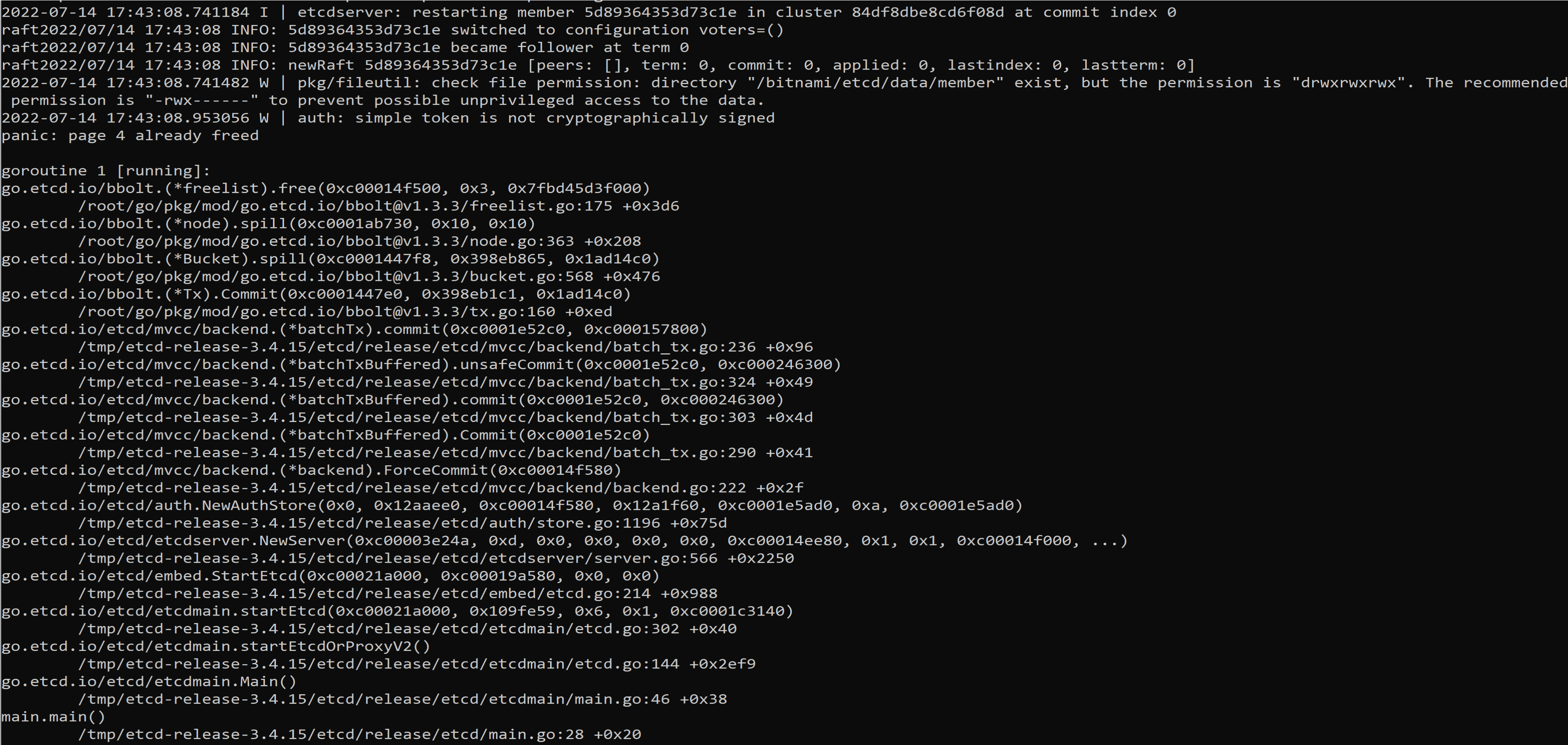
The etcd is failing to comeup with below panic
Since per discussion in https://github.com/etcd-io/etcd/issues/9670 , I tried cache=none for cifs. With same mount option, if I make it cache=strict, everything works fine.
What did you expect to happen?
Etcd must not panic
How can we reproduce it (as minimally and precisely as possible)?
Its very straightforward with the given mount option
Anything else we need to know?
No response
Etcd version (please run commands below)
$ etcd --version
# paste output here
$ etcdctl version
# paste output here
etcdctl version: 3.4.15 API version: 3.4
Etcd configuration (command line flags or environment variables)
paste your configuration here
Etcd debug information (please run commands blow, feel free to obfuscate the IP address or FQDN in the output)
$ etcdctl member list -w table
# paste output here
$ etcdctl --endpoints=<member list> endpoint status -w table
# paste output here
Relevant log output
In the screenshot
About this issue
- Original URL
- State: closed
- Created 2 years ago
- Comments: 23 (7 by maintainers)
Just FYI
https://bugzilla.kernel.org/show_bug.cgi?id=216301
Thank you @ahrtr for sharing. I think that confirms.
I am planning to close the issue because WAL cover up the main reason (data loss) and trying to disable the cache. I will wait for a week and close. Please let me know if any one think that I need to keep this open.
Its the same
@hasethuraman @tjungblu could you try to reproduce this issue with etcd 3.5.4?
hey @hasethuraman,
I’ve been looking a bit into this today, since I have a samba share at home and wanted to debug bbolt a little. I don’t have a fix for you just yet, but I just want to mentally write down what I found so far.
The panic can be easily reproduced by running this simple test case on the share: https://github.com/etcd-io/bbolt/blob/master/manydbs_test.go#L33-L60
The panic is caused by a bucket that is not found after it was created in this method: https://github.com/etcd-io/bbolt/blob/master/bucket.go#L165-L183
The cursor seek does not return an existing bucket for the root node, thus it will create a new one with the same page id, which causes the panic on the freelist.