duckdb: Too large parquet files via "COPY TO"
What happens?
Using “COPY TO” query produces much larger parquet files compared to pyarrow.parquet.write_table().
To Reproduce
import pandas as pd
import duckdb
from pyarrow import parquet as pq
# Create dataset
n = 100_000
df = pd.DataFrame({"x": [0, 0, 1.1, 1.1, 2] * n, "y": ["A", "A", "A", "B", "B"] * n})
print(df.shape)
con = duckdb.connect()
# Query to arrow, then write to parquet -> 0.6 seconds
df_arrow = con.execute("SELECT * FROM df").fetch_arrow_table()
pq.write_table(df_arrow, "df_arrow.parquet")
# Copy to parquet -> 3.3 seconds
con.execute("COPY (SELECT * FROM df) TO 'df_duckdb.parquet' (FORMAT 'parquet')")
con.close()
# Check results
print(pd.read_parquet("df_duckdb.parquet").head())
print(pd.read_parquet("df_arrow.parquet").head())
The resulting file size:
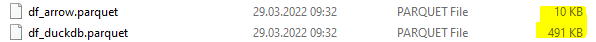
Note: The approach via fetch_arrow_table() is also much faster.
Environment (please complete the following information):
- OS: Windows 10
- DuckDB Version: 0.3.2
- DuckDB Client: Python
About this issue
- Original URL
- State: open
- Created 2 years ago
- Reactions: 1
- Comments: 22 (2 by maintainers)
Is there any more understanding on this issue? I find the serialized size is about a factor of 3 bigger for duckdb
With duckdb 0.5, this got a little better (~factor of 2):
Regrettably, I don’t yet have experience with this; however, on the writing side, these two leads from the documentation might be helpful:
🤔 https://arrow.apache.org/blog/2019/09/05/faster-strings-cpp-parquet/