SqlClient: Execution Timeout Expired Error (258, ReadSniSyncOverAsync)
Describe the bug
When executing SQL such as SELECT FieldA, FieldB FROM A INNER JOIN C ON A.FieldId = C.FieldId UNION SELECT FieldA, FieldD FROM A INNER JOIN D ON A.FieldId = D.FieldId, throw the error like below, not every time, just a little part of queries have this issue.
Microsoft.Data.SqlClient.SqlException (0x80131904): Execution Timeout Expired. The timeout period elapsed prior to completion of the operation or the server is not responding.\n
---> System.ComponentModel.Win32Exception (258): Unknown error 258\n
at Microsoft.Data.SqlClient.SqlInternalConnection.OnError(SqlException exception, Boolean breakConnection, Action1 wrapCloseInAction)\n
at Microsoft.Data.SqlClient.TdsParser.ThrowExceptionAndWarning(TdsParserStateObject stateObj, Boolean callerHasConnectionLock, Boolean asyncClose)\n
at Microsoft.Data.SqlClient.TdsParserStateObject.ReadSniError(TdsParserStateObject stateObj, UInt32 error)\n
at Microsoft.Data.SqlClient.TdsParserStateObject.ReadSniSyncOverAsync()\n
at Microsoft.Data.SqlClient.TdsParserStateObject.TryReadNetworkPacket()\n
at Microsoft.Data.SqlClient.TdsParserStateObject.TryPrepareBuffer()\n
at Microsoft.Data.SqlClient.TdsParserStateObject.TryReadByteArray(Span1 buff, Int32 len, Int32& totalRead)\n
at Microsoft.Data.SqlClient.TdsParser.TrySkipValue(SqlMetaDataPriv md, Int32 columnOrdinal, TdsParserStateObject stateObj)\n
at Microsoft.Data.SqlClient.TdsParser.TrySkipRow(SqlMetaDataSet columns, Int32 startCol, TdsParserStateObject stateObj)\n
at Microsoft.Data.SqlClient.TdsParser.TryRun(RunBehavior runBehavior, SqlCommand cmdHandler, SqlDataReader dataStream, BulkCopySimpleResultSet bulkCopyHandler, TdsParserStateObject stateObj, Boolean& dataReady)\n
at Microsoft.Data.SqlClient.SqlDataReader.TryReadInternal(Boolean setTimeout, Boolean& more)\n
at Microsoft.Data.SqlClient.SqlDataReader.ReadAsync(CancellationToken cancellationToken)\n
--- End of stack trace from previous location where exception was thrown ---\n
at Dapper.SqlMapper.QueryAsync[T](IDbConnection cnn, Type effectiveType, CommandDefinition command) in //Dapper/SqlMapper.Async.cs:line 437\n
To reproduce
Sorry, currently can’t reproduce in the local environment, so can’t provide more detail to reproduce.
Expected behavior
SQL should execute successfully every time.
Further technical details
Microsoft.Data.SqlClient version: 1.1.3 .NET target: Core 3.1 Operating system: Docker container
What I found/tried
About this issue
- Original URL
- State: open
- Created 4 years ago
- Reactions: 14
- Comments: 145 (31 by maintainers)
I have found reason for my case. I’m sorry, but that were number of bad performing queries - doing either index or table scan with several dozen millions rows. It was really hard to catch, as those happened 1-2 times per hour and were not affecting anyhow used memory (30% free) or CPU (max 20% usage). Those scans were overloading disk system and harming SQL server caches. So even after query run there were problems in next 5-10 minutes - due to missing data in cache, even for usually good performing queries SQL server had to read too much things from disk and therefore queries were timing-out.
Guys, check your queries. This SQL script gives you those, which had to read lot of data
SELECT SUBSTRING(qt.TEXT, (qs.statement_start_offset/2)+1, ((CASE qs.statement_end_offset WHEN -1 THEN DATALENGTH(qt.TEXT) ELSE qs.statement_end_offset END - qs.statement_start_offset)/2)+1) as [Text], qs.execution_count, qs.total_logical_reads, qs.last_logical_reads, qs.total_logical_writes, qs.last_logical_writes, qs.total_worker_time, qs.last_worker_time, qs.total_elapsed_time/1000000 total_elapsed_time_in_S, qs.last_elapsed_time/1000000 last_elapsed_time_in_S, qs.last_execution_time, qp.query_plan FROM sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) qt CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) qp ORDER BY qs.total_logical_reads DESCIn my last post I guessed the 258 error occurs because of full tcp buffers and wrong tcp socket handling on linux (see my previous post above). Further investigation made me more confident that this is the case.
The additional queue I added (last post) helped a bit, but after adding more features (service implementations) to our host process the error came back quite frequently.
Because most 258 errors occured in DbContext.SaveChanges() I synchronized calls in my DbContext base implementation like this:
This dirty code slowed down my execution flow and helped reducing the 258 errors. But like others reported here about disabling MARS it did not solve the problem completly.
I examined that the problem occurs often during extensive external web API rest calls. So I synchronized them as well:
No parallel web calls helped a lot and made me sure the error is related to the current tcp buffer usage within the application.
I guess the error originates in some way like this:
Slowing down the execution flow and hoping not reaching tcp buffer limits is not a production ready workaround 😃 I wonder if this is a common problem for all high tcp i/o apps running on Linux and connecting to Sql Server?
This error occured some time after upgrading ef core (not sure which .net core/ef core version). My application runs currently on:
Used SQL Server: Latest SQL Server 2019 Docker container
Side notes:
dotnet-trace collect --process-id 27455 --profile databasebut the results did not include the expected events.This sounds like a thread starvation issue with the system thread pool. This is known issue when running asynchronously with Microsoft.Data.SqlClient on .NET Core and it’s in our backlog to make it fully asynchronous which will require a big refactor. You might be able to work around this by setting the ThreadPool.SetMinThreads to a high enough value to accommodate, but with many parallel tasks, there’ll be more overhead to allow for continuation tasks inside of SqlClient to run before the timeouts are hit.
We are also experiencing this issue with Linux App Services against Azure SQL. We only began seeing this after migrating our App Services from Windows to Linux. Also on 5.1.1 of SqlClient.
@Malgefor Convert all asynchronous SQL calls into synchronous ones, and everything will be sorted 😃
A few days ago we’ve found the solution for our case. If you are using Azure Load Balancer + SQL Database (or SQL Pool) in a VNET, check if your configuration for outbound connections is set to use the Azure Private Network, otherwise, you could be running into SNAT Port Exhaustion.
To check if that’s the case, go to the Load Balancer resource page, Metrics, and show SNAT Connection Count, filter for failed Statuses.
Another solution is to use more Outbound IPs.
最近观察到业务高峰期会有大量的Unknown error 258,在数据库服务器上观测到cpu 100%,是由 sql server windows nt -64bit 占用 98%+ 没有死锁 使用 select * from master.dbo.sysprocesses 查询到连接数在300左右 当前系统有 170左右 当前系统数据库连接串: Data Source=xxxxxxx,15726;Initial Catalog=xxxxx;Persist Security Info=True;User ID=xxxx;Password=xxxxxx;Integrated Security=false;Connect Timeout=30;MultipleActiveResultSets=false
有两个大并发业务连接到这台数据库 因为一些sql语句 较慢,经过优化后,今天再次使用 select * from master.dbo.sysprocesses 查询当前连接在 60左右,已经没有Unknown error 258 的记录了
同时:数据库的最大连接数设置为0
Is this happening on Azure platform for everyone? Getting same issue with and without MARS, Linux App Service (docker) + Azure SQL.
Related: https://github.com/Azure/aks-engine/issues/4341 ?
This is happening randomly across out systems. You do typically see it on applications that cause higher loads or on SQL Server instances that are under higher load.
There is nothing special in particular about the applications that experience this. It’s happening on both
System.Data.SqlClientandMicrosoft.Data.SqlClient. AFAICT it is not happening on .NET Framework/Windows (we do not run any .NET Core applications of note on Windows).I am currently migrating one application that experiences this regularly to .NET 5. Will let you know if that changes anything.
My platform Infrastructure: Docker in Redhat Enterprise Language & Framework: .Net 6 with Entity Framework core Database: SQL Server
After optimizing my API and implementing ‘async’ and ‘await’ with ‘Task’, all the errors have disappeared. Also i set maximum and minimum pooling and connection life cycle
Experienced a flavor of this issue. When inserting singular records in intervals of a few seconds in concurrently running applications. Each application operating on their own instance of DbContext and no concurrent use inside their scope.
Packages Microsoft.Data.SqlClient 5.0.1 Microsoft.EntityFrameworkCore.SqlServer 6.0.10
Exception
Client .NET 6.0 application implemented as BackgroundService.
Error occured on
Last EF generated SQL command before this exception was thrown
Database SQL Server 2016
Resolution for now Optimizing expensive read queries as much as possible that affected the table. After optimizing heavier read queries, I haven’t seen this error.
I had several applications concurrently using the database for one expensive read query each on startup, and then making inserts on same tables (not same records). Each had their own scoped instance of DbContext. The issue seemed to come when inserts were occurring to a table that was under a heavy read query by another process. Small percentage of inserts resulted in this error. Enabling retries didn’t seem to help.
@ErikEJ Upgrading Microsoft.Data.SqlClient to 4.1.0 and Microsoft.Data.SqlClient.SNI to 4.0.0 solved the problem… Thanks. They were buried among a couple other packages that I can’t upgrade, that’s why I didn’t see that they were so outdated…
My suggestion is create a singleton service serving only one instance of HttpClient.
Without wanting to reveal too much about our infrastructure setup on a public domain, We see this error pretty consistently when load testing a web api, that inserts a large volume of data into an azure sql database.
Details that might hopefully enable a repo:
At the time of the error, for example, below at 3:18pm, the cpu and io usage of the sql servelerless resource are both between 70-80% and the CPU usage on the node running the docker container is 100%
So I am assuming @bennil may be on to something given this is happening in high load, high concurrency scenarios only for us, where CPU usage is pushed to the limit.
@jslaybaugh / @cheenamalhotra: Quick Update:
The issue is environmental.
If you ssh onto the AKS node and have a look at the /var/log/syslog (or syslog.1) you should see “eth0: Lost carrier” messages. It appears to be related to this Azure issue. A fix is being rolled out at the moment.
Hello,
I experience same problems without MARS and with no DbContext pooling. Here is my connection string:
Data Source=server_IP;Initial Catalog=my_db;User ID=my_user;Password=my_password;Max Pool Size=200DbContext:
services.AddDbContext<MyDbContext>(o => { o.UseSqlServer(Configuration.GetConnectionString("MyDbContext")); o.EnableSensitiveDataLogging(); }, ServiceLifetime.Transient);我将db connection 中改了
MultipleActiveResultSets=false后,此问题彻底消失了@Mewriick , @mcanerim are you using System.Data.SqlClient? The stack trace you have provided is from that library not Microsoft.Data.SqlClient which the original issue was opened for.
So I have migrated one of the applications to .NET 5 and deployed it to our production environment. It is running there only for half a day now but so far the issue is gone. I have even been able to decrease connection timeout from 2 minutes to 5 seconds.
So I would say give .NET 5 a try.
@JRahnama , I found one command that wasn’t wrapped in using block. I will deploy the fix and try to monitor if it helped or not.
Thanks, @ericstj, No, I didn’t try increasing command timeout. Currently, the command timeout is 3s. If a query executes timeout, I got stack like below, seems it is different than the above stack, do you mean the above stack is also a SQL execution timeout? By the way, from New relic, the select query’s duration is 83.4ms, I’m not sure if it is the execution time.
In our case the problem has now as mysteriously disappeared as it has mysteriously appeared. The only change we made was migrate to a different virtual machine than the previous SQL Server was running on.
By taking some packet captures by logging in with ssh on the Linux Web App, and typing
ip ato get the interface name and thentcpdump -i vnet0g6qkt5hl -w ~/network_traces/0001.pcapwe noticed something strange while the problem was still occurring.A packet containing a SQL query that in the tcpdump was registered with size 2130 bytes and data length 2064 was being “partially acked”. After sending the large packet out, the ACK came back only for the first 1398 bytes, causing a retransmission of the last 666 bytes. However, in response to this retransmission only came another ACK for only the first 1398 bytes, causing another retransmission of the last 666 bytes, and so on and so forth, until eventually the connection timed out. Rather than a threading issue this potentially seems like some kind of network layer problem. However, we can no longer reproduce it, so it’s difficult to investigate more deeply.
As @dazinator already suggested our particular problem was probably something entirely different than what this ticket is about. The 258 timeout error is fairly general - it just means that some kind of wait operation timed out and it can have multiple different underlying causes. Sorry for the noise.
For us, increasing the threadpool threads eliminated this issue. We’re still on linux and are not seeing this (anymore)
When will this major years old linux issue be fixed? Using MS-SQL Docker on Linux fells like MySQL in the nineties.
@lcheunglci Apologies, the error I am seeing is a 258, but it’s not the “ReadSniSyncOverAsync” variety. It’s actually this one here: https://github.com/dotnet/SqlClient/issues/1530 will move my comments there
I am having this issue intermittently with a .net 6.0 app running in containers on Azure Kubernetes Service accessing an on prem SQL Server,
I am using Micrsooft.Data.SqlClient.dll v5.0.0.
The Microsoft.Data.SqlClient.SNI.dll is only in the directory runtimes\win-*\native so I assume it isn’t going to get loaded
I have checked the SNAT Connection Count where the State is Failed and there are none.
We are genuinely considering either changing the hosting off linux hosts or more likely, swapping to a different DB tech as this is such a problem.
@MarvinNorway which Microsoft.Data.SqlClient version - and have you tried 4.1?
查看图片: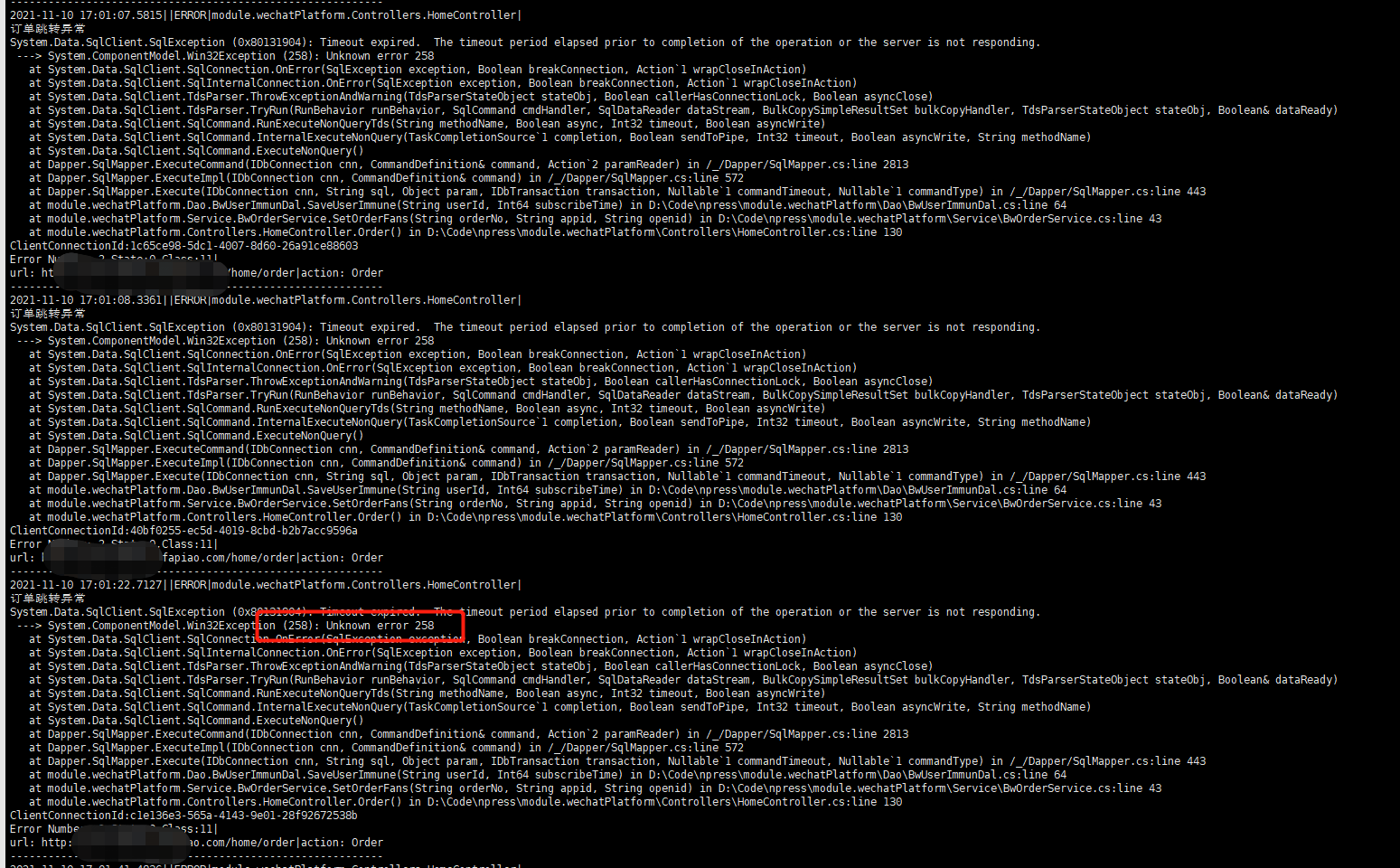
并不是,是因为我使用update 锁了整个表才导致cpu 100%的
Just want to add that we significantly reduced the chance of running into this problem by not using MARS. Previously we had same issue with or without MARS, but it turned out that we are using KeyVault and the secrets are cached for 24h. Only adding a dummy change to appSettings and saving it would clear the cache.
I’m going to try the last prerelease that includes #920 fix that resolves similar issue #672. I’ll update you on the result.
@cheenamalhotra Will monitor 1.1.4 in prod tomorrow and revert with more detail. Loads are low at the moment, so not experiencing any issues. Yes, I can share a private repo.
We’re having similar issues. It happened out of the blue last week and then again this morning. Suddenly these timeouts start piling up and our DTU’s spike to 100% and stay there.
Unfortunately, the only thing that seems to fix this for us is manually scaling up our tier in SQL Azure. We generally run at a P4. So we simply bump it to the next one (P6) and then its fine, even when we immediately bump it back down to the P4. It is like something just gets “stuck” and there is no way to remedy it without scaling the SQL server. Which sucks because who knows when it is going to happen. Here’s a sample stack trace:
Here’s an example of the DTU’s… everything is trucking along normal and then it starts to go nuts and then around the time in the morning that business starts picking up, we’re at 100% till we finally bounce the tier and then it more or less goes back to normal 😖
Also opened a ticket with Azure support to see if they can help diagnose from their end.
那么问题应该怎样解决?我的程序是在插入的时候报错。在高负载的情况下
System.Data.SqlClient.SqlException (0x80131904): Timeout expired. The timeout period elapsed prior to completion of the operation or the server is not responding. ---> System.ComponentModel.Win32Exception (258): Unknown error 258 at System.Data.SqlClient.SqlInternalConnection.OnError(SqlException exception, Boolean breakConnection, Action1 wrapCloseInAction) at System.Data.SqlClient.TdsParser.ThrowExceptionAndWarning(TdsParserStateObject stateObj, Boolean callerHasConnectionLock, Boolean asyncClose) at System.Data.SqlClient.TdsParserStateObject.ReadSniError(TdsParserStateObject stateObj, UInt32 error) at System.Data.SqlClient.TdsParserStateObject.ReadSniSyncOverAsync() at System.Data.SqlClient.TdsParserStateObject.TryReadNetworkPacket() at System.Data.SqlClient.TdsParserStateObject.TryPrepareBuffer() at System.Data.SqlClient.TdsParserStateObject.TryReadByte(Byte& value) at System.Data.SqlClient.TdsParser.TryRun(RunBehavior runBehavior, SqlCommand cmdHandler, SqlDataReader dataStream, BulkCopySimpleResultSet bulkCopyHandler, TdsParserStateObject stateObj, Boolean& dataReady) at System.Data.SqlClient.SqlDataReader.TryConsumeMetaData() at System.Data.SqlClient.SqlDataReader.get_MetaData() at System.Data.SqlClient.SqlCommand.FinishExecuteReader(SqlDataReader ds, RunBehavior runBehavior, String resetOptionsString) at System.Data.SqlClient.SqlCommand.RunExecuteReaderTds(CommandBehavior cmdBehavior, RunBehavior runBehavior, Boolean returnStream, Boolean async, Int32 timeout, Task& task, Boolean asyncWrite, SqlDataReader ds) at System.Data.SqlClient.SqlCommand.ExecuteReader(CommandBehavior behavior) at Dapper.SqlMapper.ExecuteReaderWithFlagsFallback(IDbCommand cmd, Boolean wasClosed, CommandBehavior behavior) in C:\projects\dapper\Dapper\SqlMapper.cs:line 1060 at Dapper.SqlMapper.ExecuteReaderImpl(IDbConnection cnn, CommandDefinition& command, CommandBehavior commandBehavior, IDbCommand& cmd) in C:\projects\dapper\Dapper\SqlMapper.cs:line 2856 `Any progress?
@JRahnama , If I didn’t miss something, all
SqlCommandsin my code are wrapped inusingblock.