runtime: Performance degradation dotnet core 2.1.300 TieredCompilation
I am very excited about Tiered Compilation in dotnet core so I decided to take it for a spin. Unfortunately in my case I found a performance degradation from 370 ms to 540 ms
My dotnet version:
> dotnet --version
2.1.300
My use-case
I am tinkering with a push stream in F#. Push streams are faster than Pull streams (like LINQ). One area where .NET JIT loses against JVM JIT is that .NET JIT is less keen on inlining. With Tiered Compilation I was hoping to see improved inlining improving performance.
Essentially the degradation seems to boil down to that there is an extra jmp in the call chain (as far as I understood this is due to the new jitter introducing an level stub to track stats). I was expected this jmp being eliminated after warmup phase. As the stub don’t do any stats tracking it seems to be the final optimized stub to me.
Finally time for some assembly code:
; Top level loop, this identical regardless of COMPlus_TieredCompilation
00007ffc`d5d88ece 3bdf cmp ebx,edi
00007ffc`d5d88ed0 7f13 jg 00007ffc`d5d88ee5
00007ffc`d5d88ed2 488bce mov rcx,rsi
00007ffc`d5d88ed5 8bd3 mov edx,ebx
00007ffc`d5d88ed7 488b06 mov rax,qword ptr [rsi]
00007ffc`d5d88eda 488b4040 mov rax,qword ptr [rax+40h]
; Virtual call to next step in the push stream
00007ffc`d5d88ede ff5020 call qword ptr [rax+20h]
00007ffc`d5d88ee1 ffc3 inc ebx
00007ffc`d5d88ee3 ebe9 jmp 00007ffc`d5d88ece
; The virtual call ends up here which seems left overs from the stats tracking stub.
; This is not present when COMPlus_TieredCompilation=0
00007ffc`d5d88200 e9bb080000 jmp 00007ffc`d5d88ac0
; The next step in the push stream
00007ffc`d5d88ac0 488b4908 mov rcx,qword ptr [rcx+8] ds:0000023a`000124c0=0000023a000124a0
00007ffc`d5d88ac4 4863d2 movsxd rdx,edx
00007ffc`d5d88ac7 488b01 mov rax,qword ptr [rcx]
00007ffc`d5d88aca 488b4040 mov rax,qword ptr [rax+40h]
00007ffc`d5d88ace 488b4020 mov rax,qword ptr [rax+20h]
00007ffc`d5d88ad2 48ffe0 jmp rax
So with Tiered compilation I was hoping for the virtual call to be eliminated (as is the case in JVM JIT) instead I got a performance degradation from 370 ms to 540 ms.
Perhaps I should wait for some more detailed posts on Tiered Compilation as promised here: https://blogs.msdn.microsoft.com/dotnet/2018/05/30/announcing-net-core-2-1/
However, I am quite excited about Tiered Compilation so I wanted to get an early start. Hopefully you tell me I made a mistake.
My F# code:
module TrivialStream =
// The trivial stream is a very simplistic push stream that doesn't support
// early exits (useful for first)
// The trivial stream is useful as basic stream to measure performance against
type Receiver<'T> = 'T -> unit
type Stream<'T> = Receiver<'T> -> unit
module Details =
module Loop =
// This way to iterate seems to be faster in F#4 than a while loop
let rec range s e r i = if i <= e then r i; range s e r (i + s)
open Details
// Sources
let inline range b s e : Stream<int> =
fun r -> Loop.range s e r b
// Pipes
let inline filter (f : 'T -> bool) (s : Stream<'T>) : Stream<'T> =
fun r -> s (fun v -> if f v then r v)
let inline map (m : 'T -> 'U) (s : Stream<'T>) : Stream<'U> =
fun r -> s (fun v -> r (m v))
// Sinks
let inline sum (s : Stream<'T>) : 'T =
let mutable ss = LanguagePrimitives.GenericZero
s (fun v -> ss <- ss + v)
ss
module PerformanceTests =
open System
open System.Diagnostics
open System.IO
let now =
let sw = Stopwatch ()
sw.Start ()
fun () -> sw.ElapsedMilliseconds
let time n a =
let inline cc i = GC.CollectionCount i
let v = a ()
GC.Collect (2, GCCollectionMode.Forced, true)
let bcc0, bcc1, bcc2 = cc 0, cc 1, cc 2
let b = now ()
for i in 1..n do
a () |> ignore
let e = now ()
let ecc0, ecc1, ecc2 = cc 0, cc 1, cc 2
v, (e - b), ecc0 - bcc0, ecc1 - bcc1, ecc2 - bcc2
let trivialTest n =
TrivialStream.range 0 1 n
|> TrivialStream.map int64
|> TrivialStream.filter (fun v -> v &&& 1L = 0L)
|> TrivialStream.map ((+) 1L)
|> TrivialStream.sum
let imperativeTest n =
let rec loop s i =
if i >= 0L then
if i &&& 1L = 0L then
loop (s + i + 1L) (i - 1L)
else
loop s (i - 1L)
else
s
loop 0L (int64 n)
let test (path : string) =
printfn "Running performance tests..."
let testCases =
[|
// "imperative" , imperativeTest
"trivialpush" , trivialTest
|]
do
let warmups = 100
printfn "Warming up..."
for name, a in testCases do
time warmups (fun () -> a warmups) |> ignore
use out = new StreamWriter (path)
let write (msg : string) = out.WriteLine msg
let writef fmt = FSharp.Core.Printf.kprintf write fmt
write "Name\tTotal\tOuter\tInner\tElapsed\tCC\tCC0\tCC1\tCC2\tResult"
let total = 100000000
let outers =
[|
10
1000
1000000
|]
for outer in outers do
let inner = total / outer
for name, a in testCases do
printfn "Running %s with total=%d, outer=%d, inner=%d ..." name total outer inner
let v, ms, cc0, cc1, cc2 = time outer (fun () -> a inner)
let cc = cc0 + cc1 + cc2
printfn " ... %d ms, cc=%d, cc0=%d, cc1=%d, cc2=%d, result=%A" ms cc cc0 cc1 cc2 v
writef "%s\t%d\t%d\t%d\t%d\t%d\t%d\t%d\t%d\t%d" name total outer inner ms cc cc0 cc1 cc2 v
printfn "Performance tests completed"
[<EntryPoint>]
let main argv =
// printfn "Attach debugger and hit a key"
// System.Console.ReadKey () |> ignore
PerformanceTests.test "perf.tsv"
0
About this issue
- Original URL
- State: closed
- Created 6 years ago
- Reactions: 1
- Comments: 24 (17 by maintainers)
Apps that rely heavily on prejitted code will see faster startup and better steady state performance. For example, on the ASP.Net sample music store app, about 20% faster first response, and 20% better overall throughput. In charts below, lower is better (y axis is time), and green line/dots are from runs with tiered jitting enabled.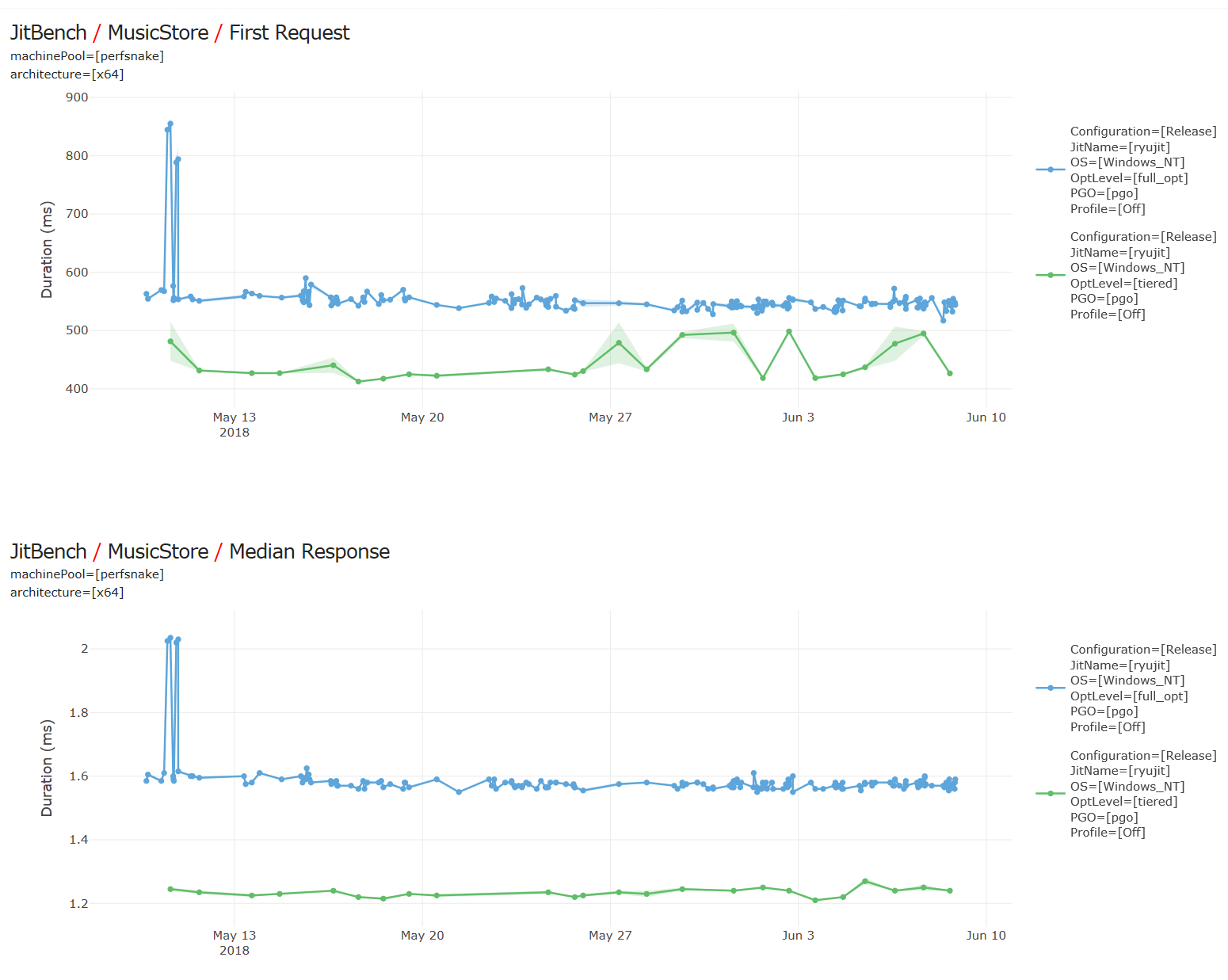 Startup wins come from faster initial jitting (as not all methods can be prejitted). Steady state wins because jitted code has better perf than prejitted code (fewer indirections, more inlining, etc).
Startup wins come from faster initial jitting (as not all methods can be prejitted). Steady state wins because jitted code has better perf than prejitted code (fewer indirections, more inlining, etc).