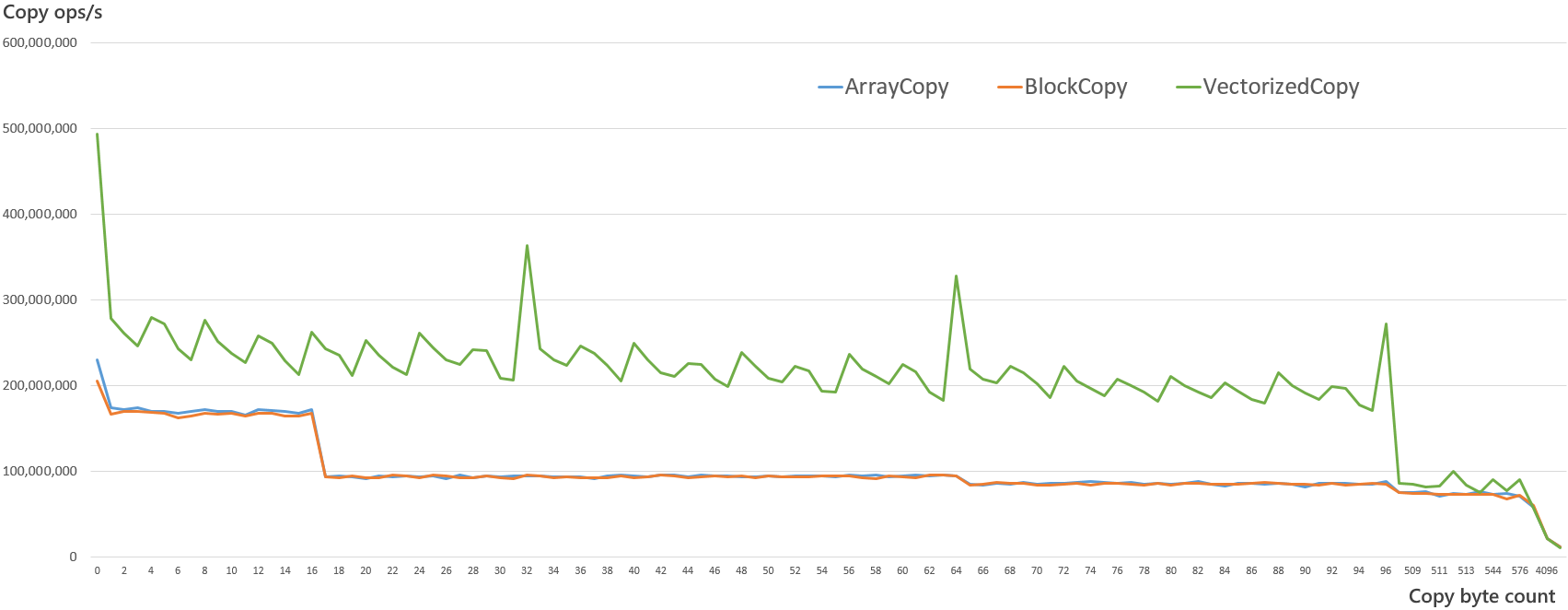
runtime: Array.Copy & Buffer.BlockCopy x2 to x3 slower < 1kB
Array.Copy & Buffer.BlockCopy are up to x3 times slower than what can currently be written using managed C# for byte[] copies < 1024 bytes.
As these are the low level copy apis they should be faster than anything that can be written using managed code.
The IllyriadGames/ByteArrayExtension repository adds a VectorizedCopy extension method for byte[] that demonstrates this speed-up; and I assume potentially more gains could be made at the clr level.
As Buffer.BlockCopy is essentially calling memmove Would this effect other copies e.g. structs passed as parameters; as they are essentially small copy operations?
About this issue
- Original URL
- State: closed
- Created 9 years ago
- Reactions: 9
- Comments: 41 (33 by maintainers)
This issue is getting long and IMO a bit unfocused. Let’s try to sum it up, we’ll see there are actually 2 different related issues.
It’s clear that
Array.Copy& co. are slower than a nativememcpy. How much slower depends on the CLR build. For example, the desktop build does 76 mil 8 byte copies while the official CoreCLR rc1-final does only ~48 mil (lack of PGO I assume). Anyway, VC++2015’smemcpydoes 268 mil copies so it’s 3.5 times faster than the best CLR time. Even at larger sizes the difference is still rather large - 1.7x for 512 byte copies.Now, the CLR may end up using no less than 3 different versions of
memcpydepending on how it is build (VS2013 CRT, VS2015 CRT, OS CRT) and this can complicate measurements a bit. But the outcome is largely the same, the nativememcpyis faster, especially for very small copy sizes. We shouldn’t be distracted by things like “there’s a drop in performance at 16 bytes” because with or without drop the performance is still lower.Issue 1 Where does the difference come from? The CLR uses
memcpyas well (at least in the case of blittable types) but before that there are a lot of checks and the cost of those checks is significant for small copy sizes. SIMD won’t help here but an intrinsic or managed version ofArray.Copymight help because some of those checks could be eliminated. IMO a managed generic version would be best but that too requires some intrinsics, that’s whatIsBlittableis after all.Are there workarounds? Well, if you don’t mind using
unsafethen there’sBuffer.MemoryCopy. But is its performance as good asmemcpy? It turns out that it isn’t and that’s the second issue.Issue 2 Even for size < 16 the performance of
Buffer.MemoryCopyis ~1.2x lower thanmemcpyeven if both use the same technique - a jump table (switch). This may be a JIT issue, in any case this case isn’t related to SIMD.Issue 3 And for size = 512 the performance is also lower, around 1.4x. Here is where SIMD would fit in, should work better than the current
int/longcopy loop.Hmm, looks like I ended up with 3 different issues 😃