orleans: Incorrect silo shutdown behavior
We’re experiencing serious problems with a rolling update after migration to 2.0. Let me explain our architecture: we have a single heterogenous Azure queue processed by multiple workers (Competing Consumers pattern). Each message in this queue may be destined to a differrent actor. The setup is quite similar to how built-in Azure Queue Streaming Provider works. See diagram below.
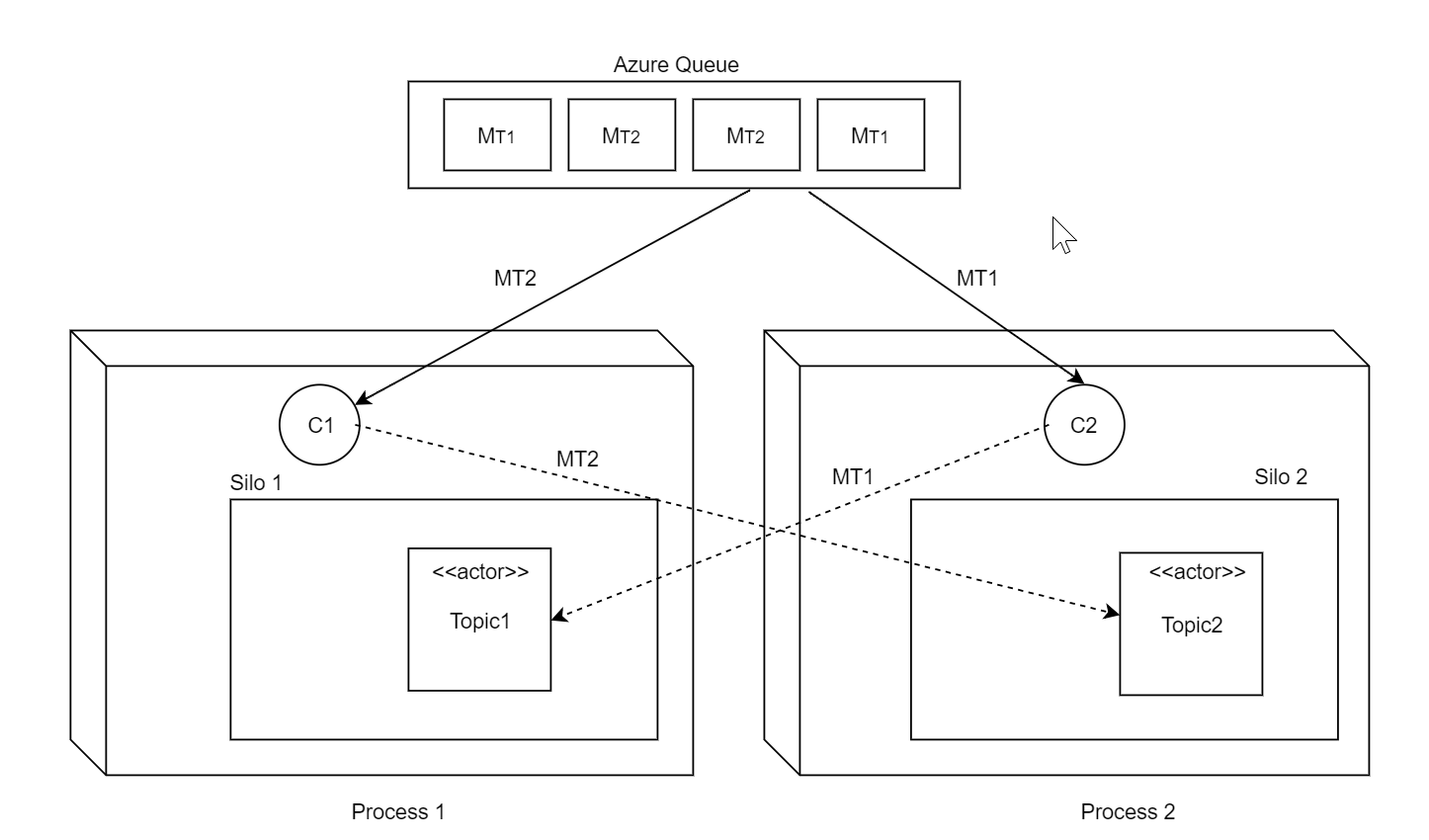
Each node runs pulling agent (queue poller) and the corresponding TPL DataFlow pipeline outside of the silo but within the same process with the silo (ie embedded). It could happen that recipent actor may reside on a different silo and so the client may forward the message to another silo, which is normal of course. Also there number of other actors that may exchange messages across silos, also normal, of course, since that’s the whole point of having Orleans.
The problem arises when we try to shutdown the silo during rolling update. My expectation of Orleans’ silo shutdown behavior when StopAsync() is called:
- Don’t accept any new requests into the silo, neither from clients nor from other silos (basically, close silo gateway)
- Wait until all outstanding requests are completed (or failed or timed out) and return results
- Deactivate all actors
- Done
Instead, what we see from logs is that upon receiving StopAsync() Orleans almost immedietely deactivates all actors and then for 1 minute it bounces requests from other clients/silos by trying to forward them to non-existent activations (and they are not reactivated on the current silo of course since it’s shutting down), and after 1 minute it kills itself after silo stop timeout is expired (which is 1 minute as I can see from the code). During this time it (Orleans.Runtime.Dispatcher) spills tens of thousands of log messages like:
Trying to forward after Non-existent activation, ForwardCount = 0. Message Request S10.31.5.14:100:268955504*cli/586efeb6@0c49119e->S10.31.5.14:100:268955504*grn/2FB327A8/00000000+124531@dd334eba #17019
And
Forwarding failed: tried to forward message Request S10.31.5.14:100:268955504*cli/586efeb6@0c49119e->S10.31.5.14:100:268955504*grn/2FB327A8/00000000+136155@897e8889 #17002[ForwardCount=1]: for 1 times after Non-existent activation to invalid activation. Rejecting now.
And
Intermediate NonExistentActivation for message Request S10.31.5.14:100:268955504*cli/ee2e539e@6615b9ac->S10.31.5.14:100:268955504*grn/2FB327A8/00000000+121772@882812ba #46821: , with Exception Orleans.Runtime.Catalog+NonExistentActivationException: Non-existent activation: [ActivationAddress: S10.31.5.14:100:268955504*grn/2FB327A8/00000000+121772@882812ba, Full GrainId: [GrainId: *grn/2FB327A8/00000000000000000000000000000000060000002fb327a8+121772-0x577BB16A, IdCategory: KeyExtGrain, BaseTypeCode: 800270248 (x2FB327A8), PrimaryKey: 0 (x0), UniformHashCode: 1467724138 (0x577BB16A), KeyExtension: 121772], Full ActivationId: @42851f391a09207a71eff3b7882812ba0000000000000000], grain type: Fun.LegacyTheme.
at Orleans.Runtime.Catalog.GetOrCreateActivation(ActivationAddress address, Boolean newPlacement, String grainType, String genericArguments, Dictionary`2 requestContextData, Task& activatedPromise)
at Orleans.Runtime.Dispatcher.ReceiveMessage(Message message)
This is unacceptable behavior for us, as:
- The whole cluster restart takes more than 10 minutes (more then 2 minutes per node. we have 5 nodes at the moment). Which is super slow.
- Since during this time deactivated actors are not re-activated on other silos, queue messages are timing out and are returned to queue. For 10 minutes chaos which occur during restart messages may breach dequeue count threshold and be moved to quarantine queue. Which is super bad.
- During restart the queue length may grow up to 100x, leading to client visible processing delays and additional stress.
- Our logs cluster (ES) is not made from rubber and on each restart Orleans can easily generate 0.5M log messages. With 10 deployments per day Orleans logs take a considerable amount of space.
The question is what are we doing wrong? No matter what we do we can’t gracefully shutdown the silo. Our shutdown routine:
- Stop all local pulling agents (silo local queue poller).
- Wait\complete\cancel local pipeline
- Stop the silo
- Diconnect local client
It seems that all those steps are useless since requests from other clients\silos are still accepted by the silo after StopAsync is issued. I can’t trace whether those requests were accepted just before StopAsync() but even if they are, Orleans should not deactivate actors until all those requests are completed.
P.S. I didn’t include in this conversation hundreds of thousands of SiloUnavailableException and OrleansMessageRejectionException raised by sibling nodes during each restart - I belive it’s a topic of its own (perhaps retries could be advised as the solution).
About this issue
- Original URL
- State: closed
- Created 6 years ago
- Reactions: 10
- Comments: 24 (18 by maintainers)
Hi guys!
Just want to post an update about our rolling restart epic. We finally solved everything and now have 0 exceptions instead of ~30K per each node during shutdown under high load.
What we did:
StatelessWorkeractors are not directly accessible by the clients (only from proxy grains). This was a huge insight into the shutdown problem and it cut the number of errors per node to ~2K (10x decrease). The issue with stateless workers which are directly accessible by the clients is that Orleans cannot cleanly re-route requests to workers in another silo (I was not able to do it in my custom placement director), since they are addressable only locally. Moreover, Orleans will keep spawning workers during node shutdown. This could be confirmed by checking sources of StatelessWorker placement director here. Personally, I think that SWs is a leaky abstraction something that is against a paradigm of distributed Virtual Actors.SiloUnavailableExcepetion,TimeoutExceptionand some weird Orleans errors, likeObjectDisposedException,ClientGatewayException, etc) are coming from the embedded client, we’ve been running it in the same process as the silo but it was connected via azure clustering and it might connect to the gateway on another silo.SiloUnavailableExceptionorTimeoutException. 0 weird errors coming from Orleans internalsSo I want to say big thanks for everyone for the fantastic work done in 2.1.0. The introduction of silo direct client is a life-saver for embedded scenarios I’ve described in #4757. The fact that it dies automatically with the silo fixes all of the race conditions particular to this use-case. Kudos for all the optimization work done for the scheduler.
P.S. @talarari @andrew-laughlin It didn’t really help so we discarded it. Instead, we figured out the root cause and fixed it by migrating to 2.1.0 and direct silo client.