efcore: IN() list queries are not parameterized, causing increased SQL Server CPU usage
Currently, EF Core is not parameterizing IN(...) queries created from .Contains() (and maybe other cases). This has a very detrimental impact on SQL Server itself because:
- The query hash is different for each distinct set of IDs passed in.
- SQL Server needs to calculate a plan for each of these distinct combinations (CPU hit).
- The query plans created occupy an entry in SQL Server’s plan cache (unless ad-hoc behavior is on), fighting for resources on other plans and cascading CPU issues by re-calculations due to evictions.
Note: when SQL Server has memory pressure, plan cache is the first thing to empty. So this has a profound impact at scale, doubly so when things have gone sideways.
Steps to reproduce
Here’s a reduced down version of the problem:
var ids = Enumerable.Range(1, 1000).ToList();
var throwAwary = context.Users.Where(u => ids.Contains(u.Id)).ToList();
This results in the following:
SELECT [u].[Id], [u].[AcceptRateAccepted], [u].[AcceptRateAsked], [u].[AccountId], [u].[AnswerCount], [u].[BronzeBadges], [u].[CreationDate], [u].[DaysVisitedConsecutive], [u].[DaysVisitedTotal], [u].[DisplayName], [u].[Email], [u].[Flags], [u].[GoldBadges], [u].[HasAboutMeExcerpt], [u].[HasReplies], [u].[IsVeteran], [u].[JobSearchStatus], [u].[LastAccessDate], [u].[LastDailySiteAccessDate], [u].[LastEmailDate], [u].[LastLoginDate], [u].[LastLoginIP], [u].[LastModifiedDate], [u].[Location], [u].[OptInEmail], [u].[PreferencesRaw], [u].[ProfileImageUrl], [u].[QuestionCount], [u].[RealName], [u].[Reputation], [u].[ReputationMonth], [u].[ReputationQuarter], [u].[ReputationSinceLastCheck], [u].[ReputationToday], [u].[ReputationWeek], [u].[ReputationYear], [u].[SignupStarted], [u].[SilverBadges], [u].[TeamId], [u].[TeamName], [u].[TimedPenaltyDate], [u].[Title], [u].[UserTypeId], [u].[WebsiteUrl]
FROM [Users] AS [u]
WHERE [u].[Id] IN (1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181, 182, 183, 184, 185, 186, 187, 188, 189, 190, 191, 192, 193, 194, 195, 196, 197, 198, 199, 200, 201, 202, 203, 204, 205, 206, 207, 208, 209, 210, 211, 212, 213, 214, 215, 216, 217, 218, 219, 220, 221, 222, 223, 224, 225, 226, 227, 228, 229, 230, 231, 232, 233, 234, 235, 236, 237, 238, 239, 240, 241, 242, 243, 244, 245, 246, 247, 248, 249, 250, 251, 252, 253, 254, 255, 256, 257, 258, 259, 260, 261, 262, 263, 264, 265, 266, 267, 268, 269, 270, 271, 272, 273, 274, 275, 276, 277, 278, 279, 280, 281, 282, 283, 284, 285, 286, 287, 288, 289, 290, 291, 292, 293, 294, 295, 296, 297, 298, 299, 300, 301, 302, 303, 304, 305, 306, 307, 308, 309, 310, 311, 312, 313, 314, 315, 316, 317, 318, 319, 320, 321, 322, 323, 324, 325, 326, 327, 328, 329, 330, 331, 332, 333, 334, 335, 336, 337, 338, 339, 340, 341, 342, 343, 344, 345, 346, 347, 348, 349, 350, 351, 352, 353, 354, 355, 356, 357, 358, 359, 360, 361, 362, 363, 364, 365, 366, 367, 368, 369, 370, 371, 372, 373, 374, 375, 376, 377, 378, 379, 380, 381, 382, 383, 384, 385, 386, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 409, 410, 411, 412, 413, 414, 415, 416, 417, 418, 419, 420, 421, 422, 423, 424, 425, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446, 447, 448, 449, 450, 451, 452, 453, 454, 455, 456, 457, 458, 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498, 499, 500, 501, 502, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 518, 519, 520, 521, 522, 523, 524, 525, 526, 527, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539, 540, 541, 542, 543, 544, 545, 546, 547, 548, 549, 550, 551, 552, 553, 554, 555, 556, 557, 558, 559, 560, 561, 562, 563, 564, 565, 566, 567, 568, 569, 570, 571, 572, 573, 574, 575, 576, 577, 578, 579, 580, 581, 582, 583, 584, 585, 586, 587, 588, 589, 590, 591, 592, 593, 594, 595, 596, 597, 598, 599, 600, 601, 602, 603, 604, 605, 606, 607, 608, 609, 610, 611, 612, 613, 614, 615, 616, 617, 618, 619, 620, 621, 622, 623, 624, 625, 626, 627, 628, 629, 630, 631, 632, 633, 634, 635, 636, 637, 638, 639, 640, 641, 642, 643, 644, 645, 646, 647, 648, 649, 650, 651, 652, 653, 654, 655, 656, 657, 658, 659, 660, 661, 662, 663, 664, 665, 666, 667, 668, 669, 670, 671, 672, 673, 674, 675, 676, 677, 678, 679, 680, 681, 682, 683, 684, 685, 686, 687, 688, 689, 690, 691, 692, 693, 694, 695, 696, 697, 698, 699, 700, 701, 702, 703, 704, 705, 706, 707, 708, 709, 710, 711, 712, 713, 714, 715, 716, 717, 718, 719, 720, 721, 722, 723, 724, 725, 726, 727, 728, 729, 730, 731, 732, 733, 734, 735, 736, 737, 738, 739, 740, 741, 742, 743, 744, 745, 746, 747, 748, 749, 750, 751, 752, 753, 754, 755, 756, 757, 758, 759, 760, 761, 762, 763, 764, 765, 766, 767, 768, 769, 770, 771, 772, 773, 774, 775, 776, 777, 778, 779, 780, 781, 782, 783, 784, 785, 786, 787, 788, 789, 790, 791, 792, 793, 794, 795, 796, 797, 798, 799, 800, 801, 802, 803, 804, 805, 806, 807, 808, 809, 810, 811, 812, 813, 814, 815, 816, 817, 818, 819, 820, 821, 822, 823, 824, 825, 826, 827, 828, 829, 830, 831, 832, 833, 834, 835, 836, 837, 838, 839, 840, 841, 842, 843, 844, 845, 846, 847, 848, 849, 850, 851, 852, 853, 854, 855, 856, 857, 858, 859, 860, 861, 862, 863, 864, 865, 866, 867, 868, 869, 870, 871, 872, 873, 874, 875, 876, 877, 878, 879, 880, 881, 882, 883, 884, 885, 886, 887, 888, 889, 890, 891, 892, 893, 894, 895, 896, 897, 898, 899, 900, 901, 902, 903, 904, 905, 906, 907, 908, 909, 910, 911, 912, 913, 914, 915, 916, 917, 918, 919, 920, 921, 922, 923, 924, 925, 926, 927, 928, 929, 930, 931, 932, 933, 934, 935, 936, 937, 938, 939, 940, 941, 942, 943, 944, 945, 946, 947, 948, 949, 950, 951, 952, 953, 954, 955, 956, 957, 958, 959, 960, 961, 962, 963, 964, 965, 966, 967, 968, 969, 970, 971, 972, 973, 974, 975, 976, 977, 978, 979, 980, 981, 982, 983, 984, 985, 986, 987, 988, 989, 990, 991, 992, 993, 994, 995, 996, 997, 998, 999, 1000);
Further technical details
EF Core version: 2.1.4
Database Provider: Microsoft.EntityFrameworkCore.SqlServer
Operating system: Windows 2016/Windows 10
IDE: Visual Studio 2017 15.9
Proposal
EF Core should parameterize here. Instead of IN (1, 2, 3, ...) we should see IN (@__ids1, @__ids2, @__ids3, ...) or similar. This would allow query plan cache to be shared. For example if we ran this 1,000 times to fetch 1,000,000 users in batches, we’d have 1 plan in cache, whereas today we have 1,000 plans. Let’s say a user gets removed (or added!) on page 2 of 1,000…today we’d calculate and cache another 999 plans next run.
To further address the cardinality problem, an approach similar to what Dapper does would be at least a starting point. We generate only lists of certain sizes, let’s just say 5, 10, 50, 100, 500, 1000. Here’s an example with 3 parameters:
SELECT [u].[Id], [u].[AcceptRateAccepted], [u].[AcceptRateAsked], [u].[AccountId], [u].[AnswerCount], [u].[BronzeBadges], [u].[CreationDate], [u].[DaysVisitedConsecutive], [u].[DaysVisitedTotal], [u].[DisplayName], [u].[Email], [u].[Flags], [u].[GoldBadges], [u].[HasAboutMeExcerpt], [u].[HasReplies], [u].[IsVeteran], [u].[JobSearchStatus], [u].[LastAccessDate], [u].[LastDailySiteAccessDate], [u].[LastEmailDate], [u].[LastLoginDate], [u].[LastLoginIP], [u].[LastModifiedDate], [u].[Location], [u].[OptInEmail], [u].[PreferencesRaw], [u].[ProfileImageUrl], [u].[QuestionCount], [u].[RealName], [u].[Reputation], [u].[ReputationMonth], [u].[ReputationQuarter], [u].[ReputationSinceLastCheck], [u].[ReputationToday], [u].[ReputationWeek], [u].[ReputationYear], [u].[SignupStarted], [u].[SilverBadges], [u].[TeamId], [u].[TeamName], [u].[TimedPenaltyDate], [u].[Title], [u].[UserTypeId], [u].[WebsiteUrl]
FROM [Users] AS [u]
WHERE [u].[Id] IN (@ids1, @ids2, @ids3, @ids4, @ids5);
The 5 Ids are so that 1-5 values all use the same plan. Anything < n in length repeats the last value (don’t use null!). In this case let’s say our values are 1, 2, and 3. Our parameterization would be:
@ids1 = 1;@ids2 = 2;@ids3 = 3;@ids4 = 3;@ids5 = 3;
This fetches the users we want, is friendly to the cache, and lessens the amount of generated permutations for all layers.
To put this in perspective, at Stack Overflow scale we’re generating millions of one-time-use plans needlessly in EF Core (the parameterization in Linq2Sql lowered this to only cardinality permutations). We alleviate the cache issue by enabling ad-hoc query mode on our SQL Servers, but that doesn’t lessen the CPU use from all the query hashes involved except in the (very rare) reuse case of the exact same list.
This problem is dangerous because it’s also hard to see. If you’re looking at the plan cache, you’re not going to see it by any sort of impact query analysis. Each query, hash, and plan is different. There’s no sane way to group them. It’s death by a thousand cuts you can’t see. I’m currently finding and killing as many of these in our app as I can, but we should fix this at the source for everyone.
About this issue
- Original URL
- State: closed
- Created 6 years ago
- Reactions: 273
- Comments: 123 (76 by maintainers)
Links to this issue
- Alterações significativas no EF Core 8.0 (EF8) - EF Core | Microsoft Learn
- Changements cassants dans EF Core 8.0 (EF8) – EF Core | Microsoft Learn
- Breaking changes in EF Core 8.0 (EF8) - EF Core | Microsoft Learn
- EF Core 8.0(EF8)의 호환성이 손상되는 변경 - EF Core | Microsoft Learn
- EF Core: Breaking Changes in EF Core 8.0 (EF8) | Microsoft Learn
- EF Core 8.0 的重大變更 (EF8) - EF Core | Microsoft Learn
- EF Core 8.0 (EF8) 中的中断性变更 - EF Core | Microsoft Learn
- Критические изменения в EF Core 8.0 (EF8) — EF Core | Microsoft Learn
- Cambios importantes en EF Core 8.0 (EF8): EF Core | Microsoft Learn
- EF Core 8.0'da (EF8) hataya neden olan değişiklikler - EF Core | Microsoft Learn
- Memutus perubahan dalam EF Core 8.0 (EF8) - EF Core | Microsoft Learn
- Zmiany powodujące niezgodność w programie EF Core 8.0 (EF8) — EF Core | Microsoft Learn
- Modifiche di rilievo in EF Core 8.0 (EF8) - EF Core | Microsoft Learn
- EF Core 8.0 (EF8) での破壊的変更 - EF Core | Microsoft Learn
- Zásadní změny v EF Core 8.0 (EF8) – EF Core | Microsoft Learn
Commits related to this issue
- Support primitive collections Closes #29427 Closes #30426 Closes #13617 — committed to roji/efcore by roji a year ago
- Support primitive collections Closes #29427 Closes #30426 Closes #13617 — committed to roji/efcore by roji a year ago
- Support primitive collections Closes #29427 Closes #30426 Closes #13617 — committed to roji/efcore by roji a year ago
- Support primitive collections Closes #29427 Closes #30426 Closes #13617 — committed to roji/efcore by roji a year ago
- Support primitive collections Closes #29427 Closes #30426 Closes #13617 — committed to roji/efcore by roji a year ago
- Support primitive collections Closes #29427 Closes #30426 Closes #13617 — committed to roji/efcore by roji a year ago
- Support primitive collections Closes #29427 Closes #30426 Closes #13617 — committed to roji/efcore by roji a year ago
- Support primitive collections Closes #29427 Closes #30426 Closes #13617 — committed to roji/efcore by roji a year ago
- Support primitive collections Closes #29427 Closes #30426 Closes #13617 — committed to roji/efcore by roji a year ago
- Support primitive collections Closes #29427 Closes #30426 Closes #13617 — committed to roji/efcore by roji a year ago
- Support primitive collections Closes #29427 Closes #30426 Closes #13617 — committed to roji/efcore by roji a year ago
- Support primitive collections Closes #29427 Closes #30426 Closes #13617 — committed to roji/efcore by roji a year ago
- Support primitive collections Closes #29427 Closes #30426 Closes #13617 — committed to roji/efcore by roji a year ago
- Support primitive collections Closes #29427 Closes #30426 Closes #13617 — committed to roji/efcore by roji a year ago
- Support primitive collections Closes #29427 Closes #30426 Closes #13617 — committed to roji/efcore by roji a year ago
- Support primitive collections Closes #29427 Closes #30426 Closes #13617 — committed to roji/efcore by roji a year ago
- Support primitive collections Closes #29427 Closes #30426 Closes #13617 — committed to roji/efcore by roji a year ago
- Support primitive collections Closes #29427 Closes #30426 Closes #13617 — committed to roji/efcore by roji a year ago
- Support primitive collections Closes #29427 Closes #30426 Closes #13617 — committed to roji/efcore by roji a year ago
- Support primitive collections Closes #29427 Closes #30426 Closes #13617 — committed to roji/efcore by roji a year ago
Everyone,
We spent some time investigating this; below is a write-up of the current situation, the possible ways forward and some first conclusions. The tl;dr is that we think it makes sense to implement an OPENJSON-based approach, where the (array parameter (e.g. int[]) is transmitted as a JSON string parameter (`[1,2,3]') and unpacked to a pseudo-table, which we can then be used in the SQL query as usual. As many people have shown an interest here, it would be good to receive feedback on the below!
The problem
It’s very common to filter rows based on an array of (primitive) values that exists on the client. In an EF LINQ query, this looks like the following:
This conceptually translates to a SQL IN expression. However, since array parameters aren’t supported by most databases, EF unpacks the array into the SQL, currently inserting its values as constants:
This technique unfortunately means that different array values cause different SQL to get generated. This can cause severe performance problems, since it pollutes database query plans, causing re-planning for each execution and evicts plans for other queries. Less importantly, EF cannot (currently) cache the SQL, as it depends on parameter values; this means some query processing must occur for each execution.
In the benchmark below, this technique is called
In_with_constants.IN expression with parameters
To improve this, we could simply embed the array values as parameters instead of constants:
For all arrays of identical lengths (3 in our case), this produces the same SQL and is therefore optimal. However, varying array lengths still cause differing SQLs, triggering the performance issues. Also, EF still cannot cache the SQL.
In the benchmark below, this technique is called
In_with_padded_parameterswith PaddingCount = 0.Padding
A common way to alleviate the differing length problem is to “pad” the IN expression with extra “useless” parameters, up to an arbitrary boundary. For example, the following pads our 3-value array to 5 values:
Array lengths of 5 and below therefore use the same SQL, at the cost of sending duplicated data to the server. The bigger the padding boundary, the less different SQLs are produced for different array lengths, but the more padding parameters are added on the average, increasing query overhead.
This padding technique has a long history and can be used with various ORMs (nHibernate, jooq, Dapper), though it sometimes requires an opt-in.
In the benchmark below, this technique is called
In_with_padded_parameterswith PaddingCount > 0.Sending the values as an array
Rather than expanding an array parameter out to individual values in a SQL IN expression (whether as constants or as parameters), ideally we’d be able to just send the array parameter directly. Doing this directly usually isn’t supported, since databases don’t typically support array types in any way. The two exceptions to this are:
WHERE x = ANY (@arrayParam), where@arrayParamis a simply .NET array. This yields optimal performance with optimal simplicity.CREATE TYPE), making it generally unsuitable for EF, and does not perform well (see Temporary_table_with_inner_join in the benchmark below).However, all modern databases support parsing a JSON string representing an array and evaluating it as a relational resultset (e.g. pseudo-table); this allows us to send a simple string parameter containing e.g.
[10,20,30], and use a table-valued SQL function to extract the values out as a table with 3 rows containing those values. Once that’s done, regular SQL can be used to implements the Contains logic. The following uses an inner join to filter out only customers with IDs matching the incoming JSON array (this technique is Array_param_with_inner_join in the benchmarks):A subquery-based approach was also benchmarked (Array_param_with_exists_subquery):
This technique has the following advantages compared to the expansion-based techniques discussed above:
Links to the JSON-unpacking functions in the different databases:
OPENJSON. This function is only available with compatibility level 130 or higher (Azure SQL Database and SQL Server 2016 and later; the previous version - SQL Server 2014 goes out of support in 2024). An alternativeOPENXMLalso exists with better compatibility, but performs significantly worse.json_each.json_table.JSON_TABLE.Benchmark
Benchmark results
Benchmark sources
Observations:
Detailed benchmarking of IN with parameterized vs. OPENJSON
The following benchmark show IN with parameters vs. OPENJSON with JOIN. No parameter padding is done for IN, so this optimistically assumes value counts are always at the padding boundaries. This means that results below show IN as better than it actually is, since in the real world padding will occur. In addition, this doesn’t take into account EF SQL caching, which is possible with OPENJSON but not possible with IN; this again means IN looks better than it really is.
Summary
I wrote an extension to EF6 to handle this exact problem for our product and apparently it is extremely similar to what Nick is proposing above. By replacing this where clause:
.Where(entity => myEnumerable.Contains(entity.prop))with this extension method:.BatchedWhereKeyInValues(entity => entity.prop, myEnumerables, batchSize: 100), my solution will break the list of values into batches, and then produce a properly parameterized query that generates the desired SQL.For example, this expression:
query.BatchedWhereKeyInValues(q => q.Id, values: {1,2,5,7,8,9}, batchSize: 3)would effectively become the following two queryables, where the numbers are supplied as variables that allow EF to parameterize the query rather than embed them as constants:
query.Where(q => q.Id == 1 || q.Id == 2 || q.Id == 5)query.Where(q => q.Id == 7 || q.Id == 8 || q.Id == 9)EF then converts those LINQ expressions into this SQL expression:
WHERE Id IN (@p__linq__0, @p__linq__1, @p__linq__2)Check out the source here: https://gist.github.com/kroymann/e57b3b4f30e6056a3465dbf118e5f13d
Here’s an alternative solution I discovered thanks to a semi-related SO post by @davidbaxterbrowne:
It’s specific to SQL Server 2017+ (or Azure SQL Server), and in my testing with a list of 50,000 IDs against a remote Azure SQL database it was 5x faster than a standard batching solution (dividing into lists of 1,000 IDs).
@kroymann Works like a charm! Big Thanks!
Usage:
@yv989c great to hear! In my benchmark above, XML performed worse than than the current EF technique (expansion to constants), but I may have not optimized that technique as much as I should have. In any case, I think that at the point where we are, simply supporting JSON and allowing an opt-out back to the current technique for old SQL Server versions is good enough.
I’m currently actively working on this, as part of a much larger change that should allow fully queryable parameters, constants and even columns across different providers. Stay tuned.
I have updated one of @divega 's proposals above for 3.1: https://erikej.github.io/efcore/sqlserver/2020/03/30/ef-core-cache-pollution.html
It is good to see that “advanced” solutions have been proposed here. Is it feasible to create a rather simple but quick fix first? Simply making the list a bunch of parameters (e.g.
@p0, @p1, ...) would be much better than the literals. That way there’s one plan for each list count in contrast to one plan for each set of constants.Also such queries don’t aggregate well in logging systems like Application Insights, cause every query has unique sql.
@mrlife unfortunately not - this is quite a non-trivial optimization, and we’re now in a feature freeze, stabilizing the release. I’m very hopeful we’ll be able to tackle this for 7.0.
Been investigating solutions in the meantime and found that the
string_splitfunction idea from above can be separated out into its own queryable for flexible reuse. For example…Add keyless entity to your model:
Some methods like this on your context:
You could do something like this:
Which produces SQL:
@snappyfoo we’re still working out the mechanics in our planning process and the Github project board. The important thing is that this issue has the consider-for-next-release label, which means it’s definitely on the table for 6.0.
I just wanted to share here some lexperiments I did some time ago with different alternative approaches to Enumerable.Contains using existing EF Core APIs:
https://github.com/divega/ContainsOptimization/
The goal was both to find possible workarounds, and to explore how we could deal with Contains in the future.
I timed the initial construction and first execution of the query with different approaches. This isn’t a representative benchmark because there is no data and it doesn’t measure the impact of caching, but I think it is still interesting to see the perf sensitivity to the number of parameters.
The code tests 4 approaches:
Standard Contains
This is included as a baseline and is what happens today when you call Contains with a list: the elements of the list get in-lined as constants in the SQL as literals and the SQL cannot be reused.
Parameter rewrite
This approaches tries to rewrite the expression to mimic what the compiler would produce for a query like this:
It also “bucketizes” the list, meaning that it only produces lists of specific lengths (powers of 2), repeating the last element as necessary, with the goal of favoring caching.
This approach only works within the limits of 2100 parameters in SQL Server, and sp_executesql takes a couple of parameters, so the size of the last possible bucket is 2098.
Overall this seems to be the most expensive approach using EF Core, at least on initial creation and execution.
Split function
This approach was mentioned by @NickCraver and @mgravell as something that Dapper can leverage. I implemented it using FromSql. It is interesting because it leads to just one (potentially very long) string parameter and it seems to perform very well (at least in the first query), but the STRING_SPLIT function is only available in SQL Server since version 2016.
Table-valued parameter
For this I took advantage of the ability to create table-valued parameters that contain an
IEnumerable<DbDataRecord>(I used a list rather than a streaming IEnumerable, but not sure that matters in this case) and pass them as a DbParameter in FromSql. I also added a hack to define the table type for the parameter if it isn’t defined. Overall this seems to be the second most lightweight approach after the split function.@yv989c @pfritschi I’ve done some work in the recent days to improve the SQL quality around this, specifically #30976 which switches to using IN instead of EXISTS where possible, and #30983 which switches to OPENJSON with WITH where ordering preservation isn’t required (e.g. with IN/EXISTS). All this work should hopefully make it into preview6, and should make the EF-generated SQL as optimal as possible.
#30984 tracks synthesizing an ordering value for parameter collections where ordering is needed; I don’t intend to work on this at the moment.
Hey @roji , maybe I can further elaborate on the issues described by @m-gasser:
If you use
OPENJSONwithout the data type definition for the values, SQL Server will throw the WarningType conversation in expression (CONVERT_IMPLICIT(int,OPENJSON_DEFAULT.[value],0)) may affect "CardinalityEstimate" in query plan choice.As the warning explains, having an incorrect cardinality estimation can lead to inefficient query plans, because this estimation is a key factor in determining which join and index operations are used. You will notice this issue if you work with bigger data sets or have many joins in your query.However, if you define the data type of your JSON values with
WITH (...), SQL Server is able to estimate the cardinality correctly and you will get a more stable query execution plan.When your JSON values are strings and you want to provide the data type (eg.
OPENJSON(@display_names) WITH([value] VARCHAR(100) '$') AS [n] WHERE [n].[value] = [u].[DisplayName], you have to make sure, that the length of VARCHAR (in this example 100) is consistent for the same query. You should use the target column definition if possible, or if you cannot use the column definition you should try to use gradations.In the picture above I have executed the same queries with different parameters, one time with a consistent VARCHAR length and one time dynamically calculated depended on the longest string in the parameter. As you can see, if you have a different VARCHAR lengths, SQL Server will think that it is a different query and generate a new query plan. This causes a lot of overhead for each execution and also prevents SQL Server form using the Query Store and Plan Cache efficiently.
After further tests I also noticed that (as mentioned by @m-gasser), you get different query execution plans, if the json string is defined with different lengths. So
EXEC sp_executesql '...', N'@json_string VARCHAR(4000)', @json_string='["a","b","c"]'will generate a different query plan thenEXEC sp_executesql '...', N'@json_string VARCHAR(2000)', @json_string='["a","b","c"]', even if the query and data type definitions are exactly the same.NOTE: See additional benchmarking below with SqlClient EnableOptimizedParameterBinding
Did a quick perf investigation of parameterized vs. non-parameterized
WHERE x IN (...)with lots of values.Key notes and takeaways:
To summarize, I hope we can end up with a solution that doesn’t use the SQL IN construct at all, thereby avoiding all of this (see the INNER JOIN-based solutions above).
Results as a text-only table
Benchmark code
Hey @roji, I have fixed this in the latest release of QueryableValues. It now provides ordering guarantees, among other fixes and enhancements. Besides higher memory allocations, the performance cost resulting from the bigger payload and additional complexity was minimal.
I ran a slim version of my
Containsbenchmarks using the latest version of QueryableValues withMicrosoft.EntityFrameworkCore.SqlServerversion7.0.5and8.0.0-preview.4.23259.3. Unfortunately, the preview version performed significantly worse on types other thanInt32. However, it does fix the query plan cache pollution issue.Here are the BenchmarkDotNet results:
Server instance specs
Benchmarks
Using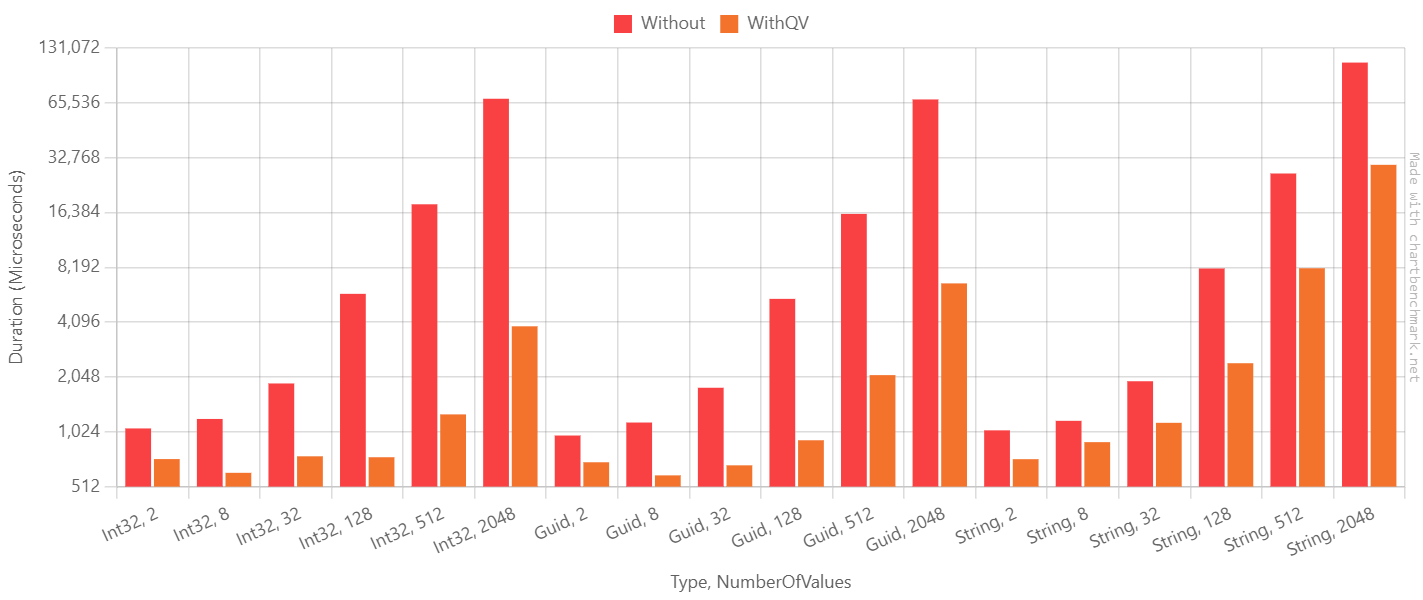 Open Interactive Chart
Open Interactive Chart
Microsoft.EntityFrameworkCore.SqlServerv7.0.5Using Open Interactive Chart
Open Interactive Chart
Microsoft.EntityFrameworkCore.SqlServerv8.0.0-preview.4.23259.3In our company we currently us a custom SqlServerQuerySqlGenerator to generate WHERE conditions in the form
Foo IN(SELECT Value FROM OPENJSON(@jsonstr) WITH (Value CHAR(14)). Our initial implementation did not have the WITH clause and we had issues in production this way. So at least for us, it will not be good enough without the WITH clause, we tried. I hope this anecdotal evidence is good enough for you to implement this.We also size the json parameter to VARCHAR(100), VARCHAR(4000) or VARCHAR(max), depending on how many parameters are provided. I can not remember the details but I guess this allows SQL Server to keep different query plans optimized for varying number of parameters.
Hello everyone! This is my take on providing a solution to this problem. It’s now even more flexible by allowing you to compose a complex type.
I just added some benchmarks showing great results.
Please give it a try. I’m looking forward to your feedback.
Links:
I’d like to contribute some insights that might be related to the issue @michaelmesser is discussing, as I encountered a similar problem while implementing
OPENJSONin QueryableValues.During performance tests, I discovered that the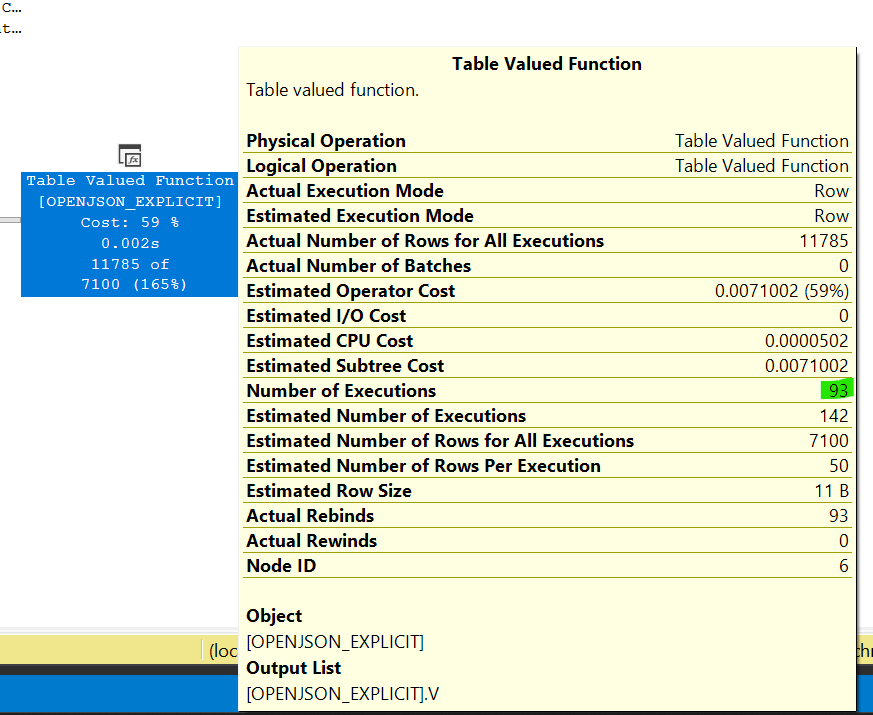
XMLapproach outperformedOPENJSONsignificantly when handling a large number of elements. The issue became apparent when I composed the output from theOPENJSONfunction against a physical table. The larger the physical table, the worseOPENJSONperformed. A closer examination of the execution plan revealed that the query engine was reevaluating/parsing –my best interpretation– the JSON data provided toOPENJSONfor each row –kinda– in the physical table. The following image showcases the metrics from my reproduction of the issue:Per the execution plan,
OPENJSONwas being executed multiple times, despite its input being constant. If this is true, then CPU cycles were being wasted.After extensive experimentation and trying various complex approaches, I managed to persuade the query engine to execute the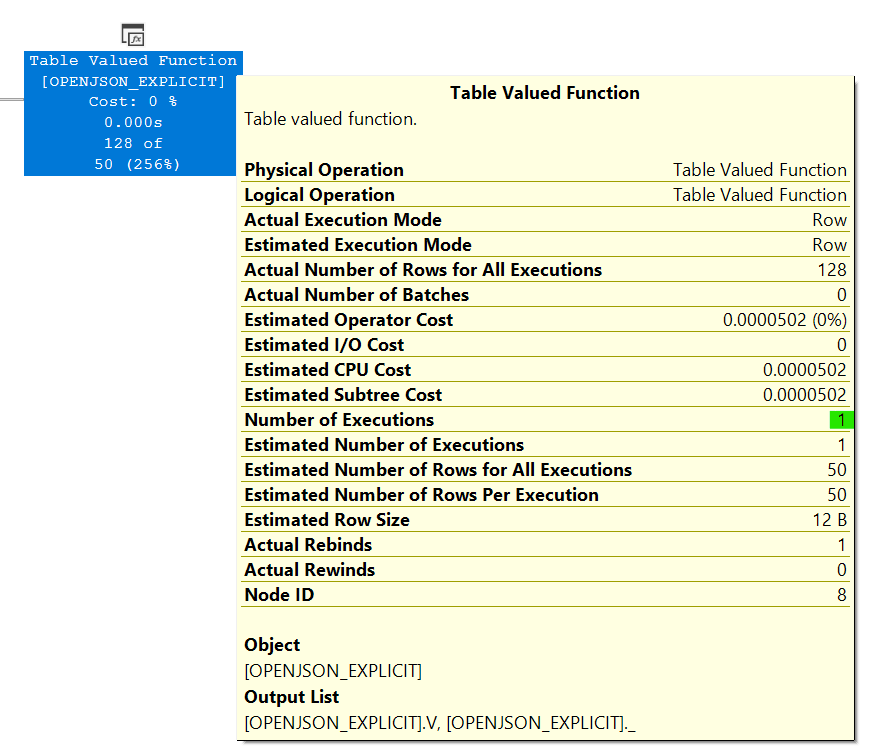
OPENJSONfunction only once. The outcome can be seen in the following image:After this tweak,
OPENJSONsurpassed the performance of all other methods. This improvement was achieved by projecting a dummy column and subsequently sorting theOPENJSONoutput by it.This was my experience when testing with the following SQL Server instance specs:
I hope this information proves helpful.
Up to 1 GB ???
@StefanOverHaevgRZ we’ll try to put this in for preview4, but there’s a chance that might not happen and it’ll only be in preview5.
And yes - the new solution utilizes JSON, so the number of values in the array is no longer important.
FWIW the other candidate (parameterized IN) is also available across all DBs.
That’s #30426, which I mentioned in the summary; and yes, the OPENJSON approach wouldn’t be limited only to Contains. However, at this point it’s unlikely we’ll focus on collection parameters which aren’t over simple primitive types (e.g. composite keys which involve tuples), since that will probably introduce some significant additional complexity. I’ll definitely keep it in mind during implementation, but as @ErikEJ wrote, it’s important to focus on this very specific issue (the 2nd most highly voted in this repo) and not let scope creep compromise it.
A DbOptions setting. We’ll mostly likely default to using OPENJSON by default, and you’d have a context option to request compatibility with older versions (minor breaking breaking change for people using older databases). I think we’ve already had other cases where this was needed, so I think it makes sense.
Thanks, edited the text.
IIRC SQL Server TVPs require an explicit head-of-time CREATE TYPE, so probably not appropriate for this kind of thing. But JSON is probably a possibility (via OPENJSON).
https://gist.github.com/ErikEJ/6ab62e8b9c226ecacf02a5e5713ff7bd
This one, with great comments and suggestions @mrlife
Interesting discussion.
It would be interesting to see benchmark results with the upcoming JSON native type which “will allow you to store JSON documents in a native binary format that is optimized for storage and query performance”. It’s probably more relevant for column data type, but one can also declare JSON parameters/variables.
Although I’m not sure if it’s possible to use this type via c# code.
@canadar only in EF Core 8 - this is quite a serious change/feature, we don’t backport this kind of thing to patch releases (see our planning/release docs).
@yv989c apologies for the long delay, I was travelling.
Oh absolutely - and all your comments/feedback here is greatly appreciated; you’ve certainly gone deeper here than I have.
That’s definitely true and I also would prefer to use OPENJSON with WITH rather than apply casting in the projection, if only for SQL cleanliness. Note that if there’s evidence of an actual performance difference between the two variants, there’s the option of emitting OPENJSON with WITH when ordering is irrelevant (e.g. for Contains), but without it where ordering needs to be preserved. But since this can add some complexity, I’d rather have some proof that it’s worth it first… Any help you can provide on this would be greatly appreciated - otherwise I can do some investigating too.
@michaelmesser thanks for your repro - I can see the (quite strange) phenomenon occuring. I’ll investigate this internally and post back here on the results.
@yv989c yeah, the OPENJSON form with WITH unfortunately doesn’t provide the array index to order by. Note that Azure Synapse does provide an array identity function (docs), but this unfortunately isn’t yet supported elsewhere. I’ve received confirmation that one should not rely on the order of rows being the same as the input array - an ORDER BY is necessary in order to guarantee that; as a result I’ve implemented this without the WITH clause, and added casting on the projected column instead.
I attached SQL to reproduce
OPENJSONwithWithUnorderedPrefetchand withoutWithUnorderedPrefetch. RunTestCreate.sql,TestInsert.sql, and thenTestQuery.sql. While the difference in this example is hundreds of milliseconds, the performance difference with the real data is many seconds.Test.zip
I tried to use
OPENJSONandSTRING_SPLITto work around this issue. With all the relevant pages in memory everything works as expected. However, when pages have to be read from disk the performance is very slow.OPENJSONandSTRING_SPLIThave low estimates. This leads to theINNER LOOP JOINnot havingWithUnorderedPrefetchenabled. Without prefetching, the query has physical reads instead of read-ahead reads. Tricking the cardinality estimator into giving a higher estimate fixes the issue, but results in less readable code. How will EF Core’s solution handle this case?Oh I see…
I’m not sure to what extent we need to actually look at the SQL Server compatibility level in those cases… The thing with this issue is that there’s a fallback: in modern SQL Server we use JSON, otherwise we fall back to IN+constants (since Contains must work, we can’t have it broken on old versions).
With STRING_AGG and CONCAT_WS there’s no “bad” translation to fall back to if they’re not supported, AFAIK. So a compatibility check would at most allow us to provide the user with a more informative “you need to upgrade” error, rather than a cryptic SQL Server “syntax error”.
In any case, CONCAT_WS is tracked by #28899, I already have an old PR #28900 which I’ll need to finish at some point. STRING_AGG is already in - we can indeed add a check to throw an informative message there (though that seems somewhat low-value).
@Meligy we’re definitely aware of that approach - see the very first post above.
I’ve been doing some research on this question and will soon post a plan of action here.
@ErikEJ true - ideally we’d have raw, ADO.NET benchmarks that show bare database performance; but they do provide an indication. We’ll like do some such benchmarking when this is actually implemented for EF.
Thanks!
@danielgreen I’m glad you’re curious. You can find those details here. 🙂
@danielgreen looks like it is passing a xml string, not a tvp
@danielgreen You can find that precise example here.
I’d like to be able to run an adhoc query passing in an array of ints, the way you can pass a table valued parameter to a stored proc. Does the QueryableValues extension enable that?
Indeed!
Sure… Though we’d probably want to avoid anything that involves embedding a (constant) query hint or similar in the SQL, as that would bring us back to the original problem (SQL which depends on the collection size).
Thanks @ErikEJ for the link! Yeah, ideally JSON would perform at least nearly as well, allowing us to just always use that and not worry about delimiters.
@stevendarby Looks like @aaronbertrand did quite a lot of testing in this area already, as always “it depends” but json is not all bad: https://sqlperformance.com/2016/04/sql-server-2016/string-split-follow-up-2
@roji I said as much in my posts so don’t think I’ve oversold it as an option for some to explore- definitely some work to do for the general case 😃
@stevendarby it’s an interesting direction, but at least in the general case there are also varying number of values in the IN clause, so it’s limited in any case. That’s why an INNER JOIN-based solution could be a better way forward here.
@cjstevenson - The value you provided as example does not cause any SQL injection. EF Core escapes quotes properly in the SQL. Generated SQL for example
This is not a security issue. This issue has nothing to do with values and SQL injection, please file a new issue with repro steps if you are seeing a bug. Please refer to security policy if you are submitting a report for security issue.
Might be interesting for others, here’s how we solved the problem by using
LINQKit.Core:This will generate a parameterized query that looks like this:
Related issue: https://github.com/aspnet/EntityFrameworkCore/issues/12777