postgres-operator: postgres-exporter - pgBackRest query fails in untrusted TLS environment
Describe the bug
I have a postgres cluster is working on Azure with metrics enabled. Everything worked fine except for postgres-exporter, it only worked on replicas deployment
To Reproduce Steps to reproduce the behavior:
- My own cluster is deployed with this command(be noticed that all requirements are prepared already: s3, tls, prometheus,…):
pgo create cluster infra \
--pgbouncer \
--service-type=LoadBalancer \
--server-ca-secret=postgresql-ca \
--server-tls-secret=infra-tls-keypair \
--pgbouncer-tls-secret=infra-tls-keypair \
--replication-tls-secret=infra-rep-tls-keypair \
--pgbouncer-replicas=2 \
--replica-count=1 \
--pvc-size=10Gi \
--pgbackrest-storage-type=s3 \
--pgbackrest-s3-bucket=<S3-BUCKET> \
--pgbackrest-s3-endpoint=<S3-ENDPOINT> \
--pgbackrest-s3-key=<S3-REGION> \
--pgbackrest-s3-key-secret=<S3-PROJECT> \
--pgbackrest-s3-region=eu-cenral-1 \
--pgbackrest-s3-uri-style=path \
--pgbackrest-s3-verify-tls=false \
--metrics
- I haved added 2 service monitors from my prometheus operator, they are:
leader-postgres-exporter:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
annotations:
meta.helm.sh/release-name: prometheus
meta.helm.sh/release-namespace: cicd
labels:
app: prometheus-operator-prometheus
app.kubernetes.io/managed-by: Helm
chart: prometheus-operator-8.13.8
heritage: Helm
pg-cluster-role: master
release: prometheus
name: psql-infra-master
namespace: cicd
spec:
endpoints:
- port: postgres-exporter
jobLabel: psql-infra-master
namespaceSelector:
matchNames:
- pgo
selector:
matchLabels:
name: infra
pg-cluster: infra
replica-postgres-exporter:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
annotations:
meta.helm.sh/release-name: prometheus
meta.helm.sh/release-namespace: cicd
labels:
app: prometheus-operator-prometheus
app.kubernetes.io/managed-by: Helm
chart: prometheus-operator-8.13.8
heritage: Helm
pg-cluster-role: replica
release: prometheus
name: psql-infra-replica
namespace: cicd
spec:
endpoints:
- port: postgres-exporter
jobLabel: psql-infra-replica
namespaceSelector:
matchNames:
- pgo
selector:
matchLabels:
name: infra-replica
pg-cluster: infra
- From my prometheus, I see leader-postgres-exporter is always unaccessible. Even if I switched role between them, it is always unaccessible.
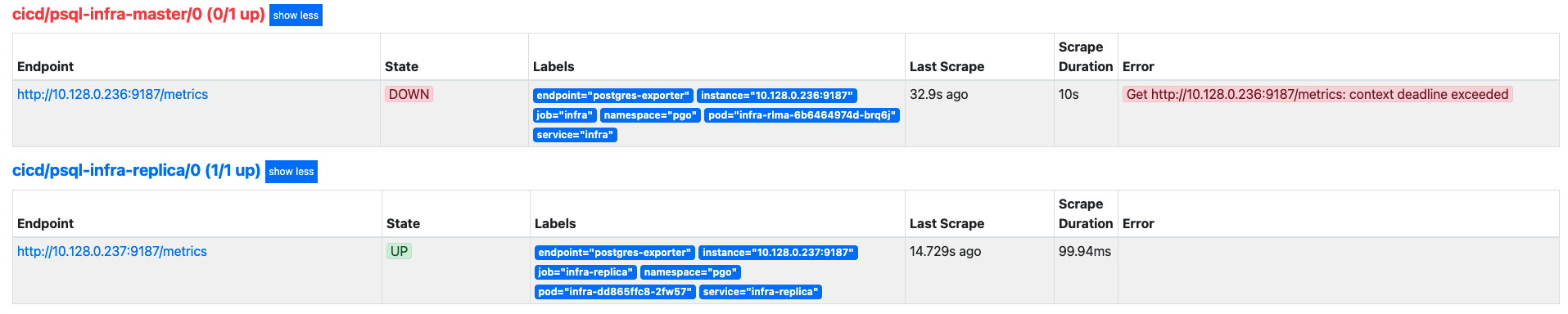
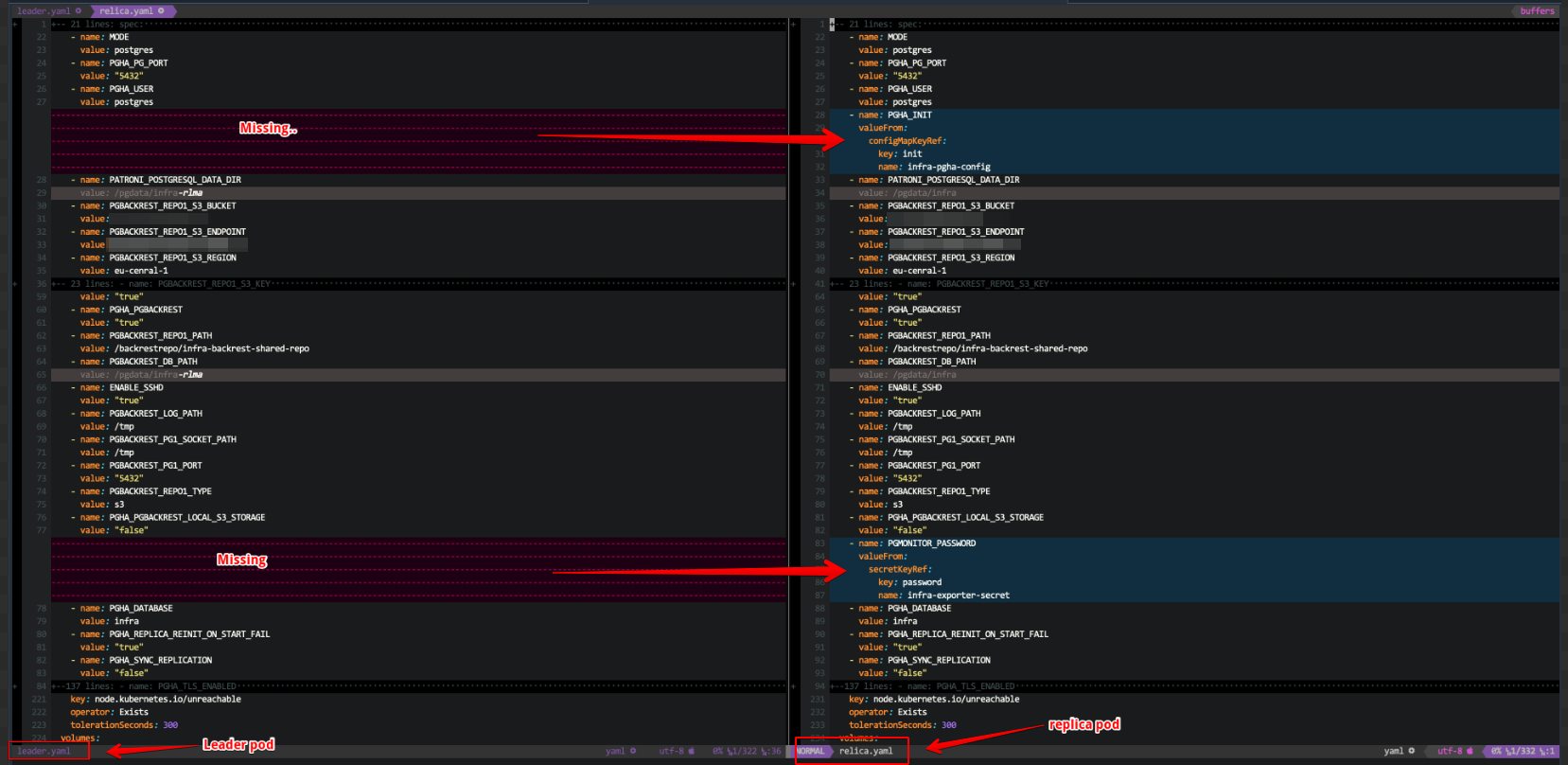
- Finally I looked at how differences between theirs k8s manifests. I see
databasesidecar from leader pod missed these configurations,exporterpods are same:
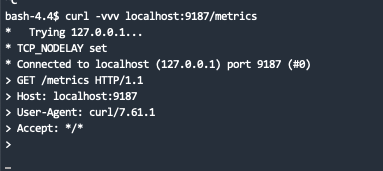
I have also tried to run curl inside leader exporter pod, and the result is failed:
Expected behavior I am not sure it’s feature or bug, I just want to have 2 dedicated metrics for both of them.
Screenshots (Included already)
Please tell us about your environment:
- Operating System: Linux
- Where is this running ( Local, Cloud Provider): Azure
- Storage being used (NFS, Hostpath, Gluster, etc): Azure persistent volumes
- Container Image Tag: registry.developers.crunchydata.com/crunchydata/crunchy-postgres-exporter:centos8-4.6.0
- PostgreSQL Version: registry.developers.crunchydata.com/crunchydata/crunchy-postgres-ha:centos8-13.1-4.6.0
- Platform (Docker, Kubernetes, OpenShift): Kubernetes
- Platform Version: 1.17
Additional context Add any other context about the problem here.
About this issue
- Original URL
- State: closed
- Created 3 years ago
- Comments: 20 (9 by maintainers)
Commits related to this issue
- Honor no TLS verify setting for pgBackRest info scrape For users who are using a self-signed or an untrusted S3-compatible storage system, it may be necessary to enforce no TLS verification. However,... — committed to jkatz/crunchy-containers by deleted user 3 years ago
- Honor no TLS verify setting for pgBackRest info scrape For users who are using a self-signed or an untrusted S3-compatible storage system, it may be necessary to enforce no TLS verification. However,... — committed to CrunchyData/crunchy-containers by deleted user 3 years ago
- Honor no TLS verify setting for pgBackRest info scrape For users who are using a self-signed or an untrusted S3-compatible storage system, it may be necessary to enforce no TLS verification. However,... — committed to CrunchyData/crunchy-containers by deleted user 3 years ago
- Honor no TLS verify setting for pgBackRest info scrape For users who are using a self-signed or an untrusted S3-compatible storage system, it may be necessary to enforce no TLS verification. However,... — committed to CrunchyData/crunchy-containers by deleted user 3 years ago
Primary
Replica