concourse: Workers stall due to dropped connection, client doesn't recover, web node leaks goroutines
Bug Report
In our large-scale algorithm test environment, workers gradually stalled over the course of 2 days:
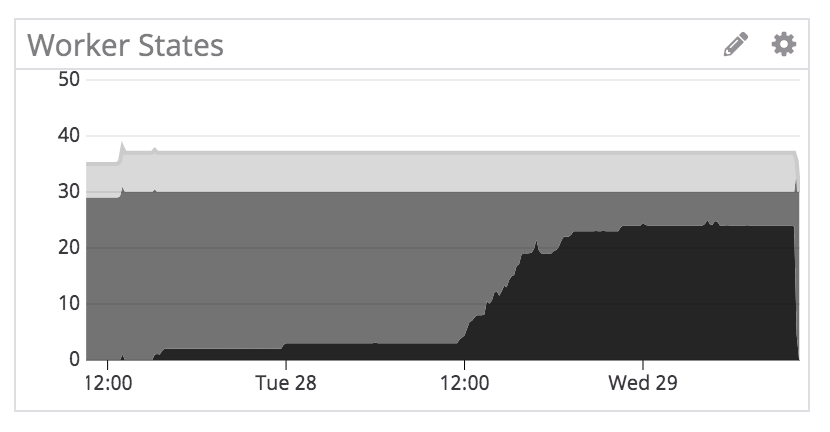
In investigating one of the workers, the machine seemed fine, but its logs showed that it simply stopped heartbeating. It must have been stuck somewhere.
lsof -p <worker pid> revealed that there wasn’t even an active connection to the TSA anymore (port 222).
Through this time, web node memory usage and goroutines crept up:
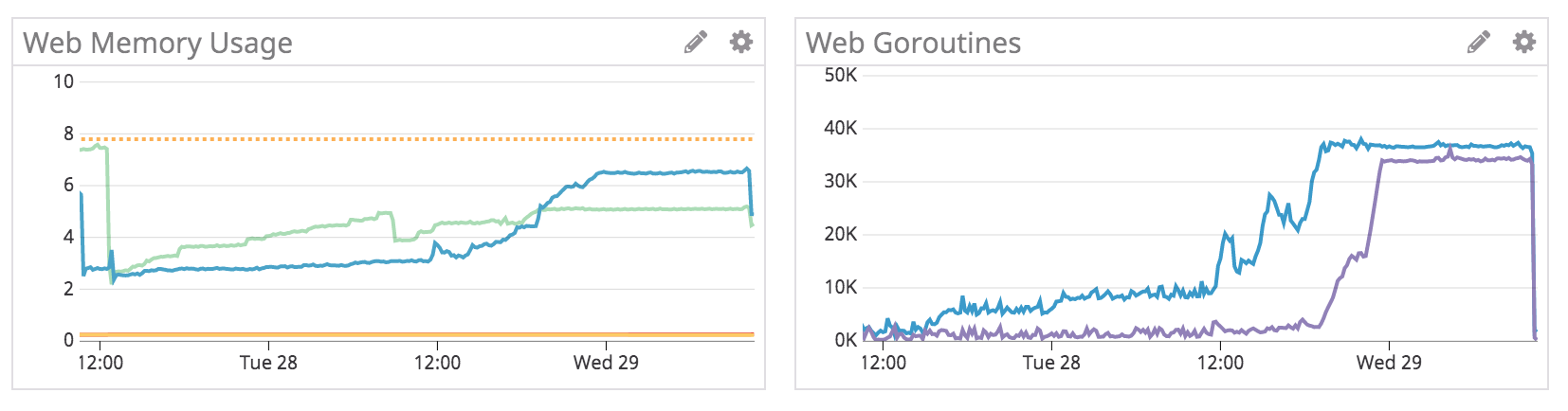
Upon restarting all of the workers (i.e. bosh restart worker), the web goroutines dropped dramatically, and the memory usage slightly recovered (note: these graphs are over the past hour):
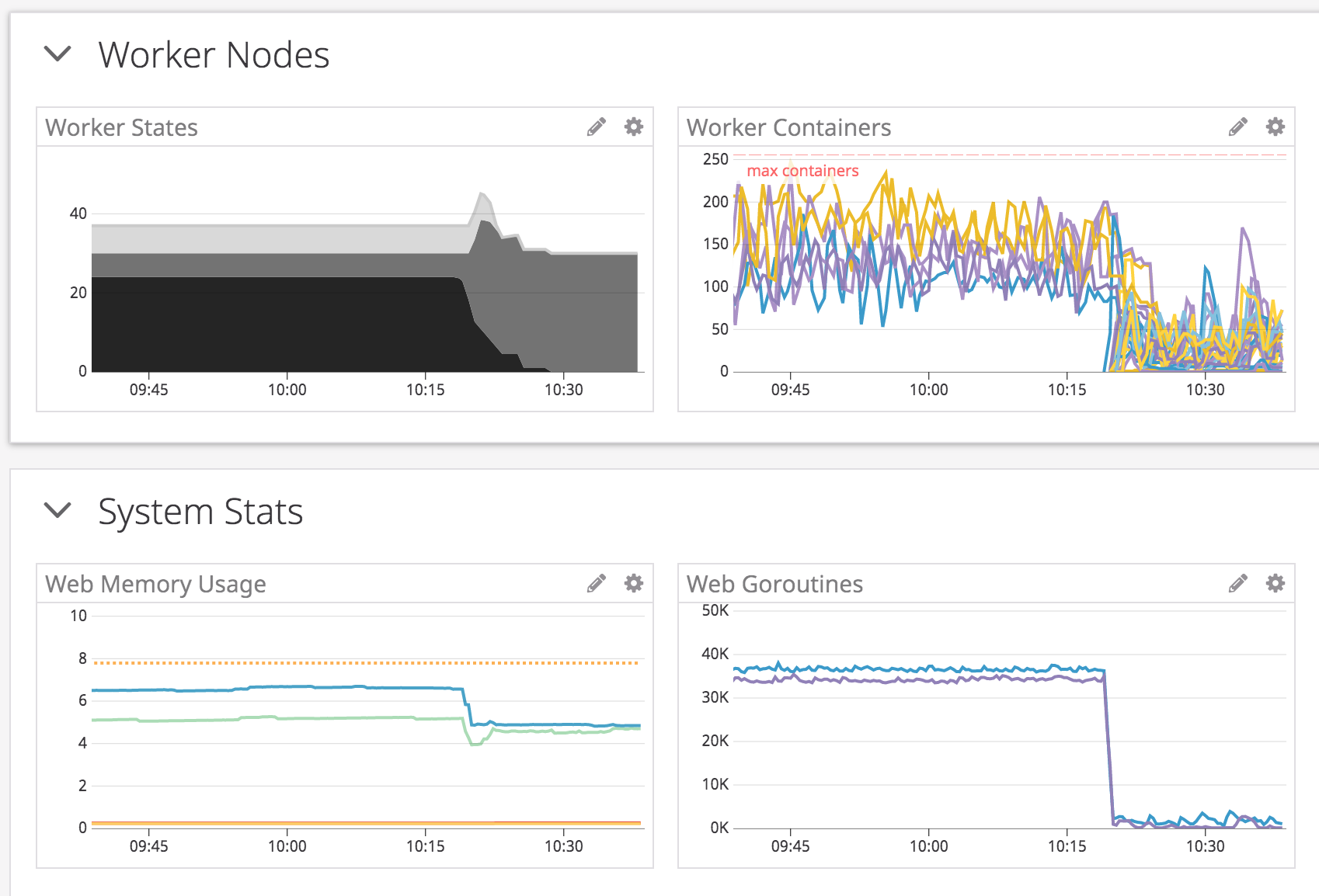
Steps to Reproduce
Not sure yet. May need to just chaos test this.
Expected Results
I would expect the worker client to notice that the connection is broken and to recover/reconnect.
Actual Results
The worker client hung forever and stopped heartbeating/registering.
Additional Context
Goroutine dumps: https://gist.github.com/vito/a53e8b484a3d254a0872ebe7f5d15773
The dumps are large; I would recommend cloning the gist instead:
$ git clone https://gist.github.com/vito/a53e8b484a3d254a0872ebe7f5d15773
Version Info
- Concourse version:
master - Deployment type (BOSH/Docker/binary): BOSH
- Infrastructure/IaaS: GCP
- Browser (if applicable): n/a
- Did this used to work? probably not
About this issue
- Original URL
- State: closed
- Created 4 years ago
- Reactions: 2
- Comments: 49 (44 by maintainers)
Commits related to this issue
- [#5082] Close ssh conn on worker when keepalive fails - Close sshClient Conn on keepalive -> SendRequest operation error - Add 5 second timeout for keepalive -> SendRequest operation Signed-off-by: ... — committed to concourse/concourse by xtreme-sameer-vohra 4 years ago
- [#5082] Close ssh conn on worker when keepalive fails - Close sshClient Conn on keepalive -> SendRequest operation error - Add 5 second timeout for keepalive -> SendRequest operation Signed-off-by: ... — committed to concourse/concourse by xtreme-sameer-vohra 4 years ago
- [#5082] Refactor keepalive into a separate func - pull out keepalive from tsa client - add test coverage for new behaviour — committed to concourse/concourse by xtreme-sameer-vohra 4 years ago
- [#5082] Refactor keepalive into a separate func - pull out keepalive from tsa client - add test coverage for new behaviour Signed-off-by: Sameer Vohra <vohra.sam@gmail.com> — committed to concourse/concourse by xtreme-sameer-vohra 4 years ago
- [#5082] add release note Signed-off-by: Sameer Vohra <vohra.sam@gmail.com> — committed to concourse/concourse by xtreme-sameer-vohra 4 years ago
- [#5082] Close ssh conn on worker when keepalive fails - Close sshClient Conn on keepalive -> SendRequest operation error - Add 5 second timeout for keepalive -> SendRequest operation Signed-off-by: ... — committed to concourse/concourse by xtreme-sameer-vohra 4 years ago
- [#5082] Refactor keepalive into a separate func - pull out keepalive from tsa client - add test coverage for new behaviour Signed-off-by: Sameer Vohra <vohra.sam@gmail.com> — committed to concourse/concourse by xtreme-sameer-vohra 4 years ago
- [#5082] add release note Signed-off-by: Sameer Vohra <vohra.sam@gmail.com> — committed to concourse/concourse by xtreme-sameer-vohra 4 years ago
- [#5082] Increase tsa/client keepalive timeout - Changed the timeout from 5s to 5m as 5s might be too aggresive for remote workers that don't have reliable connections. This timeout is to detect ... — committed to concourse/concourse by xtreme-sameer-vohra 4 years ago
- [#5082] Minor update to tsa/keepalive - move comment near applicable command Signed-off-by: Sameer Vohra <vohra.sam@gmail.com> — committed to concourse/concourse by xtreme-sameer-vohra 4 years ago
- [#5082] Close ssh conn on worker when keepalive fails - Close sshClient Conn on keepalive -> SendRequest operation error - Add 5 second timeout for keepalive -> SendRequest operation Signed-off-by: ... — committed to concourse/concourse by xtreme-sameer-vohra 4 years ago
- [#5082] Refactor keepalive into a separate func - pull out keepalive from tsa client - add test coverage for new behaviour Signed-off-by: Sameer Vohra <vohra.sam@gmail.com> — committed to concourse/concourse by xtreme-sameer-vohra 4 years ago
- [#5082] Increase tsa/client keepalive timeout - Changed the timeout from 5s to 5m as 5s might be too aggresive for remote workers that don't have reliable connections. This timeout is to detect ... — committed to concourse/concourse by xtreme-sameer-vohra 4 years ago
- [#5082] add release note Signed-off-by: Sameer Vohra <vohra.sam@gmail.com> — committed to concourse/concourse by xtreme-sameer-vohra 4 years ago
- [#5082] Close ssh conn on worker when keepalive fails - Close sshClient Conn on keepalive -> SendRequest operation error - Add 5 second timeout for keepalive -> SendRequest operation Signed-off-by: ... — committed to concourse/concourse by xtreme-sameer-vohra 4 years ago
- [#5082] Refactor keepalive into a separate func - pull out keepalive from tsa client - add test coverage for new behaviour Signed-off-by: Sameer Vohra <vohra.sam@gmail.com> — committed to concourse/concourse by xtreme-sameer-vohra 4 years ago
- [#5082] Increase tsa/client keepalive timeout - Changed the timeout from 5s to 5m as 5s might be too aggresive for remote workers that don't have reliable connections. This timeout is to detect ... — committed to concourse/concourse by xtreme-sameer-vohra 4 years ago
- [#5082] add release note Signed-off-by: Sameer Vohra <vohra.sam@gmail.com> — committed to concourse/concourse by xtreme-sameer-vohra 4 years ago
- [#5082] Close ssh conn on worker when keepalive fails - Close sshClient Conn on keepalive -> SendRequest operation error - Add 5 second timeout for keepalive -> SendRequest operation Signed-off-by: ... — committed to concourse/concourse by xtreme-sameer-vohra 4 years ago
- [#5082] Refactor keepalive into a separate func - pull out keepalive from tsa client - add test coverage for new behaviour Signed-off-by: Sameer Vohra <vohra.sam@gmail.com> — committed to concourse/concourse by xtreme-sameer-vohra 4 years ago
In light of this issue I wonder if it makes sense to start thinking about having all atc <-> worker requests happen over http, and push all the “magic” into the transport. The TSA could become a socks5 proxy. This would let us adopt a more standard approach and make things less error prone.
Deployed the patch on
5082-worker-stallonto branch release/5.8.x on thealgorithmenv around 15:45Worker running/stall state on Algorithm Environment
Sampled on worker/0, from the logs, there were a few incidences where keepalive had a 5s timeout
Looking at one occurrence of the timeout, the worker beacon process flaps before registering successfully,
Update
Looking at their logs
// DOESNT HAVE KEEPALIVE TIMEOUT
// DOESNT HAVE KEEPALIVE TIMEOUT
// DOESNT HAVE KEEPALIVE TIMEOUT
TLDR;
70% of instances had the timeout error. For these, closing the TCP conn in the keepalive section on failure would result in the worker reconnecting
For the remaining 30%, I suspect that they are stuck in
in which case wrapping the request in a select with a timeout might prevent the worker from waiting indefinitely.
Next Steps, look at their stack trace to confirm if that is indeed the case.
thanks for sharing!
I might be very wrong, but I think we shouldn’t worry much about those bridge-related messages (coming from the
wbrdg-*devices) - AFAIK those bridge devices are there just to provide the network connectivity to the containers that garden creates, which is not something thatbeaconwould be involved with 🤔(i.e., beacon and any other processes in the
host-net-namespacewould not be using the bridge devices mentioned there)update (in case @cirocosta is interested and has suggestions 😄 )
on our test environment (deployed yesterday morning), datadog showed a worker stalled out at about 12:44 AM UTC.
we jumped on the stalled worker and looked at it’s logs (specifically for the
"worker.beacon-runner.beacon.heartbeated"message), seeing them happen about every 30 seconds, except after 12:43:30, no more of those messages show up!we did notice a GIANT influx of
"baggageclaim.api.volume-server.get-volume.get-volume.volume-not-found"messages surrounding the heartbeated message.looking at dmesg, at 12:43 AM UTC we got a lot of:
anywho, we grabbed a stackdump and noticed some hanging ssh library calls
which we are currently investigating!