concourse: Lots of `unknown handle` errors
Since upgrading Concourse to 3.0.1 & now 3.1.1, we started seeing many unknown handle errors, across all pipelines, in both AWS & vSphere:
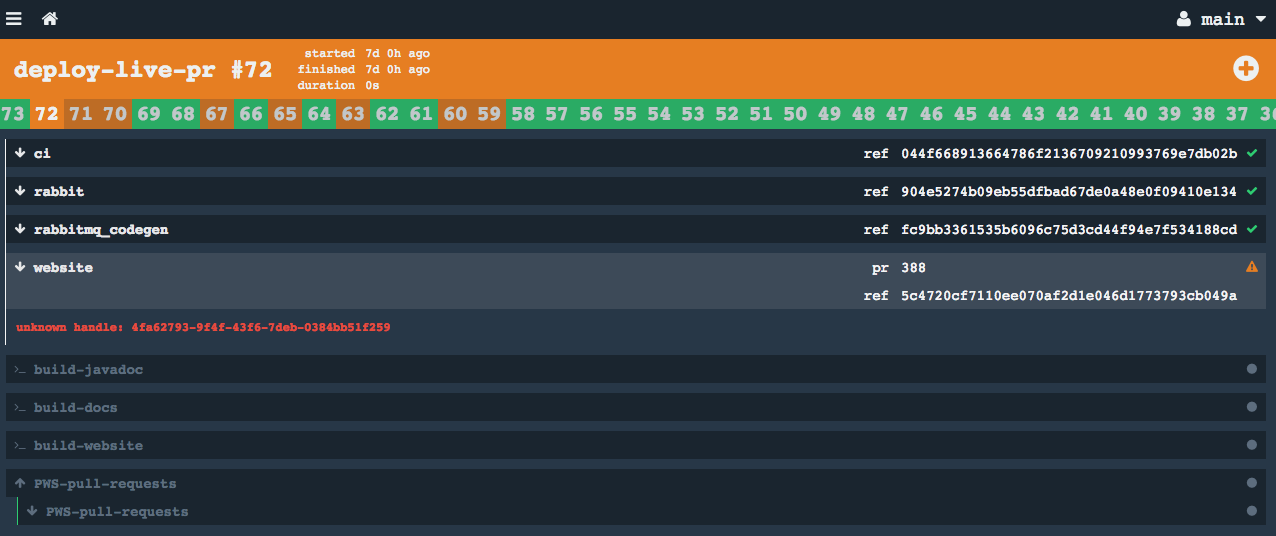
We have re-created the workers, the errors are not going away. Is this a known bug? What else can we try?
- Concourse version: 3.1.1
- Deployment type: BOSH
- Infrastructure/IaaS: same issues across 2 independent Concourse deployments, vSphere & AWS
- Did this used to work? Yes
About this issue
- Original URL
- State: closed
- Created 7 years ago
- Reactions: 6
- Comments: 37 (14 by maintainers)
I think this issue needs to be re-opened. I’m on concourse 3.4.1 running on k8s via helm chart. Regardless of how a worker process ended (SIGKILL, SIGTERM, land-worker, retire-worker), when it starts up again it always cleans up its container volumes. TSA (?) sees the worker come back under the same name and expects volumes to be there but they aren’t. I see this in the logs at startup
I have a PR to the chart that works around this issue: https://github.com/kubernetes/charts/pull/2109