concourse: Aggregate issue: builds stuck in "pending" state
There have been a few reports lately of jobs being unable to schedule. It’s been difficult for us to progress on this as we never see it ourselves and there’s generally not enough information provided to find a smoking gun. Which is no one’s fault really - we haven’t given great instructions as to what information would be valuable and how to collect it! So, that’s what this issue is for.
If you’re seeing this problem, please include a screenshot of the build preparation section of the build view.
Also answer the following:
- Are all of your workers present? (
fly workers) - Is there a
checkcontainer present for each of the inputs to your job? (fly hijack -c pipeline-name/resource-name)- Do any of the
checkcontainers have a running/opt/resource/checkprocess? If so, that may be hanging. What resource type is it?
- Do any of the
- What is the uptime of your workers and ATC?
- Are your workers registered directly (BOSH default) or forwarded through the TSA (binary default/external workers registering with BOSH deployment)?
- Which IaaS?
- If you’re on GCP, have you configured the MTU of your workers to be
1460to match the VM? If not, it defaults to1500, which would cause things to hang. - Can you reach the workers from your ATC? (
curl http://<worker ip:port>/containers) You can collect the IP + port fromfly workers -d.
- If you’re on GCP, have you configured the MTU of your workers to be
In addition to that, the most valuable information will be stack dumps of both the ATC and the TSA.
You can collect a stack dump from the ATC by running:
curl http://127.0.0.1:8079/debug/pprof/goroutine?debug=2
…and from the TSA by sending SIGQUIT and collecting the output from stderr. Note that if you’re running the binaries, the above curl command will include the TSA’s stack, so don’t worry about getting it separately. Also note that SIGQUIT will kill the TSA process, so you’ll need to bring it back after. (While you’re at it, let us know if that fixed it. 😛)
Thanks all for your patience, sorry we’re taking so long to get to the bottom of this.
About this issue
- Original URL
- State: closed
- Created 8 years ago
- Reactions: 39
- Comments: 52 (23 by maintainers)
For us this is definitely triggered by #750. Whenever we loose a worker with a deadlocked SSH connection we usually have 2-3 jobs hanging in pending with everything checked like this or this.
Each time at least one check container of the jobs inputs is missing. The only way to bring back the missing containers seems to be restarting the
webcomponent.My assumption is that the check containers that are missing where located on the missing worker with the deadlocked SSH connection on the TSA side. While resolving #750 would likely fix this issue for us I think concourse should be able to recover from this even without it. The worker with the stuck connection is long gone and so is the check container. The scheduler should in priciple be able reschedule the check container on a different worker.
I’m going to close this as we fixed the underlying root cause for the many reports we received at the time. All the recent reports appear to be a misconfiguration or some other problem with Concourse itself working as expected (build is pending and it tells you why, e.g. there are no versions, which is up to you to solve).
I ran into this same issue today (stuck on “discovering new versions”) on a bosh deployed instance of Concourse 2.7.3 and noticed 1 of the 3 workers had a very high load. I was able to resolve the problem by manually sshing into the offending worker and restarting it.
Here’s a snippet of the container load before restarting:
And an image of the worker load: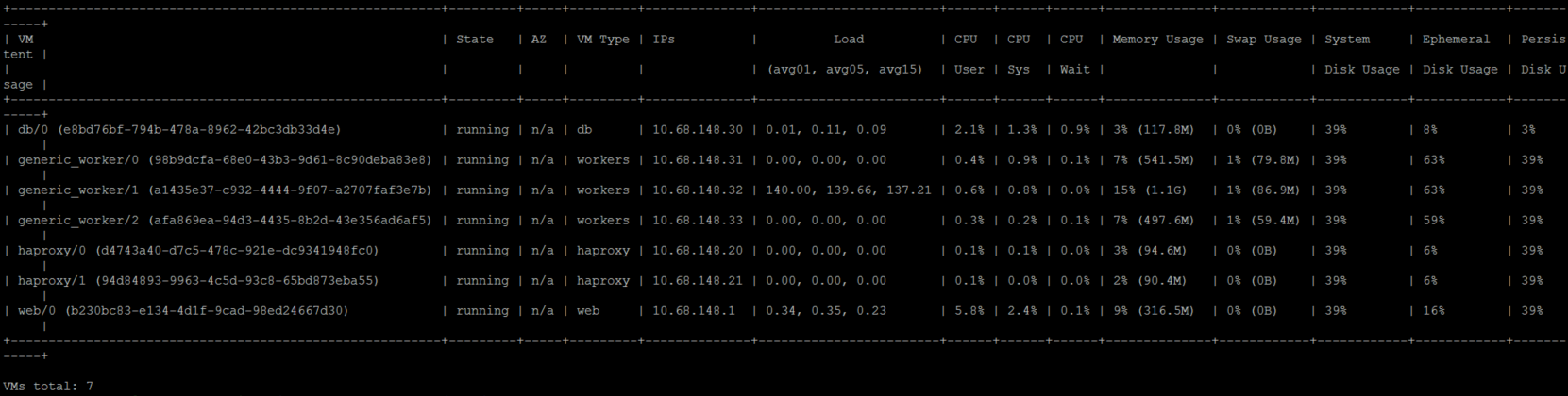
After the worker came back up it seems like the container load was properly distributed again:
Hello, Concourse folks! We’ve been seeing this one with increasing regularity since upgrading to the most recent release (but we came from 1.6 so 🤷♂️). Anyway, here are the requested diagnostics. Please let us know if we can provide any more information or help out. Thanks!
atc_stack.txt
Yes
No check containers. All containers for this job appear to be for builds other than the hanging one.
ATC: Process: 2.5h, System: 7d, OS: Ubuntu 14.04, Kernel: 3.19.0-79-generic
Workers: concourse-ui-ndc-as-b-blue: Process: 7h, System: 7d, OS: Ubuntu 14.04, Kernel: 3.19.0-79-generic concourse-worker-ndc-as-b-blue-0: Process: ~21d, System: 28d, OS: Ubuntu 14.04, Kernel: 3.19.0-79-generic concourse-worker-ndc-as-b-blue-1: Process: ~21d, System: 28d, OS: Ubuntu 14.04, Kernel: 3.19.0-79-generic
Forwarded thru the ATC (binary default)
OpenStack
Yes