concourse: 5.4.1 TCP i/o timeouts from web nodes to the concourse database
#4046 Bug Report
Since upgrading to concourse version 5.4.1. we have been seeing regular tcp i/o timeouts appearing on our build stages from the web nodes to the database. These errors seem to be intermittent and have only began to occur since upgrading from 5.2.0 to 5.4.1
our /etc/resolv.conf contains the dns server address: nameserver 10.216.0.2
and we are running the standard concourse binary 5.4.1 on Fedora28 aws ec2.
Running dns resolution tests from the server itself to the our db all run as expected so the problem appears to lie within the internal concourse dns resolutions.
Please let me know if you need any more information, thanks.
Steps to Reproduce
Running stages on concourse 5.4.1 will intermittently cause this issue and also random resources will go orange intermittently until a recheck occurs.
Expected Results
We see no TCP i/o timeouts when communicating to the db and the concourse stage or resource does not encounter an error.
Actual Results
Stage or resource returns an internal error:
dial tcp: lookup concoursedb.xx.xxxx.com on 10.216.0.2:53: read udp 10.216.0.59:45368->10.216.0.2:53: i/o timeout
Version Info
- Concourse version: 5.4.1
- Deployment type (BOSH/Docker/binary): binary
- Infrastructure/IaaS: AWS EC2
- Did this used to work? We did not receive these errors at 5.2
About this issue
- Original URL
- State: open
- Created 5 years ago
- Comments: 24 (13 by maintainers)
@vito The DNS resolutions tests we ran were just nslookups in a loop run against the dns entry, which we ran to rule out any flakiness in our own dns, we saw no resolution failures when we tried this.
Thanks for that setting - we restarted the webs with the setting enabled on the webs from 22:10 to 22:50 last night
Below shows the graph of the failures: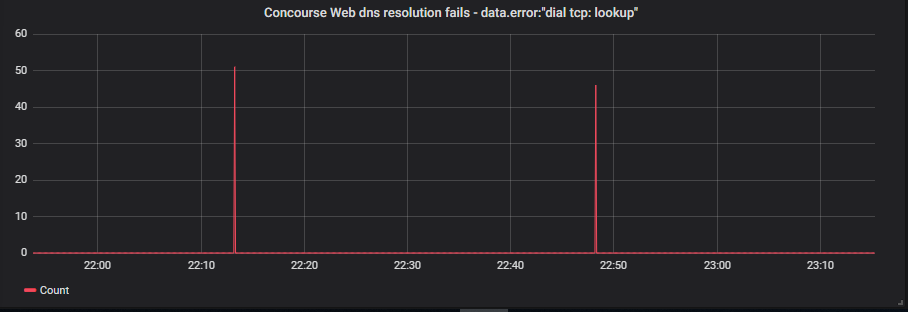
We saw a few of the same errors appear between the period, albeit not as regularly as when we had upgraded, which were appearing every few minutes after we upgraded.
Hey @clarafu no problem!
In our deployment we have:
150 pipelines:
100 of these pipelines are templated in the same way, the resources used are: 8 git resources 4 artifactory resources 1 time resource
The 8 git resources are attached to 1 job Each of the 4 artifactory resources are attached to 10 jobs The 1 time resource is attached to 40 jobs
The remaining 50 pipelines consist of: 1 metadata resource 2 git resources 1 git pull request resource
The 2 git resources are attached to 1 job each The 1 metadata resource is attached to 1 job The 1 git pull request resource is attached to 1 job
13 teams:
Containers across the workers:
Please let me know if you need to pull any specific stats on any of that, looking at the release notes for 5.3.0, I can’t see much that I think would be the issue, as @pivotal-jwinters commented I think it could be related to the streaming changes in some way. I’ll look at the feasibility of upgrading to 5.3.0 so we can narrow down the problem space, will update you with further information on that.
@clarafu We’ve upgraded to 5.3.0 and can rule this release out from having the issue. Below are the graphs for tcp i/o timeouts and db concurrent connections which show no change from the 5.2.0 release. Annotations show our deployment which upgraded to 5.3.0 so we can conclude that the issue was introduced in the 5.4.x release.