cilium: Traffic blocked when it should be allowed by netpol
Is there an existing issue for this?
- I have searched the existing issues
What happened?
I’m trying to make a connection between pods in two different namespaces. I have removed all network policies in the cluster except for one, which is in the namespace of the destination pod. The network policy is:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-ingress-to-nginx
namespace: asc-14997fb1-b878
spec:
ingress:
- from:
- ipBlock:
cidr: 0.0.0.0/0
- from:
- podSelector: {}
- from:
- namespaceSelector: {}
podSelector:
matchLabels:
app: nginx-lb
policyTypes:
- Ingress
We were testing a more restrictive policy but kept running into issues so I tried to work my way back to a fully permissive ingress policy.
From the source pod, I run this (10.0.9.158 is the IP of the destination pod)):
nc -zv 10.0.9.158 443
... time out
Full debug details in Slack thread.
Cilium Version
root@ip-192-168-8-134:/home/cilium# cilium version
Client: 1.9.9 5bcf83c 2021-07-19T16:45:00-07:00 go version go1.15.14 linux/amd64
Daemon: 1.9.9 5bcf83c 2021-07-19T16:45:00-07:00 go version go1.15.14 linux/amd64
Kernel Version
root@ip-192-168-8-134:/home/cilium# uname -a
Linux ip-192-168-8-134.ec2.internal 5.4.190-107.353.amzn2.x86_64 #1 SMP Wed Apr 27 21:16:35 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux
Kubernetes Version
❯ kubectl version
Server Version: version.Info{Major:"1", Minor:"21+", GitVersion:"v1.21.12-eks-a64ea69", GitCommit:"d4336843ba36120e9ed1491fddff5f2fec33eb77", GitTreeState:"clean", BuildDate:"2022-05-12T18:29:27Z", GoVersion:"go1.16.15", Compiler:"gc", Platform:"linux/amd64"}
Sysdump
cilium-sysdump-20220620-183155.zip
Relevant log output
# running cilium monitor on destination pod
root@ip-192-168-8-134:/home/cilium# cilium monitor --to 3042
Listening for events on 8 CPUs with 64x4096 of shared memory
Press Ctrl-C to quit
level=info msg="Initializing dissection cache..." subsys=monitor
xx drop (Policy denied) flow 0x31783178 to endpoint 3042, identity 7193->25836: 10.0.32.72:42057 -> 10.0.9.158:443 tcp SYN
# running cilium monitor on source pod
root@ip-192-168-1-26:/home/cilium# cilium monitor --from 2101
Listening for events on 16 CPUs with 64x4096 of shared memory
Press Ctrl-C to quit
level=info msg="Initializing dissection cache..." subsys=monitor
-> overlay flow 0x9d7730db identity 7193->0 state new ifindex cilium_vxlan orig-ip 0.0.0.0: 10.0.32.72:43197 -> 10.0.9.158:443 tcp SYN
-> overlay flow 0xf67c6a65 identity 7193->0 state new ifindex cilium_vxlan orig-ip 0.0.0.0: 10.0.32.72:49223 -> 10.0.11.98:53 udp
-> overlay flow 0xbd342d34 identity 7193->0 state new ifindex cilium_vxlan orig-ip 0.0.0.0: 10.0.32.72:44743 -> 10.0.29.146:53 udp
-> overlay flow 0x81e6dc56 identity 7193->0 state new ifindex cilium_vxlan orig-ip 0.0.0.0: 10.0.32.72:55869 -> 10.0.11.98:53 udp
# policy evaluation for the two identities
root@ip-192-168-1-26:/home/cilium# cilium monitor --from 2101 --to 3042
Listening for events on 16 CPUs with 64x4096 of shared memory
Press Ctrl-C to quit
^C
Received an interrupt, disconnecting from monitor...
root@ip-192-168-1-26:/home/cilium# cilium policy trace -s 2101 -d 3042 --dport 443
----------------------------------------------------------------
From: [any:2101] => To: [any:3042] Ports: [443/ANY]
Policy enforcement is disabled because no rules in the policy repository match any endpoint selector from the provided destination sets of labels.
Label verdict: allowed
Final verdict: ALLOWED
Anything else?
The source is shown as Unknown App when traffic is viewed through the hubble ui in the destination namespace
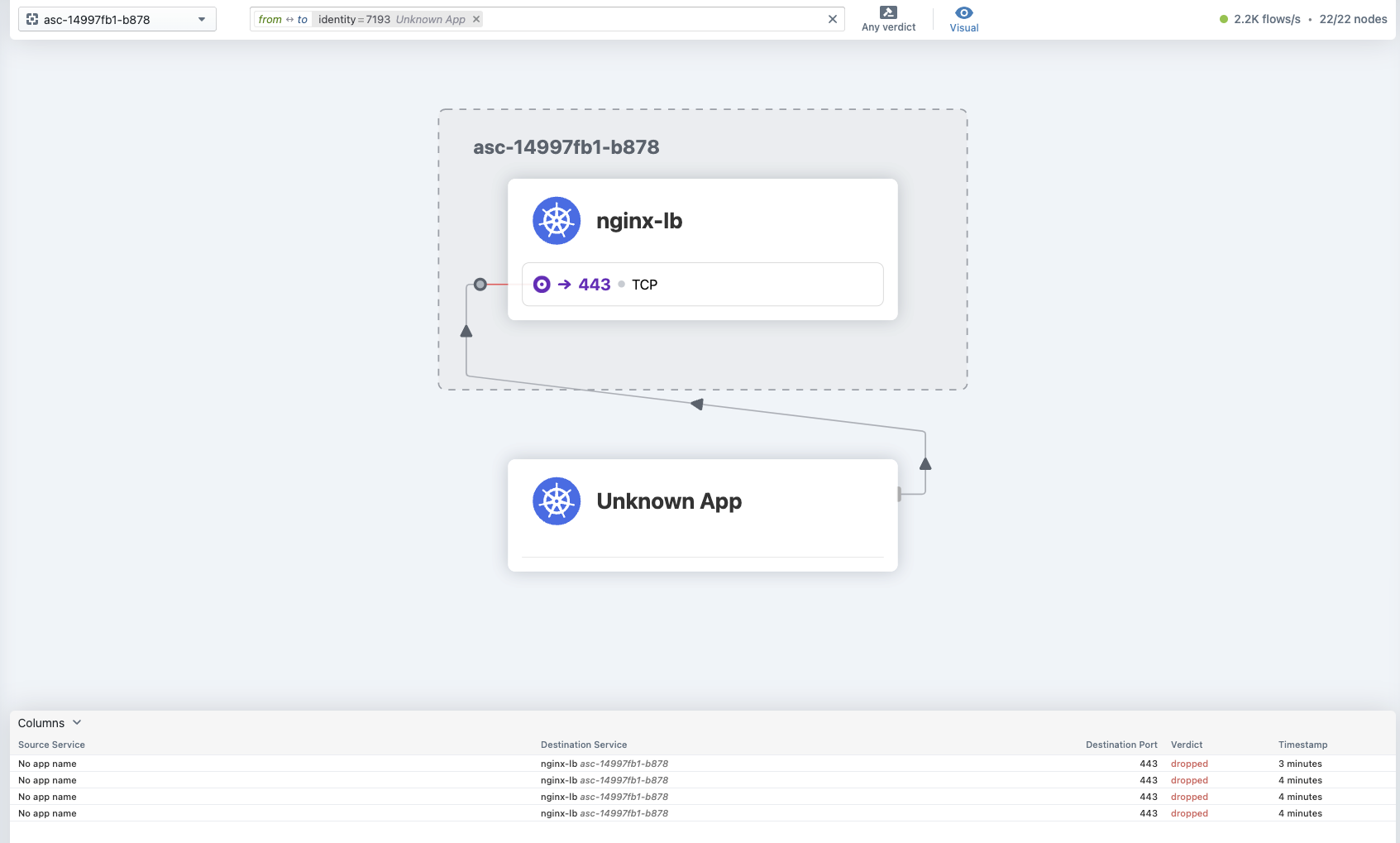 The source is correctly identified when viewed from the source namespace (I did try restarting pods to see if they were unmanaged, and that had no effect)
The source is correctly identified when viewed from the source namespace (I did try restarting pods to see if they were unmanaged, and that had no effect)
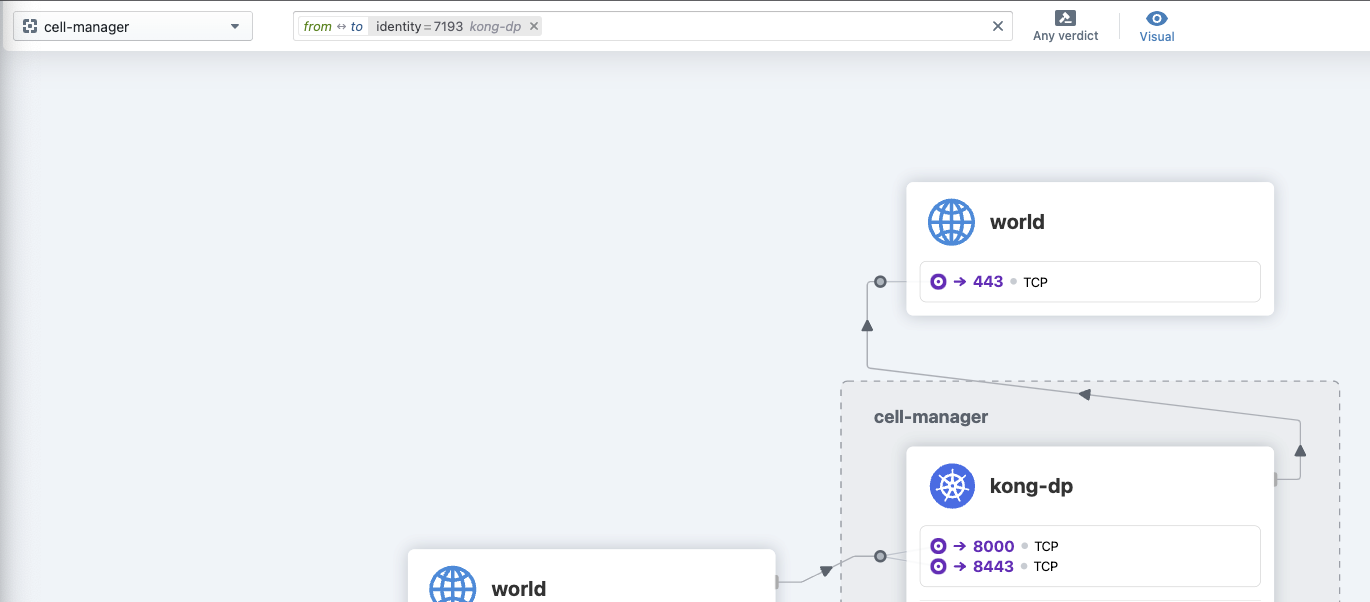
We’re running in EKS with VXLAN tunneling and cluster-pool IPAM. We also have restricted the labels for identities of our pods
# To include or exclude matched resources from cilium identity evaluation
labels: "k8s:io.kubernetes.pod.namespace k8s:k8s-app k8s:app k8s:name k8s:spark-role"
Code of Conduct
- I agree to follow this project’s Code of Conduct
About this issue
- Original URL
- State: closed
- Created 2 years ago
- Comments: 18 (18 by maintainers)
Yeah, I think we can bump to 1.9.14 no problem (at least to try). We’ve been trying to orchestrate a jump to 1.11+, but have had issues as we try to get that lined up across all clouds (currently waiting on 1.12 release plus official Azure BYOCNI support before re-attempting). Not sure if I’ll get to this today, but should be able to this week
Okay, so I’ve got to apologize because I’m afraid this is going to remain a mystery. In my investigations earlier I found that the other cluster we had which was identically configured to this one (same config, same workload profiles, everything), was not experiencing the same problems of endpoints updating.
In an attempt to get this issue addressed I redeployed cilium with
clean-cilium-state: "true"and then rolled nodes to try and force recovery, but found that the same issue still persisted.Finally, in order to get past this, I replaced the k8s cluster, ran a full deploy or all resources, and I’m not seeing the issue in the new cluster at all.
So apologies that I can’t shed more light on the issue that occurred here, because I would love to be able to come out of this issue with confidence that the problem was identified and we could figure out how to prevent it going forward, but we are at this point unblocked on our network policy development.
Thanks so much for the help 🙏 If this does pop back up I’ll re-open the issue so we can figure it out.
Workload pods. I actually didn’t get all the way through, the command failed partway through the roll referencing too many open connections. Currently I’m trying to recover the cluster because when I attempted to roll nodes as a follow-up, nothing is able to rejoin (unclear why)