cilium: Memory leak with FQDN policies
Bug report
General Information
- Cilium version (run
cilium version)
Client: 1.9.5 079bdaf 2021-03-10T13:12:19-08:00 go version go1.15.8 linux/amd64
Daemon: 1.9.5 079bdaf 2021-03-10T13:12:19-08:00 go version go1.15.8 linux/amd6
- Kernel version (run
uname -a)
Linux 5.8.0-40-lowlatency #45~20.04.1-Ubuntu SMP PREEMPT Fri Jan 15 12:34:56 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux
- Orchestration system version in use (e.g.
kubectl version, …)
v1.20.4+k3s1
- Generate and upload a system zip: cilium-sysdump-20210525-150354.zip
Description
One pod has memory leak. It happened a few days ago with another node(pod), restart pod had help
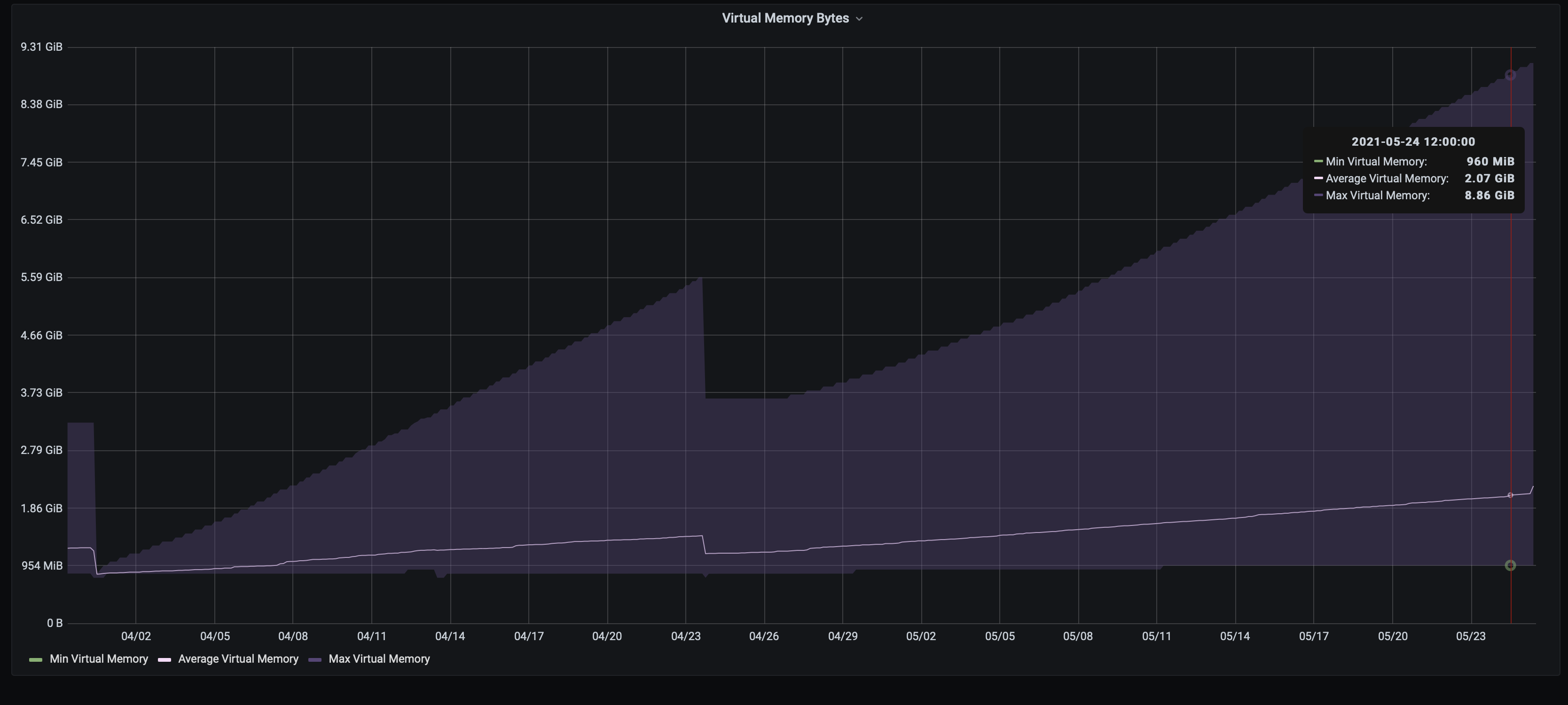
About this issue
- Original URL
- State: closed
- Created 3 years ago
- Reactions: 1
- Comments: 33 (32 by maintainers)
Yes, and coredns-nodecache with local-redirect
and
application CNP
Also, application uses s3 and service with exteranalName
i see, time to time but i think it’s ok
@yuriydzobak can you check with 1.10.2 to see if the issue still persists?
Let’s wait until #16236 is also fixed then
@aanm seems, the bug exists in 1.9.8
I updated сшдшгь to version 1.9.8 on two clusters, I think we need to wait a couple of days