microk8s: microk8s crashes with "FAIL: Service snap.microk8s.daemon-apiserver is not running"
Hello,
I have installed microk8s 3 node cluster, all works great for a a couple of days but then it crashes for no evident reason to apiserver FAILed.
Below is microk8s inspect output and attached tarball
inspection-report-20200925_103006.tar.gz
Inspecting Certificates
Inspecting services
Service snap.microk8s.daemon-cluster-agent is running
Service snap.microk8s.daemon-containerd is running
**FAIL: Service snap.microk8s.daemon-apiserver is not running**
For more details look at: sudo journalctl -u snap.microk8s.daemon-apiserver
Service snap.microk8s.daemon-apiserver-kicker is running
Service snap.microk8s.daemon-control-plane-kicker is running
Service snap.microk8s.daemon-proxy is running
Service snap.microk8s.daemon-kubelet is running
Service snap.microk8s.daemon-scheduler is running
Service snap.microk8s.daemon-controller-manager is running
Copy service arguments to the final report tarball
Inspecting AppArmor configuration
Gathering system information
Copy processes list to the final report tarball
Copy snap list to the final report tarball
Copy VM name (or none) to the final report tarball
Copy disk usage information to the final report tarball
Copy memory usage information to the final report tarball
Copy server uptime to the final report tarball
Copy current linux distribution to the final report tarball
Copy openSSL information to the final report tarball
Copy network configuration to the final report tarball
Inspecting kubernetes cluster
Inspect kubernetes cluster
Building the report tarball
Report tarball is at /var/snap/microk8s/1719/inspection-report-20200925_103006.tar.gz
This is not first time it has happened. My attempt to deploy a small prod cluster based on microk8s is hindered because of this problem in test environment
About this issue
- Original URL
- State: closed
- Created 4 years ago
- Reactions: 14
- Comments: 151 (25 by maintainers)
Hi all,
We will be doing a release to the stable channels (latest/stable and 1.19/stable) this week.
This release will be addressing the segmentation faults and data corruption issues.
We are still investigating the memory leak.
Thank you for your patience.
The PRs with the fixes on the dqlite layer are in [1, 2]. Also, in the latest/edge, latest/beta and latest/candidate you will find a setup where Kubernetes services start as go routines instead of systemd processes resulting in further memory footprint gains.
The dqlite fixes are being backported to 1.19 and 1.20 and are already on the candidate channels. In the next couple of days these fixes will make it to the stable channels.
[1] https://github.com/canonical/raft/pull/168 [2] https://github.com/canonical/raft/pull/167
I don’t understand. K3s gave up on dqlite for exactly these reasons. Do you have any hope of making this work? If yes, why?
Can I do HA with etcd instead of dqlite?
Can I use an external SQL database (eg RDS)?
@VaticanUK just an FYI the team is looking at this. I’m running a development branch right now on my cluster and have given access to a couple of the devs to one of the machines to see it. No root cause yet, but wanted to let you know it’s under investigation.
Updated to
latest/edgeand will monitor. The refresh went well. My cluster had fallen apart again over the weekend on 1724, I’ve now refreshed all nodes to 1730 and will be sure to provide any feedback here and on #1578 - thanks again @freeekanayaka and @ktsakalozos for all of your hard work on this, dqlite is a great alternative to etcd (especially on smaller systems) and I can see the stability of the technology growing before my eyes 😃@raohammad, @bclermont, @VaticanUK we are actively working on the issue. Here is a summary of what we have done so far.
Thank you @balchua, @freeekanayaka, @devec0 for your efforts.
The above fixes/enhancements are available from the
latest/edgeand1.19/edgechannels. Any feedback you could give us on those channels would be much appreciated.Hi, I’m having the same issue, 4-nodes.
Master node:
Nodes: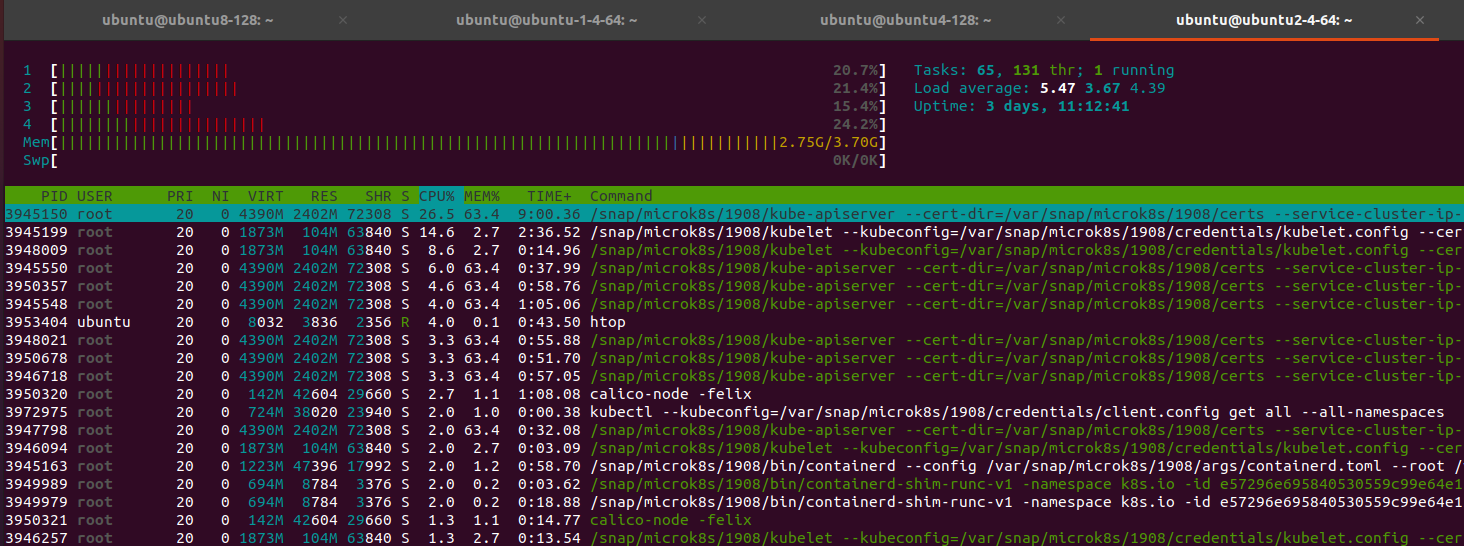
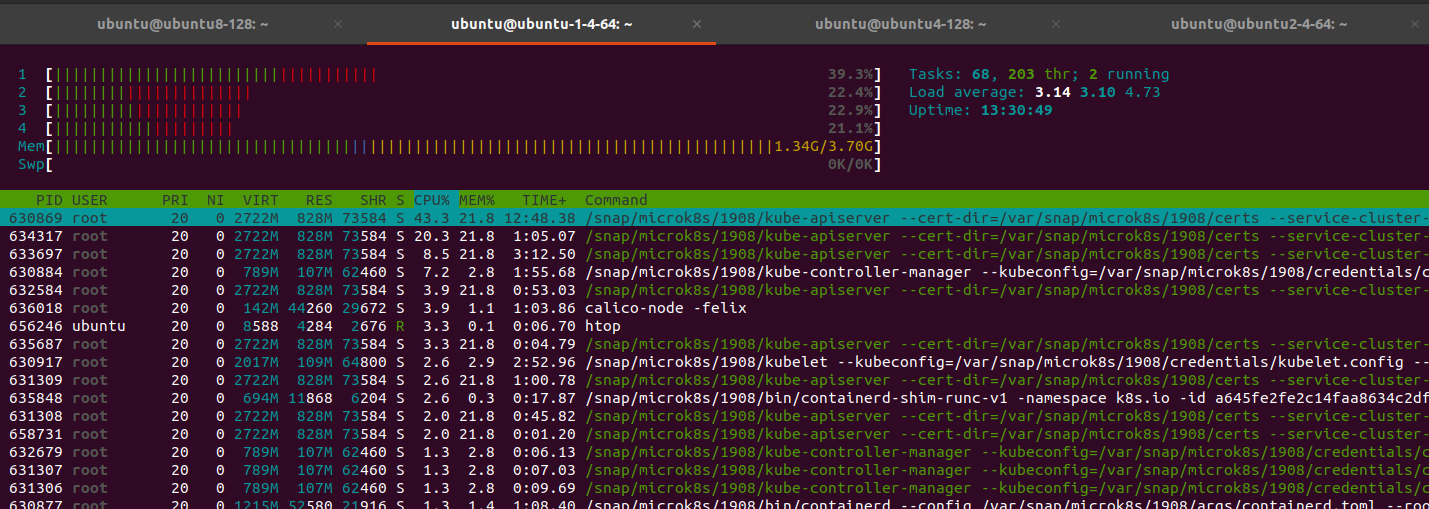
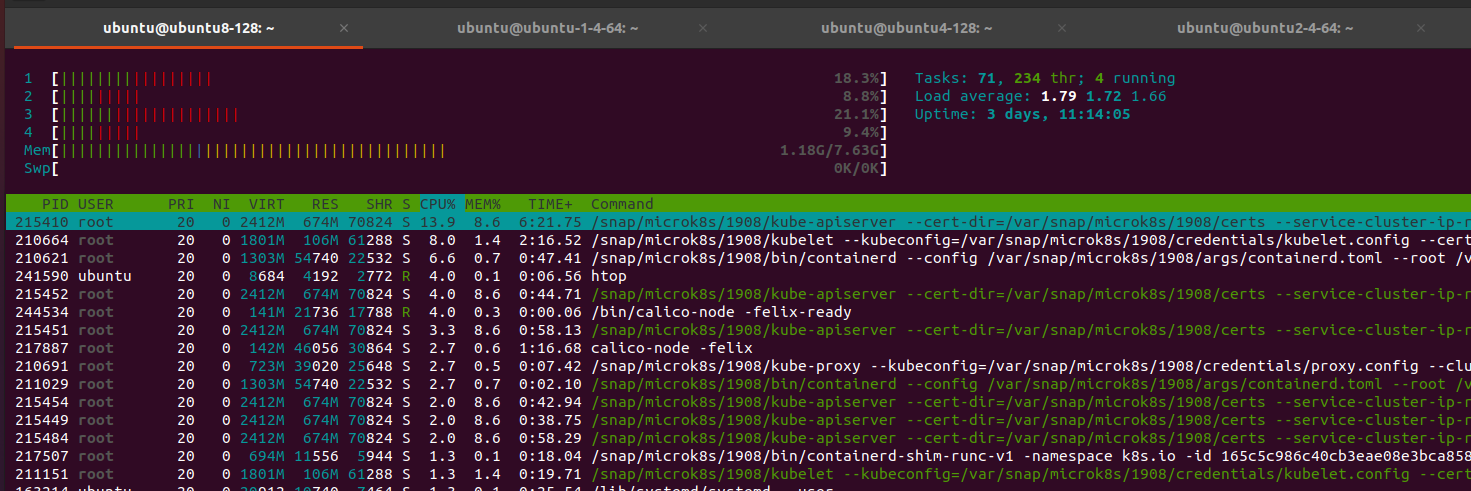
After restart back to stable for 4-5 hour later I have 100% mem on master. Error view: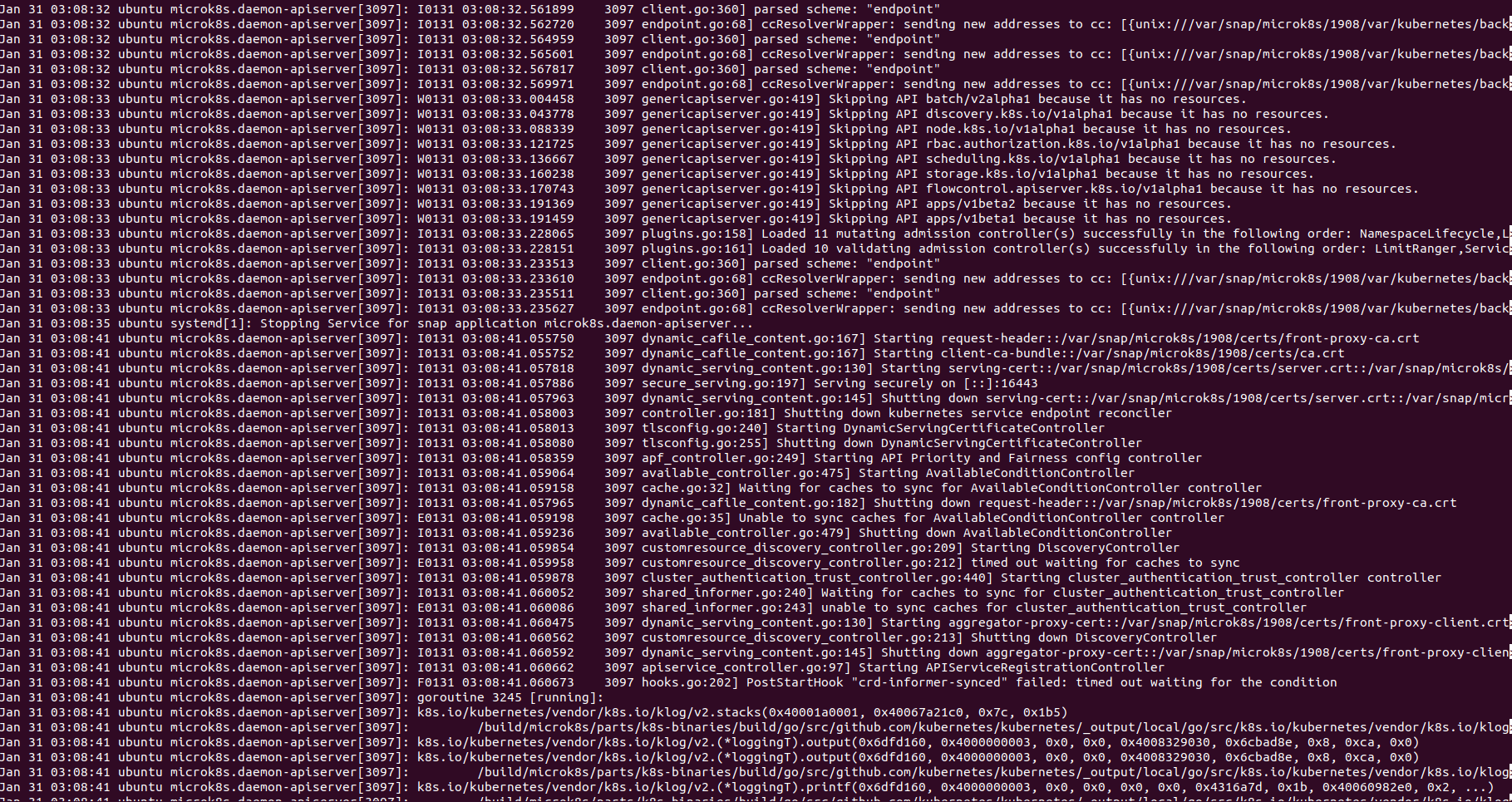
There is a line: Jan 31 03:08:41 ubuntu systemd[1]: snap.microk8s.daemon-apiserver.service: Failed with result 'exit-code
On client login: I don’t deploy anything is clean, how I can resolve this problem ?
I don’t deploy anything is clean, how I can resolve this problem ?
Hi,
Yesterday i gave the
latest/edgechannel a go. The setup is:24 hours later, this the memory usage.
This is the cpu usage
You can see that the memory after the
0600time, the memory utilization remains constant.I purposely set the
MemoryMaxin the systemd apiservice. Like this:sudo systemctl set-property snap.microk8s.daemon-apiserver MemoryMax=1.2GYou will also notice prior to
0600the utilization of the node178.128.24.144(the yellow or orange) is around the1.2Ghigh mark. The apiserver on the node178.128.24.144(the yellow or orange) was killed by the kernel at around0616, probably due to OOM. After this time, i think the node178.128.26.36(the blue coloe) took over as the leader.I checked the apiserver logs in the node
178.128.24.144and noticed that at the time im setting theMemoryMaxproperty it complained that it was not able to set the property because it was busy.Perhaps I should have restarted MicroK8s after setting the memory property. The cluster is still responsive, none of the pods were evicted or restarted. My guess is that Go is being more aggressive in garbage collecting the memory. But I am in no way an expert in Go. 😃
So far I have not seen the cluster using memory hovering around
1.1G. From the looks of it, it does seem stable. The last time i tested it (i.e. without theMemoryMaxproperty set), the memory is growing beyond1.2G. The workqueue latency is swinging wildly beyond1secsometimes up to10sec.These are the pods running in the cluster, not too much.
Perhaps its still too early to tell. I will continue to keep an eye on the cluster. For those who may way to try this one out. Set the
MemoryMaxproperty in apiservice service like thissudo systemctl set-property snap.microk8s.daemon-apiserver MemoryMax=1.2Gand restart the apiservice.Please note that this is done on a fresh cluster.
Rather than changing multiple things at once, I’ll upgrade today, then turn swap on tomorrow or Thurs (depending on how things go 😃)
@VaticanUK yes, normally you do not have swap and k8s will try to maximize resource utilization on all nodes. However, I would like to remove this potential OOM instability factor so we focus on the DB stability.
Also please refresh to the latest snap revision (
sudo snap refresh microk8s --channel=latest/edge) we pushed some more fixes yesterday. Thank you.Same problem here, I investigated a bit, by running
sudo /usr/bin/snap run microk8s.daemon-apiservermanually. here is the output:So, api-server is segfaulting. That is very annoying as the binary is striped and I can’t get a golang stacktrace.
@raohammad please run that command, maybe you have the same problem
I’m still hitting the segfaulting issue (and memory leaking) on a regular basis (at least once a week) on 1.19/edge. It’s usually a single node that starts segfaulting, and needs recovery using the process described in https://discuss.kubernetes.io/t/recovery-of-ha-microk8s-clusters/12931.
I’ve got a single instance running on 1.19/candidate which has been running for 7 days without any problems. 1.19/stable seemed to last for about 3 days before apiserver would crash and not start again.
+1 on this issue, unable to turn up the apiserver with segmentation fault.
I think we are firm on root cause and logs, Can some one help look into commits that could have caused this issue.
On Wed, Feb 3, 2021 at 1:04 PM mloebl notifications@github.com wrote:
– -Warm Regards Sudhir Vissa
I’m having the same issue, it starts with one node but then all follows and apiserver is no longer available at all…
Hi balchua,
Is this issue fixed in sudo snap install microk8s --classic --channel=1.19/edge? I have set it to sudo systemctl set-property snap.microk8s.daemon-apiserver MemoryMax=2.0G By when, we can expect the stable release?
Regards, sans
Hi @nemo83 - I’m also running my cluster on arm64 - I have found that generally the class of your SD card (I’m actually using a SSD) will make a huge difference running k8s on ARM SoCs either way - but are you using the ha-cluster addon? If so, you might also want to point your metrics (prometheus) at the /metrics endpoint on port 16443 (this is the apiserver) as it produces many useful internal k8s metrics which are useful for tracking down the remaining issues. You’ll need to get a token as this endpoint requires auth, but there’s plenty of guides online for getting the admin’s default bearer token.
You can then add a job such as the one below -
I’ve been a little late to weigh in on this one, given I have been seeing similar issues for quite some time, and failures similar to this were what caused my cluster to fail to the point where not functional members were remaining, leading me to have to manually recover the members, in #1578.
I can reliably take a fresh microk8s cluster deployed (in my most recent test) on
1764(latest/edge) and within 24-48 hours the whole cluster will self-implode due to the apiserver no longer being able to interact with dqlite. I think this fits the pattern people are seeing on 1.19 onward, where using theha-clusteraddon can lead to member servers dropping out of the cluster, and in my case, that continues to happen until there are not enough members for dqlite to happily continue. I’ve found that even losing one dqlite member in my 3 node cluster will often be enough to get the apiserver to start failing, with numerouscontext cancelledtimeouts, and the entire control plane becomes unresponsive as a result.I have been monitoring apiserver metrics and will often see the apiserver stop returning metrics as soon as I start seeing the timeouts appear in the logs, and this is normally directly following a message such as
failed to create dqlite connection: no available dqlite leader server found. The majority of these messages refer to the 10s timeout for many operations, I’m not sure if this is related to the raft channel used to propagate dqlite messages, but generally 10s seems to be the magic number in a lot of places in the code, and I often see specific calls likeAPIServiceRegistrationController, andautoregister- but the specific call doesn’t seem to matter, mostly that the call touches the datastore, which is backed by dqlite, so I suspect these timeouts are more of a symptom rather than a cause.Work queue latency is the source of this information in the following Grafana snapshot. These metrics are scraped directly from
/metricson the API server port from each microk8s cluster member, using the bearer token for the admin account. https://snapshot.raintank.io/dashboard/snapshot/MJ5Y4mBkMHcTVB9YPOwwDjwh8MToNUbCFrom my continued observations and monitoring, it seems that the dqlite cluster membership fails, and that then leads to the kubernetes control plane cluster failing as the timeouts writing to the data store seem to not cause a full failure of the apiserver. This then, in many cases, leads to some kind of memory leak, with memory steadily growing if this is left in a failed state for long enough - so could also explain the memory usage folks have been seeing with the
ha-clusteraddon when they’ve had a node go sideways.I’ve attached an inspection report from a node that failed under similar circumstances just now on
latest/edge. I hope it’s useful. inspection-report-20201027_121843.tar.gzI’d love to see a good way to query dqlite health directly so I could add it to prometheus - if there is an endpoint somehwere I could query information about dqlite cluster membership and transactions I’d be happy to share that data over time, as well.
hey all, just thought i’d check in and see how you’re getting on with this?
We want to avoid cases where the node runs out of memory and the kernel is forced to kill processes. Adding swap is not recommended, but if the served workloads bring the nodes close to the limit you would better have some swap to handle instability. More information on this is here https://discuss.kubernetes.io/t/swap-off-why-is-it-necessary/6879
@shadowmodder just for your info when you disable
ha-clusteryou are basically using etcd and flannel and not dqlite and calico. That’s fine too. 😊@ktsakalozos @freeekanayaka Hi I am new to microk8s…facing the same issue from morning which mention above i have attached my tarball
from master:
from node :
inspection-report-20201006_105830.tar.gz
that looks very familiar
Here is the syslog from one of the nodes that was in the failed setup (Tuesday is my hostname and username):
Oct 6 08:57:23 tuesday microk8s.daemon-containerd[81301]: time=“2020-10-06T08:57:23.419511640Z” level=error msg=“Failed to load cni configuration” error=“cni config load failed: no network config found in /etc/cni/net.d: cni plugin not initialized: failed to load cni config” Oct 6 08:57:23 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:23.419616 81329 kubelet.go:2190] Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:Network plugin returns error: cni plugin not initialized Oct 6 08:57:23 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:23.479633 81329 kubelet.go:2270] node “tuesday” not found Oct 6 08:57:23 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:23.579958 81329 kubelet.go:2270] node “tuesday” not found Oct 6 08:57:23 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:23.680297 81329 kubelet.go:2270] node “tuesday” not found Oct 6 08:57:23 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:23.780605 81329 kubelet.go:2270] node “tuesday” not found Oct 6 08:57:23 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:23.881062 81329 kubelet.go:2270] node “tuesday” not found Oct 6 08:57:23 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:23.981405 81329 kubelet.go:2270] node “tuesday” not found Oct 6 08:57:24 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:24.081711 81329 kubelet.go:2270] node “tuesday” not found Oct 6 08:57:24 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:24.182158 81329 kubelet.go:2270] node “tuesday” not found Oct 6 08:57:24 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:24.282455 81329 kubelet.go:2270] node “tuesday” not found Oct 6 08:57:24 tuesday microk8s.daemon-kubelet[81329]: I1006 08:57:24.381812 81329 kubelet_node_status.go:294] Setting node annotation to enable volume controller attach/detach Oct 6 08:57:24 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:24.382711 81329 kubelet.go:2270] node “tuesday” not found Oct 6 08:57:24 tuesday microk8s.daemon-kubelet[81329]: I1006 08:57:24.417513 81329 kubelet_node_status.go:70] Attempting to register node tuesday Oct 6 08:57:24 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:24.417901 81329 kubelet_node_status.go:92] Unable to register node “tuesday” with API server: Post https://127.0.0.1:16443/api/v1/nodes: dial tcp 127.0.0.1:16443: connect: connection refused Oct 6 08:57:24 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:24.483049 81329 kubelet.go:2270] node “tuesday” not found Oct 6 08:57:24 tuesday microk8s.daemon-controller-manager[81217]: E1006 08:57:24.532553 81217 leaderelection.go:320] error retrieving resource lock kube-system/kube-controller-manager: Get https://127.0.0.1:16443/api/v1/namespaces/kube-system/endpoints/kube-controller-manager?timeout=10s: dial tcp 127.0.0.1:16443: connect: connection refused Oct 6 08:57:24 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:24.583338 81329 kubelet.go:2270] node “tuesday” not found Oct 6 08:57:24 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:24.683691 81329 kubelet.go:2270] node “tuesday” not found
Oct 6 08:57:24 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:24.784015 81329 kubelet.go:2270] node “tuesday” not found Oct 6 08:57:24 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:24.884349 81329 kubelet.go:2270] node “tuesday” not found Oct 6 08:57:24 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:24.984671 81329 kubelet.go:2270] node “tuesday” not found Oct 6 08:57:25 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:25.084984 81329 kubelet.go:2270] node “tuesday” not found Oct 6 08:57:25 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:25.185285 81329 kubelet.go:2270] node “tuesday” not found Oct 6 08:57:25 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:25.285751 81329 kubelet.go:2270] node “tuesday” not found Oct 6 08:57:25 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:25.386054 81329 kubelet.go:2270] node “tuesday” not found Oct 6 08:57:25 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:25.486397 81329 kubelet.go:2270] node “tuesday” not found Oct 6 08:57:25 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:25.586733 81329 kubelet.go:2270] node “tuesday” not found Oct 6 08:57:25 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:25.687020 81329 kubelet.go:2270] node “tuesday” not found Oct 6 08:57:25 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:25.787334 81329 kubelet.go:2270] node “tuesday” not found Oct 6 08:57:25 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:25.887688 81329 kubelet.go:2270] node “tuesday” not found Oct 6 08:57:25 tuesday microk8s.daemon-kubelet[81329]: E1006 08:57:25.894913 81329 reflector.go:178] k8s.io/kubernetes/pkg/kubelet/kubelet.go:517: Failed to list *v1.Service: Get https://127.0.0.1:16443/api/v1/services?limit=500&resourceVersion=0: dial tcp 127.0.0.1:16443: connect: connection refused
Should be
/var/snap/microk8s/current/var/kubernetes/backendfor reference.nm, found them 😃
Here is the tarball from my second name - looks like it took about 2.5 hours to complete:
inspection-report-20201004_004907.tar.gz
the command still hasn’t completed on my third node so i’ve kicked it off again
So far I have:
At this point inspect is not reporting the api server is down, however I’m still on the 1710 revision, and the node doesn’t actually come online.
I have a copy of the bad /backend folder, but I’ve kind of run out of ideas at this point. If there’s more I can do point me in the right direction. I’m willing to leave this node down/out for a little while to see if we can trace down what’s going on.
I think it’d be useful to build libdqlite and libraft by passing
--debugto./configure, as discussed with @ktsakalozos. That might provide a bit more info about the crash.I’m building k8s 1.19.2 API server from source to get the stack trace