beast: read_some with transfer encoding: chunked returns 5 zero bytes after reading chunk length
Hello
Version of Beast
BOOST_BEAST_VERSION 322
Steps necessary to reproduce the problem
Read SSL response with transfer-encoding: chunked
I’m using this type:
using SSLStream = boost::asio::ssl::stream<asio::ip::tcp::socket>;
After connecting and sending the request I begin reading the response using a parser.
First I read the header: http::read_header(mStream, mMultiBuff, mParser);
Then I’m detecting a response with no boundary I read everything else in a loop: For multi-part I have another reading code.
data is std::vector<char>
while (!mParser.is_done())
{
auto& body = mParser.get().body();
body.data = data.data() + bytesRead;
body.size = data.size();
body.more = false;
auto bytes = http::read_some(mStream, mMultiBuff, mParser, error);
if (isChunk && bytes < chunkThreshholdBytes)
{
bytes = 0;
}
bytesRead += bytes;
}
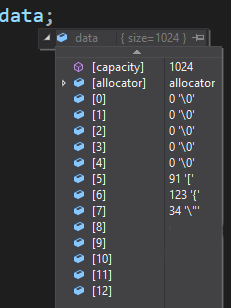
read_some returns 5 bytes and my data vector (Which is std::vector<char>) isn’t populated with the length of the chunk, in the picture below we can see it’s d8d - 3469 bytes.
A. Possibly I’d like the chunk size to be able to resize the vector only once.
B. I want to be able to skip these 5 bytes, what happens is bytes set to 5- but data has 5 zero bytes in the beginning.
Inside boost reading code, the buffer looks like this:
 Red is the end of the headers.
Cyan is the size of the chunked body.
Green is the body.
Red is the end of the headers.
Cyan is the size of the chunked body.
Green is the body.
My vector looks like so after reading twice:
All relevant compiler information
Using MSVC - VS 2019, Version: 16.11.7 OpenSSL 1.1.1
My reading code is a bit messy so I wonder if I did something wrong. Is this the expected behavior?
Thanks.
About this issue
- Original URL
- State: closed
- Created 2 years ago
- Comments: 24 (2 by maintainers)
You NEVER know the Content-Length ahead of time, because HTTP messages containing both chunked Transfer-Encoding AND a Content-Length field are invalid. Beast’s parser produces an error on such messages.
That was one confusing code. I got it working after I removed my previous
GrowBuffermethod which tried to replicate. I’ve put a more simple version - to be precise like your code - and it works 😃Still the only thing that bothers me is when I read Content-Length I don’t want to
resizemy string every reading. This slows down the process, so I optimize it by thepreparemethod. Do I still need to callcommit?Thanks for all your help!
Late addition: it might be cleaner to use the documented modification of
body.sizeinstead ofbody.data:The effect is documented to be the same: https://godbolt.org/z/x4E4Tc5xG
I did not since I still have no clue what that tries to achieve. Are you somehow manually trying to interpret the chunked encoding? That’s what Beast is for.
@vinniefalco
That’s exactly what my third version demonstrates (well, except consuming the dynamic buffer, since we don’t know the consumer)
You could use
read_someand the dynamic buffer body, and justconsumeeach part when you are done with it, this will use less memory.Great. I’ll have a look as soon as I can. Reproducing the sample inline because paste bins tend to expire:
[snip broken code no longer relevant]