tvm: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Problem Statement
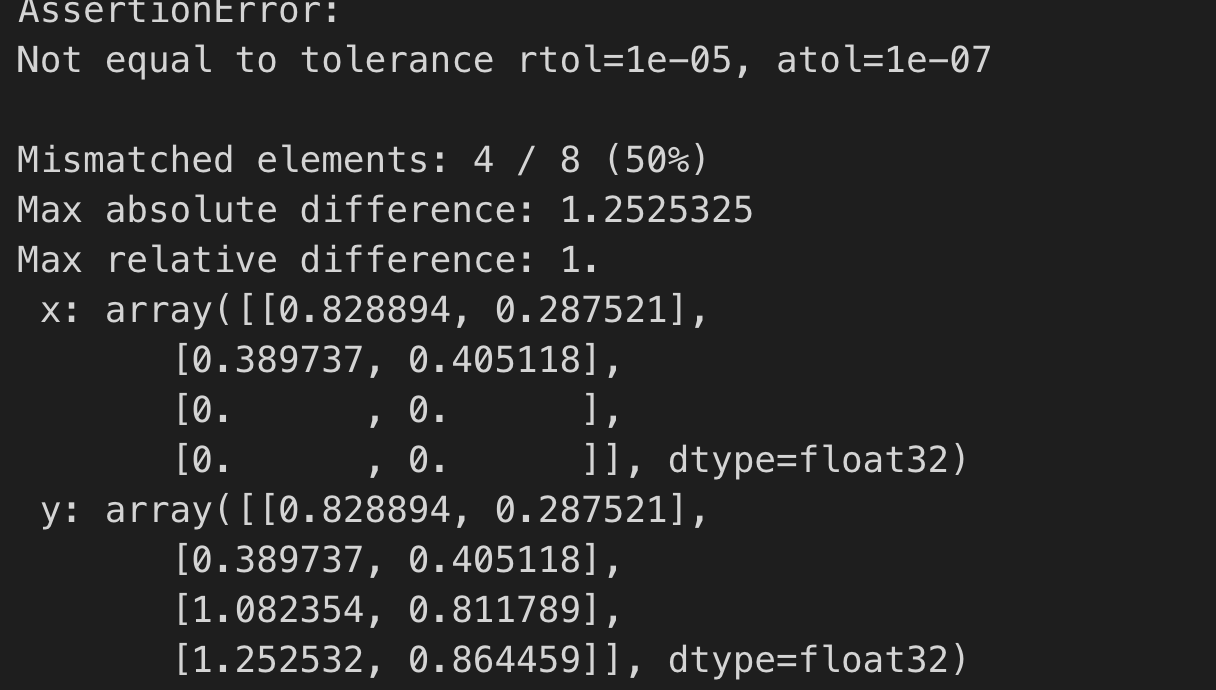
This bug was encountered when I was trying to use external BLAS library as “micro-kernel” to optimize the Matmul op. Basically I was just following the TVM Tensorize Tutorial, and did a little modification by replacing the tvm.tir.call_extern('int32', 'gemv_update' with tvm.tir.call_packed("tvm.contrib.cblas.matmul"..., which of course because I’m trying to leverage existing blas library to do tensorize. The code works pretty well, until I add a s[C].parallel(xo), It crashed:
Environment
- CPU: CacadeLake-X
- OS: CentOS 7.0
- TVM: 0.7
- LLVM: 9.0
Code to reproduce this bug
import tvm
from tvm import te
import numpy as np
import sys
from tvm import testing
# Fail case:
M, K, N = 4, 4, 2
A = te.placeholder((M, K), name='A')
B = te.placeholder((K, N), name='B')
k = te.reduce_axis((0, K), name='k')
C = te.compute((M, N), lambda i, j: te.sum(A[i, k] * B[k, j], axis=k), name='C')
s = te.create_schedule(C.op)
bn = 2
xo, yo, xi, yi = s[C].tile(C.op.axis[0], C.op.axis[1], bn, bn)
s[C].reorder(xo, yo, xi, yi, k)
s[C].parallel(xo)
def intrin_libxsmm(m, k, n):
a = te.placeholder((m, k), name='a')
b = te.placeholder((k, n), name='b')
k = te.reduce_axis((0, k), name='k')
c = te.compute((m, n), lambda i, j: te.sum(a[i, k] * b[k, j], axis=k), name='c')
a_buffer = tvm.tir.decl_buffer(a.shape, a.dtype, name='a_buffer', offset_factor=1, strides=[te.var('s1'), 1])
b_buffer = tvm.tir.decl_buffer(b.shape, b.dtype, name='b_buffer', offset_factor=1, strides=[te.var('s2'), 1])
c_buffer = tvm.tir.decl_buffer(c.shape, c.dtype, name='c_buffer', offset_factor=1, strides=[te.var('s3'), 1])
def intrin_func(ins, outs):
ib = tvm.tir.ir_builder.create()
ib.emit(
tvm.tir.call_packed(
"tvm.contrib.cblas.matmul", ins[0], ins[1], outs[0], False, False, 1.0, 0.0
)
)
return ib.get()
return te.decl_tensor_intrin(c.op, intrin_func, binds={a: a_buffer, b: b_buffer, c: c_buffer})
micro_kernel = intrin_libxsmm(bn, K, bn)
s[C].tensorize(xi, micro_kernel)
ctx = tvm.cpu(0)
func = tvm.build(s, [A, B, C], target='llvm')
a = tvm.nd.array(np.random.uniform(size=(M, K)).astype(A.dtype), ctx)
b = tvm.nd.array(np.random.uniform(size=(K, N)).astype(B.dtype), ctx)
c = tvm.nd.array(np.zeros((M, N), dtype=C.dtype), ctx)
func(a, b, c)
tvm.testing.assert_allclose(c.asnumpy(), np.dot(a.asnumpy(), b.asnumpy()), rtol=1e-5)About this issue
- Original URL
- State: closed
- Created 3 years ago
- Comments: 31 (31 by maintainers)
Commits related to this issue
- [Fix] Fix the race condition issue of packed func. (#7246). 1. Always allocate stacks next to packed func call, rather than a global shared stack. 2. Add a testcase to reproduce the bug. — committed to zhuwenxi/tvm by deleted user 3 years ago
- Code refactor of bug fix for issue #7246: 1. Keep most of the original logic of the max_shape, and max_arg_stack logic; 2. Introduce a AllocaScope stack frame data structure that contains the necessar... — committed to zhuwenxi/tvm by deleted user 3 years ago
- [BugFix] Fix the race condition issue of packed func. (#7246). (#7619) Co-authored-by: wenxizhu <wenixzhu@tencent.com> — committed to apache/tvm by zhuwenxi 3 years ago
- [BugFix] Fix the race condition issue of packed func. (#7246). (#7619) Co-authored-by: wenxizhu <wenixzhu@tencent.com> — committed to trevor-m/tvm by zhuwenxi 3 years ago
- [BugFix] Fix the race condition issue of packed func. (#7246). (#7619) Co-authored-by: wenxizhu <wenixzhu@tencent.com> — committed to trevor-m/tvm by zhuwenxi 3 years ago
- [BugFix] Fix the race condition issue of packed func. (#7246). (#7619) Co-authored-by: wenxizhu <wenixzhu@tencent.com> — committed to trevor-m/tvm by zhuwenxi 3 years ago
- [BugFix] Fix the race condition issue of packed func. (#7246). (#7619) Co-authored-by: wenxizhu <wenixzhu@tencent.com> — committed to neo-ai/tvm by zhuwenxi 3 years ago
I spent some time to implement the fix, and it totally works in LLVM backend. Here is my implementation details:
tvm_stack_allocaalways emitted next to the “tvm_call_packed”, rather than the beginning of the PrimFunc;WithFunctionEntryto codegen for tvm_stack_alloca(): https://github.com/apache/tvm/blob/main/src/target/llvm/codegen_cpu.cc#L885The LLVM IR generated before & after the fix attached here, for comparison.
Before: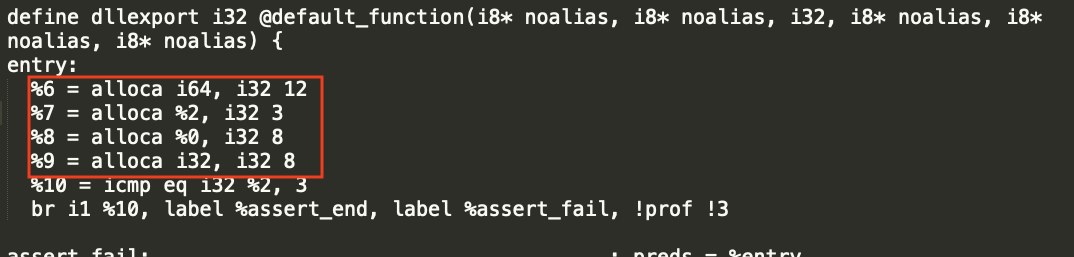
After: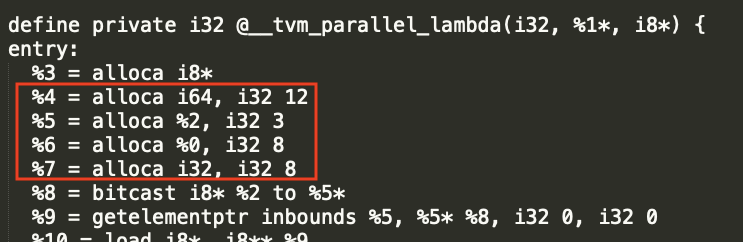
I haven’t looked into C and StackVM backend, would you prefer me to throw a PR to review this LLVM side fix first? @tqchen
I’m happy to contribute this patch 😃 I will start from writing a prototype to do POC, and I’ll keep you posted.