pulsar: Catastrophic frequent random subscription freezes, especially on high-traffic topics.
Describe the bug Topics randomly freeze, causing catastrophic topic outages on a weekly (or more frequent) basis. This has been an issue as long as my team has used Pulsar, and it’s been communicated to a number of folks on the Pulsar PMC committee.
(I thought an issue was already created for this bug, but I couldn’t find it anywhere.)
To Reproduce We have not figured out how to reproduce the issue. It’s random (seems to be non-deterministic) and doesn’t seem to have any clues in the broker logs.
Expected behavior Topics should never just randomly stop working to where the only resolution is restarting the problem broker.
Steps to Diagnose and Temporarily Resolve
 Step 2: Check the rate out on the topic. (click on the topic in the dashboard, or do a stats on the topic and look at the “msgRateOut”)
Step 2: Check the rate out on the topic. (click on the topic in the dashboard, or do a stats on the topic and look at the “msgRateOut”)
If the rate out is 0 this is likely a frozen topic, but to verify do the following:
In the pulsar dashboard, click on the broker that topic is living on. If you see that there are multiple topic that have a rate out of 0, then proceed to the next step, if not it could potentially be another issue. Investigate further.


Step 3: Stop the broker on the server that the topic is living on. pulsar-broker stop .
Step 4: Wait for the backlog to be consumed and all the functions to be rescheduled. (typically wait for about 5-10 mins)
Environment:
Docker on bare metal running: `apachepulsar/pulsar-all:2.4.0`
on CentOS.
Brokers are the function workers.
This has been an issue with previous versions of Pulsar as well.
Additional context
Problem was MUCH worse with Pulsar 2.4.2, so our team needed to roll back to 2.4.0 (which has the problem, but it’s less frequent). This is preventing the team from progressing in the use of Pulsar, and it’s causing SLA problems with those who use our service.
About this issue
- Original URL
- State: closed
- Created 4 years ago
- Comments: 94 (83 by maintainers)
Commits related to this issue
- #9986 - Created workaround for #6054 — committed to devinbost/pulsar by deleted user 3 years ago
- Created workaround for #6054 and implemented architecture for default function producer values. — committed to devinbost/pulsar by deleted user 3 years ago
- Issue #6054 - Adding more logging when sending permits to broker — committed to devinbost/pulsar by deleted user 3 years ago
- Issue #6054 - Adding more logging when sending permits to broker — committed to devinbost/pulsar by deleted user 3 years ago
- Issue #6054 - Improved performance of logging — committed to devinbost/pulsar by deleted user 3 years ago
- Issue #6054 - Adding more permits debug statements to better see changes to permits — committed to devinbost/pulsar by deleted user 3 years ago
- Issue #6054 - Fixed style issues — committed to devinbost/pulsar by deleted user 3 years ago
- Issue #6054 - Fixed more style issues — committed to devinbost/pulsar by deleted user 3 years ago
- Issue #6054 - Remove artifact from copy and paste — committed to devinbost/pulsar by deleted user 3 years ago
- Issue #6054 - Remove artifact from copy and paste — committed to devinbost/pulsar by deleted user 3 years ago
- Issue #6054 - Adding more permits debug statements to better see changes to permits — committed to devinbost/pulsar by deleted user 3 years ago
- Issue #6054 - Adding more permits debug statements to better see changes to permits (#10217) — committed to apache/pulsar by devinbost 3 years ago
- Issue #6054 - Adding more permits debug statements to better see changes to permits (#10217) — committed to apache/pulsar by devinbost 3 years ago
- Issue #6054 - Preventing extra dispatch when entries will make permits a negative value — committed to devinbost/pulsar by deleted user 3 years ago
- Issue #6054 - Fix infinite loop in asyncCreateLedger when ledger create succeeded despite timeout — committed to devinbost/pulsar by deleted user 3 years ago
- Issue #6054 - Fix infinite loop in asyncCreateLedger when ledger create succeeded despite timeout — committed to devinbost/pulsar by deleted user 3 years ago
This bug has been resolved in DataStax Luna Streaming 2.7.2_1.1.21
We (StreamNative) have been helping folks from Tencent at developing a feature called ReadOnly brokers. It allows a topic can have multiple owners (one writeable owner and multiple readonly owners). It has been running on production for a while. They will contribute it back soon.
@skyrocknroll @marcioapm All required fixes are included in Apache Pulsar 2.7.4 and 2.8.2 versions.
I found a huge clue on this issue (in Pulsar 2.6.3). Several hours after we collected those stats, I got a heap dump on the function that was consuming from the dead topic, and its permits were actually positive. (In the heap dump of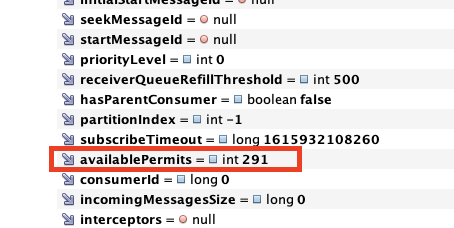
third-function, inConsumerImpl, the function’savailablePermitswere positive.)This morning, I checked the stats on the
third-topicagain, and the permits had gone back to positive, and its backlogs were all gone.I found in the Pulsar source code that the consumer is supposed to periodically report to the broker what its available permits are (https://github.com/apache/pulsar/blob/master/pulsar-client/src/main/java/org/apache/pulsar/client/impl/ConsumerImpl.java#L112). It seems like the function must have eventually reported its permits to the broker, which brought the permits back into the positive, so the broker resumed pushing messages to the consumer. It’s possible that it locked up again after accumulating more negative permits and then cleared after a while and repeated this process until eventually all the messages cleared the backlog.
To confirm if the issue is just the broker getting out of sync with the consumer’s availablePermits, I need to reproduce the issue again and get a function heapdump when the topic permits are negative to verify if the function permits are positive at that point or if they’re also negative. If they’re also negative, then there’s something happening in the consumer that’s somehow making them positive after a while.
It looks like this PR may fix some of the permit issues: https://github.com/apache/pulsar/pull/7266 However, we’re not doing any explicit batching with the Pulsar functions. Do they batch by default? Maybe @jerrypeng or someone can provide some guidance here. If there isn’t batching taking place, then that PR won’t completely solve this issue because these findings would suggest that there’s another reason (other than incorrect batch reporting of permits, as mentioned in that PR) that the permits are getting out of sync between the broker and function.
@devinbost There is a fix https://github.com/apache/pulsar/pull/5894 for broker stop dispatch messages and it was released in 2.5.0.
FWIW, @devinbost I am suspicious of the netty version in the 2.4.X stream. There is a know memory usage issue (https://github.com/netty/netty/issues/8814) in the 4.1.32 version of netty that is used in the stream. When I was testing, I would see issues like you are describing. Then I patched in the latest version of netty, and things seemed better. I have been running with a patched 2.4.2 for a while and have not seen any issues. You may be experiencing something completely different, but it might be worth trying 2.4.2 + latest netty.