lucene: CompiledAutomaton.getCommonSuffix can be extraordinarily slow, even with default maxDeterminizedStates limit [LUCENE-9981]
We have a maxDeterminizedStates = 10000 limit designed to keep regexp-type queries from blowing up.
But we have an adversary that will run for 268s on my laptop before hitting exception, first reported here: https://github.com/opensearch-project/OpenSearch/issues/687
When I run the test and jstack the threads, this what I see:
"TEST-TestOpensearch687.testInteresting-seed#[4B9C20A027A9850C]" `#15` prio=5 os_prio=0 cpu=56960.04ms elapsed=57.49s tid=0x00007fff7006ca80 nid=0x231c8 runnable [0x00007fff8b7f0000]
java.lang.Thread.State: RUNNABLE
at org.apache.lucene.util.automaton.SortedIntSet.decr(SortedIntSet.java:106)
at org.apache.lucene.util.automaton.Operations.determinize(Operations.java:769)
at org.apache.lucene.util.automaton.Operations.getCommonSuffixBytesRef(Operations.java:1155)
at org.apache.lucene.util.automaton.CompiledAutomaton.<init>(CompiledAutomaton.java:247)
at org.apache.lucene.search.AutomatonQuery.<init>(AutomatonQuery.java:104)
at org.apache.lucene.search.AutomatonQuery.<init>(AutomatonQuery.java:82)
at org.apache.lucene.search.RegexpQuery.<init>(RegexpQuery.java:138)
at org.apache.lucene.search.RegexpQuery.<init>(RegexpQuery.java:114)
at org.apache.lucene.search.RegexpQuery.<init>(RegexpQuery.java:72)
at org.apache.lucene.search.RegexpQuery.<init>(RegexpQuery.java:62)
at org.apache.lucene.TestOpensearch687.testInteresting(TestOpensearch687.java:42)
This is really sad, as getCommonSuffixBytesRef() is only supposed to be an “up-front” optimization to make the actual subsequent terms-intensive part of the query faster. But it makes the whole query run for nearly 5 minutes before it does anything.
So I definitely think we should improve getCommonSuffixBytesRef to be more “best-effort”. For example, it can reduce the lower bound to 1000 and catch the exception like such:
try {
// this is slow, and just an opto anyway, so don't burn cycles on it for some crazy worst-case.
// if we don't set this common suffix, the query will just run a bit slower, that's all.
int limit = Math.min(1000, maxDeterminizedStates);
BytesRef suffix = Operations.getCommonSuffixBytesRef(binary, limit);
... (setting commonSuffixRef)
} catch (TooComplexTooDeterminizeException notWorthIt) {
commonSuffixRef = null;
}
Another, maybe simpler option, is to just check that input state/transitions accounts don’t exceed some low limit N.
Basically this opto is geared at stuff like leading wildcard query of “*foo”. By computing that the common suffix is “foo” we can spend less CPU in the terms dictionary because we can first do a memcmp before having to run data thru any finite state machine. It’s really a microopt and we shouldn’t be spending whole seconds of cpu on it, ever.
But I still don’t quite understand how the current limits are giving the behavior today, maybe there is a bigger issue and I don’t want to shove something under the rug.
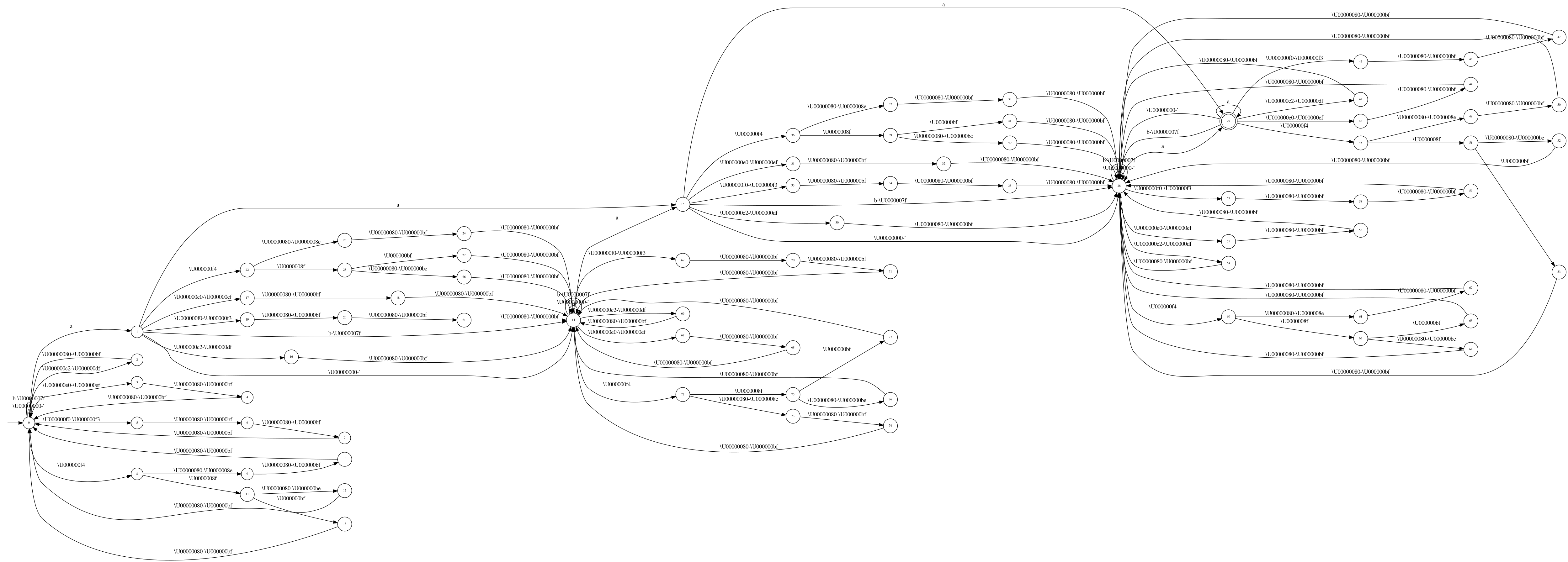
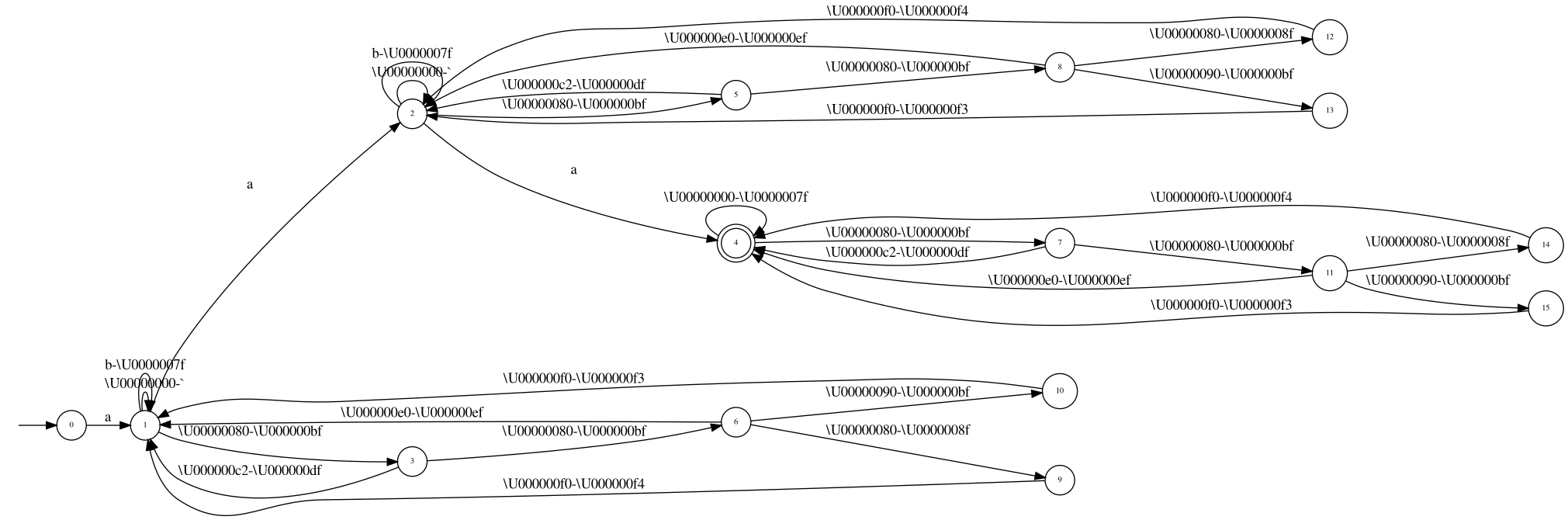
Migrated from LUCENE-9981 by Robert Muir (@rmuir), 1 vote, resolved Jun 22 2021 Attachments: LUCENE-9981_nfaprefix.patch, LUCENE-9981_test.patch, LUCENE-9981.patch (versions: 5), three-repeats.png, three-repeats-reverse-det.png
{kind=link}
{kind=link}
About this issue
- Original URL
- State: closed
- Created 3 years ago
- Comments: 53 (2 by maintainers)
Hi @mikemccand , originally I was thinking about people that are using Lucene (indirectly) without authentication/usage limitations. It’s totally possible: in maven central, there are a lot of projects that are using this as a dependency (maybe there are also used elsewhere etc…) and they are not aware of this problem (that is solved): just warning them about this “security issue” by creating a CVE could have been a good idea (about availability issue). But according to previous comments, there is no direct denial of service from a Lucene point of view but slow queries.
Thanks a lot @mikemccand for your time.